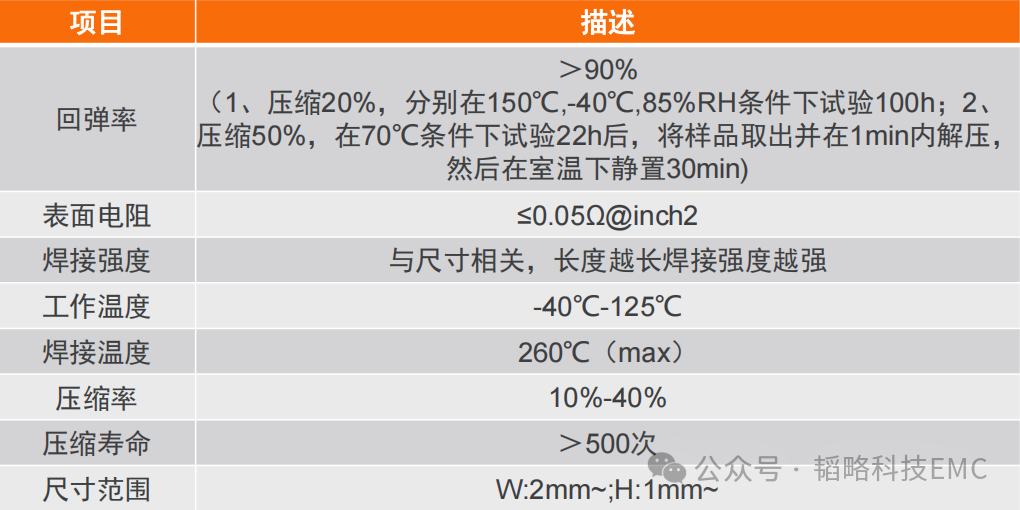
“No PP,No WAY”这是个眼见为实的世界,这是个视觉构成的信息激流的世界。大脑处理视觉内容的速度比文字内容快6万倍,而跟着智能手机的遍及,图片、视频的发生和共享现已是人们在交际渠道上的根本沟通办法。用户经过手机、平板、电脑上传和共享自己的图片,并且这个趋势是每年都在添加(参见图1)。
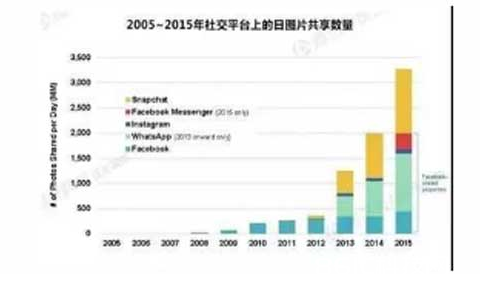
图1. 2016年KPCB核算陈述
每天QQ相册、微信朋友圈上,用户上传的图片数量有上亿张,这些图片被后台服务器存储下来,再经过网络分发出去。假如每张图片能够进行紧缩,使得图片存储和传输分发的数据量越少,既节约了用户带宽,也进步了用户下载图片的速度,用户体会更好。那么图片是能够进行紧缩的么?1948年,信息论学说的奠基人香农从前证明:不论是语音或许图片,因为其信号中包含许多的冗余信息,所以能够对其进行紧缩。图画紧缩算法有:JPEG、WEBP、H264(帧内紧缩)、HEVC(帧内紧缩),紧缩才干是:JPEG 《 WEBP/H264(帧内紧缩) 《 HEVC(帧内紧缩), 这个紧缩才干是经过核算杂乱度的进步来完结,其间WEBP、HEVC的核算杂乱度是 JPEG 紧缩的 10 倍以上。 现在在交际渠道上用户上传的很多图片是JPEG格局,经过后台服务器用愈加杂乱的算法如WEBP、HEVC(帧内紧缩),进一步紧缩以节约存储和带宽, 所以对图画的紧缩,从本质上是经过进步核算算力来下降存储和带宽。一起愈加杂乱的算法也带来核算算力的很多耗费和处理延时的添加。
从事务视点来看,关于离线事务,能够经过事务在波峰和波谷之间搁置的核算算力进行图片转码处理;但关于在线事务,图片转码处理关于处理延时的要求就会有较高要求,为了满意处理延时的要求,有时分会先进行图片转码处理,把转码好的图片存储下来,当用户需求的时分直接传输,这样经过耗费存储资源为价值来处理处理延时的要求。可是这又带来一个新问题,用户检查图片的智能终端屏幕巨细不一,假如都传相同巨细的图片,明显不是最优。最优处理办法仍是能够经过核算算力,实时进行图片转码处理。
在数据中心里边,核算算力一般由x86 CPU来供给,曾经的x86 CPU功用每18个月就能翻倍(众所周知的“摩尔定律”),但现在工业界的开展方向是摩尔定律现已走到结尾。例如,2016年3月24日,英特尔宣告正式停用“工艺年-架构年(Tick-Tock)”处理器研制办法,未来研制周期将从两年周期向三年期改变。而世界半导体技术开展路线图(InternaTIonal Technology Roadmap for Semiconductors,简写 ITRS)在保持了数十年,每两年更新一次,为全世界半导体职业供给建议和规划攻略,也在2016年宣告不再做进一步的更新。
一方面处理器功用再无法依照摩尔定律进行添加,另一方面数据添加对核算功用要求超过了按“摩尔定律”添加的速度。处理器自身无法满意高功用核算(HPC:High Performance Compute)使用软件的功用需求,导致需求和功用之间呈现了缺口(参见图2)。
