本文内容来自微软美国总部机器学习科学家彭河森博士的共享,并由彭河森博士亲身收拾成文。
正如程序言语相同,深度学习开源结构相同各有好坏和适用的场景,那么 AI 从业者该怎样有针对性地挑选这些渠道来玩转深度学习?
本期特邀了先后在谷歌、亚马逊、微软供职的机器学习科学家彭河森博士为咱们叙述《MXNet火了,AI从业者该怎样挑选深度学习开源结构》。彭河森博士亲眼见证并深化参加了这三家巨子布局深度学习的进程。
嘉宾介绍
彭河森,埃默里大学核算学博士。现担任微软美国总部的机器学习科学家、微软必应广告部运用资深研讨员,当时首要研讨方向是自然言语处理和机器学习在广告和引荐体系中的运用。此外,彭河森博士曾是亚马逊最年青的机器学习研讨员,之前还供职于谷歌计量经济学部和中科院。

深度学习是一个十分抢手的范畴,现在市面上也有许多十分优异的渠道,信任咱们在入行之初都在想,这么多渠道应该怎样挑选?
我先提两点,或许是一般测评没有考虑到的东西:
一个是图画核算和符号求导,这是深度学习一个十分有意思且十分重要的副产物。
另一个是深度学习结构的可触碰深度,这点直接关系到深度学习体系的开展未来和用户的自由度。
这两点关于初学者和从业人员都十分重要,我在后面详细叙述。
首要要祝贺 MXNet 近来获得了亚马逊的背书,MXNet 渠道本身十分优异,具有许多优异的性质:例如多节点模型练习,现在是我知道最全面的多言语支撑。此外,也有评测说 MXNet 功用方面能够高出同行渠道许多,咱们将会在后面的评论中说到。现在进入正题,咱们该怎样挑选深度学习开源渠道,参阅规范应该是什么样的?
一、深度学习开源渠道的 5 大参阅规范
今日首要讨论的渠道(或许软件)包含:Caffe, Torch, MXNet, CNTK, Theano, TensorFlow, Keras。
怎样挑选一个深度学习渠道?我总结出了下面的这些考量规范。因人而异,因项目而异。或许你是做图画处理,也或许是自然言语处理,或是数量金融,依据你不同的需求,对渠道做出的挑选或许会不同。
规范1:与现有编程渠道、技能整合的难易程度
无论是学术研讨仍是工程开发,在上马深度学习课题之前一般都已堆集不少开发经历和资源。或许你最喜爱的编程言语现已建立,或许你的数据现已以必定的办法贮存结束,或许对模型的要求(如推迟等)也不相同。规范1 考量的是深度学习渠道与现有资源整合的难易程度。这儿咱们将答复下面的问题:
是否需求专门为此学习一种新言语?
是否能与当时已有的编程言语结合?
规范 2: 和相关机器学习、数据处理生态整合的严密程度
咱们做深度学习研讨最终总离不开各种数据处理、可视化、核算揣度等软件包。这儿咱们要答复问题:
建模之前,是否具有便利的数据预处理东西?当然大多渠道都本身带了图画、文本等预处理东西。
建模之后,是否具有便利的东西进行成果剖析,例如可视化、核算揣度、数据剖析?
规范 3:经过此渠道做深度学习之外,还能做什么?
上面咱们说到的不少渠道是专门为深度学习研讨和运用进行开发的,不少渠道对分布式核算、GPU 等构架都有强壮的优化,能否用这些渠道/软件做其他作业?
比方有些深度学习软件是能够用来求解二次型优化;有些深度学习渠道很简略被扩展,被运用在强化学习的运用中。哪些渠道具有这样的特色?
