FPGA 规划人员在满意要害时序余量的一起力求完结更高功用,在这种状况下,存储器接口的规划是一个一贯构成困难而耗时的应战。Xilinx FPGA 供给 I/O 模块和逻辑资源,然后使接口规划变得更简略、更牢靠。尽管如此,I/O 模块以及额定的逻辑仍是需求由规划人员在源 RTL 代码中装备、验证、履行,并正确连接到其他的 FPGA 上,通过细心仿真,然后在硬件中验证,以保证存储器接口体系的牢靠性。
本白皮书评论各种存储器接口操控器规划所面对的应战和 Xilinx 的处理方案,一起也阐明怎么运用 Xilinx软件东西和通过硬件验证的参阅规划来为您自己的运用(从低本钱的 DDR SDRAM 运用到像 667 Mb/sDDR2 SDRAM 这样的更高功用接口)规划完好的存
储器接口处理方案。
存储器接口趋势和 Xilinx 处理方案
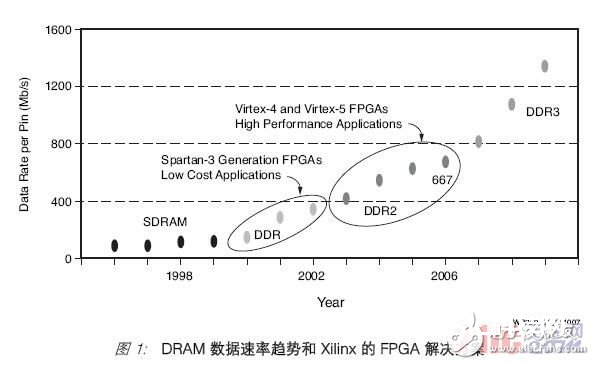
20 世纪 90 时代后期,存储器接口从单倍数据速率 (SDR) SDRAM 开展到了双倍数据速率 (DDR) SDRAM,而今日的 DDR2 SDRAM 运转速率现已到达每引脚 667 Mb/s或更高。当今的趋势显现,这些数据速率或许每四年增加一倍,到 2010 年,跟着DDR3 SDRAM 的呈现,很或许超越每引脚 1.2 Gb/s。见图1。
运用一般可分为两类:一类是低本钱运用,下降器材本钱为首要意图;另一类是高功用运用,首要方针是寻求高带宽。
运转速率低于每引脚 400 Mb/s 的 DDR SDRAM 和低端 DDR2 SDRAM 已能满意大多数低本钱体系存储器的带宽需求。关于这类运用,Xilinx 供给了 Spartan-3 系列FPGA,其间包括 Spartan-3、Spartan-3E 和 Spartan-3A 器材。
高功用运用把每引脚 533 和 667 Mb/s 的 DDR2 SDRAM 这样的存储器接口带宽推到了极限;关于这类运用,Xilinx 推出了 Virtex-4 和 Virtex-5 FPGA,能够充沛满意今日大多数体系的最高带宽需求。
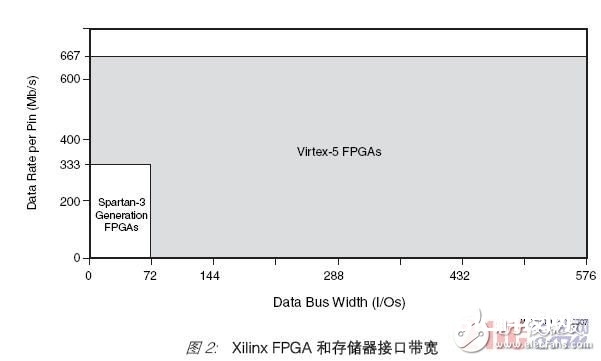
带宽是与每引脚数据速率和数据总线宽度相关的一个要素。Spartan-3 系列、Virtex-4、Virtex-5 FPGA 供给不同的选项,从数据总线宽度小于 72 位的较小的低本钱统,
到576 位宽的更大的 Virtex-5 封装(见图2)。
高于 400 Mb/s 速率的更宽总线使得芯片到芯片的接口愈益难以开发,由于需求更大的封装、更好的电源和接地-信号比率。Virtex-4 和 Virtex-5 FPGA 的开发运用了先进的稀少锯齿形 (Sparse ChevrON) 封装技能,能供给优秀的信号-电源和接地引脚比率。每个 I/O 引脚周围都有满意的电源和接地引脚和板,以保证杰出的屏蔽,使由同步交流输出 (SSO) 所形成的串扰噪音降到最低。
低本钱存储器接口