这个问题能够涉及到如今深度学习渠道的一个方面,便是图画核算和自动化求导。
规范 4:对数据量、硬件的要求和支撑
当然,深度学习在不同运用场景的数据量是不相同的,这也就导致咱们或许需求考虑分布式核算、多 GPU 核算的问题。例如,对核算机图画处理研讨的人员往往需求将图画文件和核算使命分部到多台核算机节点上进行履行。
当下每个深度学习渠道都在快速开展,每个渠道对分布式核算等场景的支撑也在不断演进。今日说到的部分内容或许在几个月后就不再适用。
规范 5:深度学习渠道的老练程度
老练程度的考量是一个比较片面的考量要素,我个人考量的要素包含:社区的活泼程度;是否简略和开发人员进行沟通;当时运用的气势。
讲了 5 个参阅规范后,接下来咱们用上面的这些规范对各个深度学习渠道进行点评:
二、深度学习渠道点评
评判1:与现有编程渠道、技能整合的难易程度
规范1 考量的是深度学习渠道与现有资源整合的难易程度。这儿咱们将答复下面的问题:是否需求专门为此学习一种新言语?是否能与当时已有的编程言语结合?
这一个问题的干货在下面这个表格。这儿咱们依照每个深度学习渠道的底层言语和用户言语进行总结,能够得到下表。
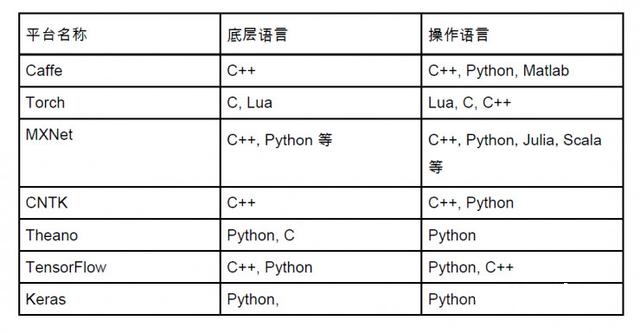
其间 Keras 经过 Theano, TensorFlow 作为底层进行建模。
咱们能够看到这样的趋势:
深度学习底层言语多是 C++ / C 这样能够到达高运转功率的言语。
操作言语往往会切近实践,咱们大致能够判定 Python 是未来深度学习的操作渠道言语,微软在 CNTK 2.0 参加了对 Python 的支撑。
当然,还有不少渠道能够经过脚本的办法装备网络并且练习模型。
从格局上来说,Python 作为深度学习建模的根本言语是能够确认的。假如你最喜爱编程言语是 Python,祝贺您,大多数渠道都能够和你的技能无缝联接。假如是 Java 也不必忧虑,不少渠道也具有 Java 支撑,Deeplearning4J 仍是一个原生的 Java 深度学习渠道。
规范 2: 和相关机器学习、数据处理生态整合的严密程度
这儿咱们要提一下现在首要的数据处理东西,比较全面的数据剖析东西包含 R 及其相关生态,Python 及其相关生态,小众一点的还包含 Julia 及其相关生态。
完结深度学习建模等使命之后,和生态的整合也尤为重要。
咱们能够发现,上面和 Python, R, 整合较为严密,这儿 Keras 生态(TensorFlow, Theano), CNTK, MXNet, Caffe 等占有许多优势。
一起 Caffe 具有许多图画处理包,对数据调查也具有十分大的优势。
规范 3:经过此渠道做深度学习之外,还能做什么?