今日,并不是一切的体系都在寻求存储器接口的功用极限。当低本钱是首要的决议要素,并且存储器的比特率到达每引脚 333 Mb/s 现已满意时,Spartan-3 系列 FPGA配之以 Xilinx 软件东西,就能供给一个易于完结、低本钱的处理方案。
依据 FPGA 规划的存储器接口和操控器由三个根本构建模块组成:读写数据接口、存储器操控器状况机,以及将存储器接口规划桥接到 FPGA 规划的其他部分的用户界面(图3)。这些模块都在 FPGA 资源中完结,并由数字时钟管理器 (DCM) 的输出作为时钟来驱动。在 Spartan-3 系列完结中,DCM 也驱动查找表 (LUT) 推迟校准监视器(一个保证读数据收集具有正确时序的逻辑块)。推迟校准电路用来挑选依据 LUT 的推迟单元的数量,这些推迟单元则用于针对读数据对选通脉冲线 (DQS) 加以推迟。推迟校准电路计算出与 DQS 推迟电路相同的一个电路的推迟。校准时会考虑一切推迟要素,包括一切组件和布线推迟。
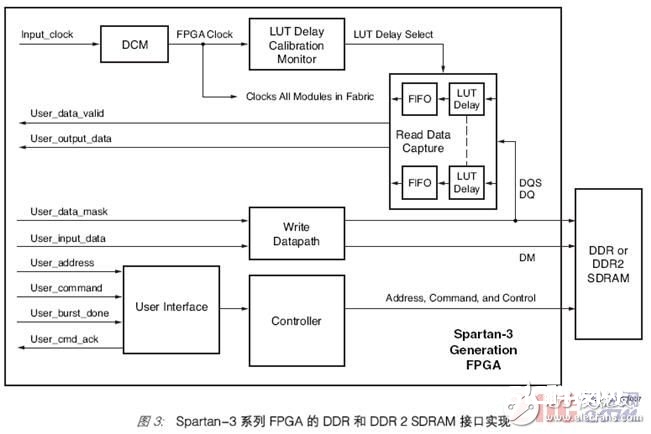
用户界面是一种握手型的界面。用户宣布一条读或写指令,假如是写指令的话还包括地址和数据,而用户界面逻辑以 User_cmd-ack 信号回应,所以下一条指令又可宣布。
在 Spartan-3 系列完结中,运用可装备逻辑块 (CLB) 中的 LUT 来完结读数据收集。在读业务进程中,DDR 或 DDR2 SDRAM 器材将读数据选通脉冲 (DQS) 及相关数据依照与读数据 (DQ) 边缘对齐的办法发送给 FPGA。在高频率运转的源同步接口中收集读数据是一项颇具应战性的使命, 由于数据在非自在运转 DQS 的每个边缘上都会改动。读数据收集的完结运用了一种依据 LUT 的 tap 推迟机制。DQS 时钟信号被适量推迟,使其放置后在读数据有用窗口中具有满意的余量,以在 FPGA 内被收集。
读数据的收集是在依据 LUT 的双端口散布式 RAM 中完结的(见图4)。LUT RAM 被装备成一对 FIFO,每个数据位都被输入到上升边缘 (FIFO 0) 和下降边缘 (FIFO 1)的FIFO 中,如图4 所示。这些深度为 16 个输入的 FIFO 异步运转,具有独立的读写端口。
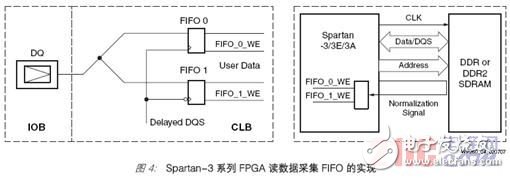
来自存储器的读数据写到通过推迟的 DQS 上升边缘的 FIFO_0 中,并写到通过推迟的DQS 下降边缘的 FIFO_1 中。将读数据从 DQS 时钟域传输到存储器操控器时钟域便是通过这些异步 FIFO 完结的。在存储器操控器的时钟域中,能够从 FIFO_0 和FIFO_1 一起读出数据。FIFO 的读指针在 FPGA 的内部时钟域中生成。写使能信号(FIFO_0 WE 和 FIFO1_WE)的生成通过 DQS 和一个外部回送(亦即归一化)信号完结。外部归一化信号作为输出传送至输入/ 输出模块 (IOB),然后通过输入缓冲器作为输入取出。这种技能可补偿 FPGA 与存储器器材之间的 IOB、器材和迹线推迟。从FPGA 输入管脚宣布的归一化信号在进入 LUT 推迟电路之前运用与 DQS 类似的布线
资源,以与布线推迟相匹配。环路之迹线推迟应为发送给存储器的时钟和 DQS 之迹线
推迟的总和(图4)。
写数据指令和时序由写数据接口生成并操控。写数据接口运用 IOB 触发器和 DCM 的90 度、180 度和 270 度输出,发送依照 DDR 和 DDR2 SDRAM 的时序要求与指令位和数据位正确对齐的 DQS。
用于 Spartan-3 系列 FPGA 的一种 DDR 和 DDR2 SDRAM 存储器接口完结已通过硬件进行了充沛验证。一个运用 Spartan-3A 入门套件的低本钱 DDR2 SDRAM 参阅规划示例已完结。此规划为板上 16 位宽 DDR2SDRAM 存储器器材而开发,并运用了XC3S700A-FG484。此参阅规划仅运用了 Spartan-3A FPGA 器材可用资源的一小部分:13% 的 IOB、9% 的逻辑 Slice、16% 的 BUFG MUX 和八个 DCM 中的一个。这一完结为其他部分 FPGA 规划所需的其他功用留下了可用资源。
运用存储器接口生成器 (MIG) 软件东西(本白皮书后面的部分有阐明),规划人员能够很简略地定制 Spartan-3 系列的存储器接口规划,以适宜自己的运用。
高功用存储器接口
跟着数据速率的进步,满意接口时序方面的要求变得愈益困难了。与写入存储器比较,从存储器中读数据时,存储器接口时钟操控方面的要求一般更难满意。寻求更高数据速率的趋势使得规划人员面对巨大应战,由于数据有用窗口(此为数据周期内的一段时刻,其间可获得牢靠的读数据)比数据周期自身缩小得快。形成这种状况的原因是,影响有用数据窗口尺度巨细的体系和器材功用参数具有种种不确认性,它们缩小的速率与数据周期不同。
假如比较一下运转速度为 400 Mb/s 的 DDR SDRAM 数据有用窗口和运转速度为 667
Mb/s 的 DDR2 存储器技能,这种状况就一望而知了。数据周期为 2.5 ns 的 DDR 器材具有 0.7 ns 的数据有用窗口,而数据周期为 1.5 ns 的 DDR2 器材仅有 0.14 ns 的数据有用窗口(图5)。

显着,数据有用窗口的加快减损给 FPGA 规划人员带来了一堆全新的规划应战,要创立和保护牢靠的存储器接口功用,就得选用更有用的办法。
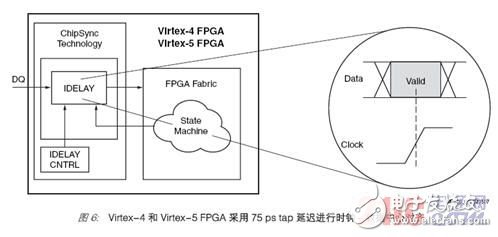
正如 Spartan-3 系列 FPGA 中所完结的那样,运用读数据 DQS 能够把读数据收集到可装备逻辑块 (CLB) 中,可是运用 LUT 把 DQS 或时钟与数据有用窗口中心对齐时,所用的推迟 tap 却很粗糙。CLB 中完结的推迟 tap 具有大约几百微微秒 (ps) 的分辨率,但是,关于超越 400 Mb/s 的数据速率的读取收集时序,所需的分辨率要比依据CLB 的 tap 高一个数量级。Virtex-4 和 Virtex-5 FPGA 选用 I/O 模块中的专用推迟和时钟资源(称为 ChipSync? 技能)来处理这一难题。内置到每个 I/O 中的 ChipSync模块都含有一串推迟单元(tap 推迟),在 Virtex-4 中称为 IDELAY,而在 Virtex-5FPGA 中称为 IODELAY,其分辨率为 75 ps (见图6)。