下图是本次公开课的中心:

其实深度学习渠道在发明和设计时的偏重点有所不同,咱们依照功用能够将深度学习渠道分为上面六个方面:
CPU+GPU操控,通讯:这一个最低的层次是深度学习核算的根本层面。
内存、变量管理层:这一层包含关于详细单个中心变量的界说,如界说向量、矩阵,进行内存空间分配。
根本运算层:这一层首要包含加减乘除、正弦、余弦函数,最大最小值等根本管用运算操作。
根本简略函数:
○ 包含各种激起函数(acTIvaTIon funcTIon),例如 sigmoid, ReLU 等。
○ 一起也包含求导模块
神经网络根本模块,包含 Dense Layer, ConvoluTIon Layer (卷积层), LSTM 等常用模块。
最终一层是对一切神经网络模块的整合以及优化求解。
许多机器学习渠道在功用偏重上是不相同的,我将他们分成了四大类:
1. 第一类是以 Caffe, Torch, MXNet, CNTK 为主的深度学习功用性渠道。这类渠道供给了十分齐备的根本模块,能够让开发人员快速创立深度神经网络模型并且开端练习,能够处理如今深度学习中的大多数问题。可是这些模块很少将底层运算功用直接露出给用户。
2. 第二类是以 Keras 为主的深度学习抽象化渠道。Keras 本身并不具有底层运算和谐的才干,Keras 依托于 TensorFlow 或许 Theano 进行底层运算,而 Keras 本身供给神经网络模块抽象化和练习中的流程优化。能够让用户享用快速建模的一起,具有很便利的二次开发才干,参加本身喜爱的模块。
3. 第三类是 TensorFlow。TensorFlow 吸取了已有渠道的利益,既能让用户触碰底层数据,又具有现成的神经网络模块,能够让用户十分快速的完结建模。TensorFlow 是十分优异的跨界渠道。
4. 第四类是 Theano, Theano 是深度学习界最早的渠道软件,专心底层根本的运算。
所以对渠道挑选能够对照上图依照自己的需求选用:
假如使命方针十分确认,只需求短平快出成果,那么第 1 类渠道会合适你。
假如您需求进行一些底层开发,又不想失掉现有模块的便利,那么第 2、3 类渠道会合适你。
假如你有核算、核管用学等布景,想运用已有东西进行一些核算性开发,那么第 3, 4 类会合适你。
这儿我介绍下深度学习的一些副产品,其间一个比较重要的功用便是符号求导。
图核算和符号求导:深度学习对开源社区的巨大奉献
咱们或许会有疑问:我能练习出来深度学习模型就蛮好的了,为什么需求触摸底层呢?
这儿我先介绍下深度学习的一些副产品,其间一个比较重要的功用便是符号求导。符号求导英文是 Symbolic Differentiation,现在有许多有关的文献和教程能够运用。
符号求导是什么意思?
曾经咱们做机器学习等研讨,假如要求导往往需求手动把方针函数的导数求出来。最近一些深度学习东西,如 Theano, 推出了自动化符号求导功用,这大大减少了开发人员的作业量。
当然,商业软件如 MatLab, Mathematica 在多年前就已具有符号核算的功用,但鉴于其商业软件的约束,符号核算并没有在机器学习运用中被许多选用。
深度学习由于其网络的杂乱性,有必要选用符号求导的办法才干处理方针函数过于杂乱的问题。别的一些非深度学习问题,例如:二次型优化等问题,也都能够用这些深度学习东西来求解了。
更为优异的是,Theano 符号求导成果能够直接经过 C程序编译,成为底层言语,高效运转。
这儿咱们给一个 Theano 的比如:
》》》 import numpy
》》》 import theano
》》》 import theano.tensor as T
》》》 from theano import pp
》》》 x = T.dscalar(‘x’)
》》》 y = x ** 2
》》》 gy = T.grad(y, x)