此完结的架构依据几个构建模块。用户界面担任把存储器操控器和物理层接口桥接到其他 FPGA 规划,它运用 FIFO 架构(图7)。FIFO 有三套:指令/ 地址 FIFO、写FIFO、读 FIFO。这些 FIFO 保存着指令、地址、写数据和读数据。首要的操控器模块操控读、写和改写操作。其他两个逻辑模块履行读操作的时钟-数据中心对齐:初始化操控器和校准逻辑。
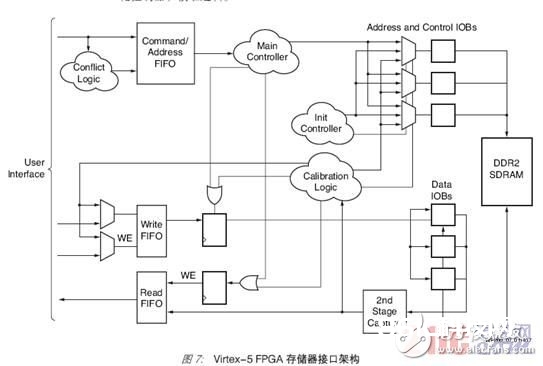
用于地址、操控和数据的物理层接口在 I/O 模块 (IOB) 中完结。读数据在锁存器的第二级(也是 IOB 的一部分)从头收集。
Virtex-4 和 Virtex-5 FPGA 存储器接口参阅规划支撑两种读数据收集技能。Virtex-4FPGA 支撑的直接时钟技能推迟了读数据,因而运用 IOB 的输入 DDR 触发器中的体系时钟可直接存放读数据。为将 FPGA 时钟对齐到最佳状况,对每个读数据位都会独自进行校验。这种技能为高达 240 MHz 的时钟速率供给了满意的功用。
第二种技能称为依据 DQS 的技能。此技能用于更高的时钟速率,Virtex-4 和 Virtex-5FPGA 二者都支撑此技能。它运用存储器 DQS 来收集相应的读数据,数据被此 DQS
的推迟信号(通过一个部分 I/O 时钟缓冲器 (BUFIO) 分配)存放。此数据然后在触发
器的第二级与体系的时钟域同步。IOB 中的输入串行器/ 解串器功用用于读数据收集;榜首对触发器把数据从推迟的 DQS 域中传输到体系的时钟域(图8)。

两种技能都涉及到 tap 推迟 (IDELAY) 单元的运用, 在由校验逻辑完结的校验程序中,这些推迟单元会有所改动。在体系初始化期间,会履行此校准程序以设置 DQS、数据和体系时钟之间的最佳相位。这样做的意图是使时序余量最大化。校准会消除任何由进程相关的推迟所导致的不确认性,然后补偿关于任何一块电路板都不变的那些通路推迟成分。这些成分包括 PCB 迹线推迟、封装推迟和进程相关的传达推迟成分(存储器和 FPGA 中都有),以及 FPGA I/O 模块中收集触发器的树立/ 坚持时刻。有的推迟是由体系初始化阶段的进程、电压和温度所决议的,校准即担任处理这些推迟的改动。
在校准进程中会增加 DQS 和数据的推迟 tap 以履行边缘检测,检测办法是通过接连从存储器中读回数据并对预编写训练形式或存储器 DQS 自身进行采样,直到确认数据选通脉冲 (DQS) 的前沿或前后两沿。之后数据或 DQS 的 tap 数被设定,以供给最大的时序余量。对“依据 DQS”的收集而言,DQS 和数据能够有不同的 tap 推迟值,由于
同步实质上分为两个阶段:一个先在 DQS 域中收集数据,另一个把此数据传输到体系时钟域。
在更高的时钟频率下,“依据 DQS ”的收集办法就变得十分必要,其二阶段办法能供给更好的收集时序余量,由于 DDR 时序的不确认性首要限于 IOB 中触发器的榜首级。此外,由于运用 DQS 来存放数据,与时钟-数据 (Tac) 改动比较较, DQS -数据改动的时序不确认性要小一些。例如,关于 DDR2 而言,这些不确认性便是由器材的tDQSQ 和 tQHS 参数给出的。
正如 Spartan-3 系列 FPGA 中所完结的那样,Virtex-4 和 Virtex-5 FPGA 的写时序由DCM 所支撑,此 DCM 生成体系时钟的两相输出。存储器的 DQS 由一个输出 DDR 存放器来输出,这个 DDR 存放器由体系时钟的同相时钟驱动。写数据则由超前体系时钟90° 的一个 DCM 时钟输出进行时钟操控。这种技能保证了在 FPGA 的输出部分,DQS 与写操作的数据中心对齐。
此规划的其他方面包括全体操控器状况机的逻辑生成和用户接口。为了使规划人员更简略完结整个规划,Xilinx 开发了存储器接口生成器 (MIG) 东西。
操控器规划和集成
创立存储器操控器是一项极端杂乱、精密的使命,FPGA 规划人员要处理面对的一道道难题,就需求 FPGA 随附的东西供给更新水平的集成支撑。
为规划的完好性起见,对包括存储器操控器状况机在内的一切构建模块加以集成,十分必要。操控器状况机因存储器架构和体系参数的不同而异。状况机编码也能够很杂乱,它是多个变量的函数,例如:
架构(DDR、DDR2、QDR II、RLDRAM 等)
组 (bank) 数(存储器器材之外或之内)
数据总线宽度
存储器器材的宽度和深度
组和行存取算法
终究,数据与 DQS 比 (DQ/DQS) 这类参数会进一步增加规划的杂乱性。操控器状况机必须按正确次序宣布指令,一起还要考虑存储器器材的时序要求。
运用 MIG 软件东西可生成完好的规划。该东西作为 CORE Generator 参阅规划和知识产权套件的一部分,可从 Xilinx 免费获取。MIG 规划流程(图9)与传统 FPGA 的规划流程十分类似。MIG 东西的长处是不用再为物理层接口或存储器操控器从头生成RTL 代码。
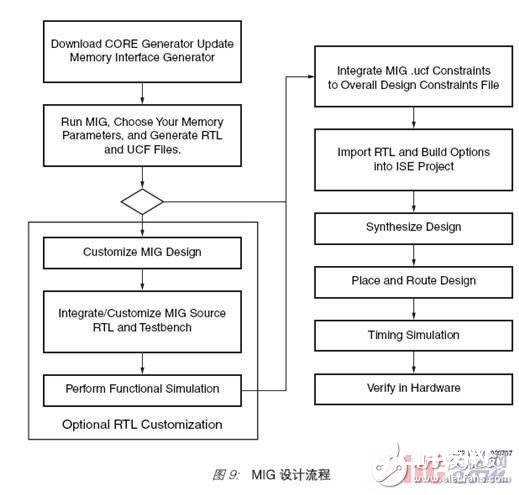
MIG 图形用户界面 (GUI) 可用于设置体系和存储器参数(图10)。例如,选定 FPGA器材、封装办法和速度等级之后,规划人员可挑选存储器架构,并挑选实践存储器器材或 DIMM。同是这一个 GUI,还可用于挑选总线宽度和时钟频率。一起,关于某些FPGA 器材,它还供给具有多于一个操控器的选项,以习惯多个存储器总线接口的要求。别的一些选项可供给对时钟操控办法、CAS 推迟、突发长度和引脚分配的操控。
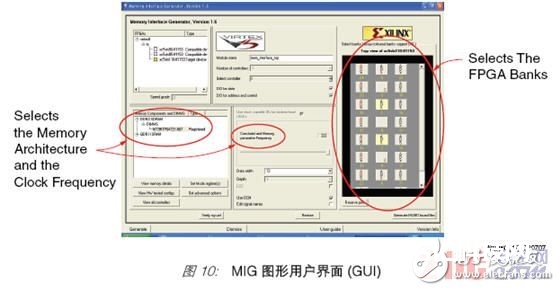
用不了一分钟,MIG 东西即可生成 RTL 和 UCF 文件,前者是 HDL 代码文件,后者是束缚文件。这些文件是用一个通过硬件验证的参阅规划库生成的,并依据用户输入进行了修正。