》》》 f = theano.function([x], gy)
》》》 f(4)
8
上面咱们经过符号求导的办法,很简略的求出 y 关于 x 的导数在 4 这个点的数值。
规范 4:对数据量、硬件的要求和支撑
关于多 GPU 支撑和多服务器支撑,咱们上面说到的一切渠道都宣称自己能够完结使命。一起也有许多文献说某个渠道的作用更为优异。咱们这儿把详细渠道的挑选留给在座各位,供给下面这些信息:
首要想想你想要干什么。现在深度学习运用中,需求运用到多服务器练习模型的场景往往只要图画处理一个,假如是自然言语处理,其作业往往能够在一台装备优异的服务器上面完结。假如数据量大,往往能够经过 hadoop 等东西进行数据预处理,将其缩小到单机能够处理的范围内。
自己是比较传统的人,从小就开端自己折腾各种科学核算软件的编译。现在干流的文献看到的成果是,单机运用 GPU 能比 CPU 功率进步数十倍左右。
可是其实有些问题,在 Linux 环境下,编译 Numpy 的时分将线性函数包换为 Intel MLK 往往也能够得到相似的进步。
当然现在许多评测,往往在不同硬件环境、网络装备情况下,都会得到不相同的成果。
就算在亚马逊云渠道上面进行测验,也或许由于网络环境、装备等原因,形成彻底不同的成果。所以关于各种测评,根据我的经历,给的主张是:take it with a grain of salt,自己要留个心眼。前面咱们说到的首要东西渠道,现在都对多 GPU、多节点模型练习有不同程度的支撑,并且现在也都在快速的开展中,咱们主张听众自己依照需求进行辨别。
规范 5:深度学习渠道的老练程度
关于老练程度的评判往往会比较片面,定论大多具有争议。我在这儿也只列出数据,详细怎样挑选,咱们自己判别。
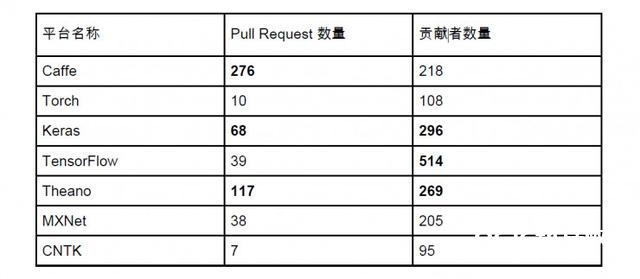
这儿咱们经过 Github 上面几个比较受欢迎的数量来判别渠道的活泼程度。这些数据获取于今日下午(2016-11-25)。咱们用黑体标出了每个因子排名前三的渠道:
第一个因子是奉献者数量,奉献者这儿界说十分广泛,在 Github issues 里边提过问题的都被算作是 Contributor,可是仍是能作为一个渠道受欢迎程度的衡量。咱们能够看到 Keras, Theano, TensorFlow 三个以 Python 为原生渠道的深度学习渠道是奉献者最多的渠道。
第二个因子是 Pull Request 的数量,Pull Request 衡量的是一个渠道的开发活泼程度。咱们能够看到 Caffe 的 Pull Request 最高,这或许得益于它在图画范畴得天独厚的优势,别的 Keras 和 Theano 也再次登榜。
别的,这些渠道在运用场景上有偏重:
自然言语处理,当然要首推 CNTK,微软MSR(A) 多年对自然言语处理的奉献十分巨大,CNTK 的不少开发者也是分布式核算牛人,其间所运用的办法十分独特。
当然,关于十分广义的运用、学习,Keras/TensorFlow/Theano 生态或许是您最好的挑选。
关于核算机图画处理,Caffe 或许是你的不贰挑选。
关于深度学习渠道的未来:
微软在对 CNTK 很有决计,Python API 加的好,咱们能够多多重视。
有观念以为深度学习模型是战略财物,应该用国产软件,避免独占。我以为这样的问题不必忧虑,首要 TensorFlow 等软件是开源的,能够经过代码检查的办法进行质量把关。别的练习的模型能够保存成为 HDF5 格局,跨渠道共享,所以成为谷歌独占的概率十分小。
很有或许在未来的某一天,咱们练习出来一些十分凶猛的卷积层(convolution layer),根本上能十分优异地处理一切核算机图画相关问题,这个时分咱们只需求调用这些卷积层即可,不需求大规模卷积层练习。别的这些卷积层或许会硬件化,成为咱们手机芯片的一个小模块,这样咱们的相片拍好的时分,就现已完结了卷积操作。