规划人员享有彻底的灵活性,可进一步修正 RTL 代码。与供给“黑匣子”完结办法的其他处理方案不同,此规划中的代码未加密,规划人员彻底能够对规划进行恣意修正和进一步定制。输出文件按模块分类,这些模块被运用于此规划的不同构建模块:用户界面、物理层、操控器状况机等等。因而,规划人员可挑选对操控组存取算法的状况机进行自定义。由 MIG 东西生成的 Virtex-4 和 Virtex-5 DDR2 的组存取算法互相不同。Virtex-5 规划选用一种最近最少运用 (LRU) 算法,使多达四组中的一行总是翻开,以减缩因翻开/ 封闭行而形成的开支。假如需求在一个新组中翻开一行,操控器会封闭最近最少运用组中的行,并在新组中翻开一行。而在 Virtex-4 操控器完结中,任何时候只要单个组有一个翻开的行。每个运用都或许需求有自己的存取算法来最大化吞吐量,规划人员可通过改动 RTL 代码来修正算法,以愈加适宜其运用的拜访形式。
修正可选代码之后,规划人员可再次进行仿真,以验证全体规划的功用。MIG 东西还可生成具有存储器校验功用的可归纳测验渠道。该测验渠道是一个规划示例,用于Xilinx 根底规划的功用仿真和硬件验证。测验渠道向存储操控器宣布一系列写和读回指令。它还能够用作模板,来生成自定义的测验渠道。
规划的终究阶段是把 MIG 文件导入 ISE 项目,将它们与其他 FPGA 规划文件兼并,然后进行归纳、布局和布线,必要时还运转其他时序仿真,并终究进行硬件验证。MIG软件东西还会生成一个批处理文件,包括相应的归纳、映射以及布局和布线选项,以协助优化生成终究的 bit 文件。
高功用体系规划
完结高功用存储器接口远远不止完结 FPGA 片上规划,它需求处理一系列芯片到芯片的难题,例如对信号完好性的要求和电路板规划方面的应战。
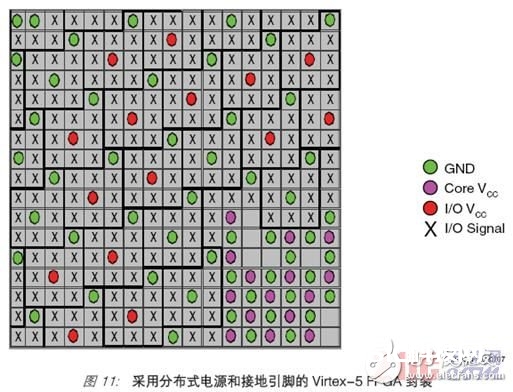
信号完好性的应战在于操控串扰、地弹、振铃、噪声容限、阻抗匹配和去耦合,然后保证牢靠的信号有用窗口。Virtex-4 和 Virtex-5 FPGA 所选用的列式架构能使 I/O、时钟、电源和接地引脚布置在芯片的任何方位,而不光是沿着外围摆放。此架构缓解了与 I/O 和阵列依赖性、电源和接地散布、硬 IP 扩展有关的问题。此外,Virtex-4 和Virtex-5 FPGA 中所运用的稀少锯齿形封装技能能对整个封装中的电源和接地引脚进行均匀分配。这些封装供给了更好的抗串扰才能,使高功用规划中的信号完好性得以改进。图11 所示为 Virtex-5 FPGA 封装管脚。圆点表明电源和接地引脚,叉号表明用户可用的引脚;在这样的布局中,I/O 信号由满意的电源和接地引脚盘绕,能保证有用屏蔽 SSO 噪音。
关于高功用存储器体系来说,增加数据速率并不总能满意需求;要到达期望的带宽,就需求有更宽的数据总线。今日,144 或 288 位的接口现已随处可见。多位一起切换可导致信号完好性问题。对 SSO 的约束由器材供货商标明,它代表器材中用户可为每组一起运用的信号引脚的数量。凭仗稀少锯齿形封装技能杰出的 SSO 噪音屏蔽优势和同质的 I/O 结构,宽数据总线接口彻底或许完结。
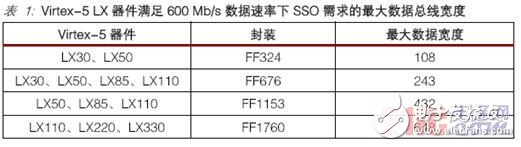
表1 列出了 Virtex-5 LX 器材和满意 600 Mb/s 数据速率下的 SSO 需求的最大数据总线宽度。
规划大容量或密集型存储器体系的另一个应战是容量负载。高功用存储器体系或许需求由地址和指令信号共用的一条总线驱动的多存储器器材。大容量无缓冲 DIMM 接口便是一个比如。假如每个单列 DIMM 具有 18 个组件,那么包括两个 72 位无缓冲DIMM 的接口能够在地址和指令总线上具有多达 36 个接收器。由 JEDEC 规范引荐,并在通用体系中常见的最大负载是两个无缓冲 DIMM。总线上所发生的容量负载会极端巨大,导致信号边缘上升和下降需求多于一个时钟周期,然后使存储器器材的树立和坚持犯错。图12 所示为 IBIS 仿真所供给的眼图,运用的是不同装备:一个存放
DIMM、一个无缓冲 DIMM 和两个单列无缓冲 DIMM。容量负载的规模从运用存放DIMM 时的 2 个接收器到运用无缓冲 DIMM 时的 36 个接收器不等。

这些眼图清楚地显现了地址总线的容量负载作用;存放 DIMM 供给地址和指令总线上一个打得很开的有用窗口。一个 DIMM 的眼打开度在 267 MHz 下依然不错。但是,当负载为 32 时,地址和指令信号有用窗口便大为缩小,而传统的完结办法已不足以牢靠地与两个无缓冲 DIMM 接口。
这个简略的测验示例阐明负载会导致边缘显着变慢的一起,眼图在更高的频率下闭上。关于总线负载不行削减的体系,下降操作的时钟频率不失为使信号完好性维持在可接受水平上的一种办法。但是,还有其他办法能够在不下降时钟频率的状况下处理容量负载问题: 在能够往接口增加一个时钟周期的推迟的运用中,运用存放 DIMM 能够是不错的挑选。这些 DIMM 运用一个存放器来缓冲地址和指令一类信号,然后下降容量负载。 运用依据在地址和指令信号上选用两个时钟周期(称为 2T 时序)的规划技能,地址和指令信号能够用体系时钟频率的一半发送。操控好存储器体系的本钱和到达要求的功用相同,也是一个很大的应战。下降电路板规划的杂乱性并削减资料费用的一个办法是运用片上终端而不是电路板上的电阻器。Virtex-4 和 Virtex-5 系列 FPGA 供给一种称为“数控阻抗 (DCI)”的功用,在规划中完结该功用可削减电路板上的电阻器数量。MIG 东西有一个内置选项,答应规划人员在完结存储器接口规划时包括针对地址、操控或数据总线的上述功用。此刻要考虑的一个权衡要素是当终端在片上完结时,片上与片外功耗孰优孰劣。
存储器接口的开发板
对参阅规划进行硬件验证是保证处理方案紧密牢靠的重要终究进程。Xilinx 现已验证了Spartan-3 系列、Virtex-4 和 Virtex-5 FPGA 的存储器接口规划。表2 所示为关于每一个开发板,所支撑的存储器接口。
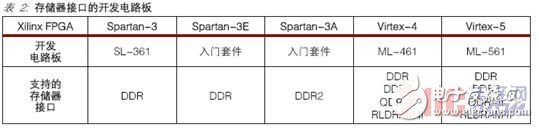
开发电路板的规模包括从低本钱 Spartan-3 系列 FPGA 完结到 Virtex-4 和 Virtex-5FPGA 系列器材所供给的高功用处理方案。
定论
有了适宜的 FPGA、软件东西和开发电路板这样的利器,运用 667 Mb/s DDR2SDRAM 进行存储器接口操控器规划便成为一个既快速又流通的进程,无论是低本钱运用仍是高功用规划,都能够称心如意地完结。