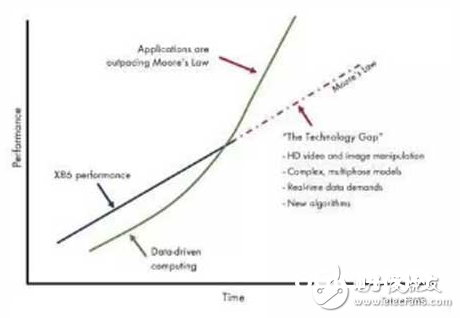
图 2. 核算需求和核算才干的缺口开展办法
图画处理处理计划
图片服务支撑的才干丰厚多样,根底功用包含多种缩略取舍办法、文字图片水印、格局转化、断点续传、镜像存储、防盗链等。咱们结合当时图文年代的用户需求,供给图片的上传、存储、处理、分发的全方位一体化的处理计划。现在,互联网图片服务的处理计划中落地存储和下载大部分图片格局仍是JPEG/WEBP,但跟着新的编码规范HEVC的呈现,在平等图画质量下,HEVC的紧缩功率会比JPEG/WEBP好30%~70%,能够节约很多的存储和带宽,可是HEVC的算法杂乱度高导致CPU的编码推迟和吞吐在线上环境中无法满意,因而,咱们开发了依据FPGA的新的处理计划。FPGA图画处理计划能够很好的处理线上环境的需求,当然,FPGA图画处理处理计划也兼容当时用户线上体系的WEBP等其他图画转码格局,能够很好的习惯不同用户的需求,供给低推迟,高吞吐,低本钱的处理计划。
咱们以HEVC FPGA 图画处理为例,来阐明在互联网事务中图片上传,存储,处理和下载的架构。
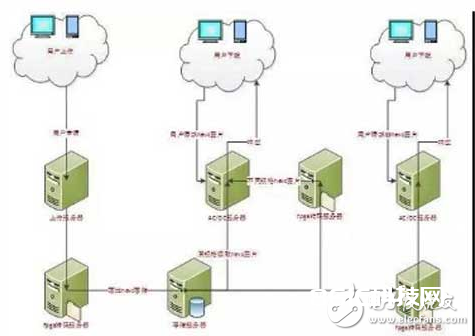
图3. HEVC FPGA 图片上传存储,处理,下载处理计划
如图3所示,图片HEVC FPGA转码的布置首要是落地存储前以及下载前的转码服务器,运用FPGA做转码首要有以下优势:
FPGA转码落地存储HEVC,可有用节约存储本钱。
1. FPGA转码服务器和CPU转码比较能够下降服务器本钱。
FPGA转码HEVC图片和CPU比较吞吐量能够大大进步。
在下载时实时生成HEVC图片,运用FPGA进行图片转码加快,会大大下降转码推迟,进步用户体会。
图画编码算法剖析
在图画和视频编解码算法中,各个模块都是依据像素级运算或许依据块操作,并且针对各个像素或许图画块的操作是相同和重复的。前期的图片紧缩规范JPEG和JPEG200,原始图画首要经过依据块的DCT改换或许小波改换,改换后的系数经过量化后再进行熵编码(包含Huffman编码或许自习惯算术编码),然后输出紧缩后的码流信息。在解码端,经过反向操作,可将码流信息进行解码。在JPEG2000中,DCT改换被小波改换代替,能够更好的消除图画块内的冗余性,并且量化后的体系依照比特位平面进行自习惯算术编码,能够到达更好的紧缩功用。
除了JPEG这类对原始图画直接改换的办法,还有一种是依据块猜测的办法。也便是对一个图画块先进行猜测,原始图画块和猜测块的残差再进行改换,量化和编码。比较典型规范便是从H.264的帧内猜测开展而来的WebP。跟着新一代视频编码规范HEVC/H.265的推出,其帧内编码的紧缩功用,较上一代规范进步挨近一倍[2]。因而,将HEVC的帧内编码用于图画紧缩也成为一种趋势。HEVC的帧内编码进程如图4所示。
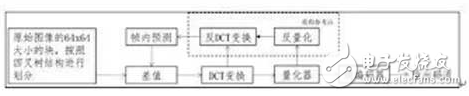
图4. HEVC帧内编码的进程
在HEVC中,块区分的办法是依据非彻底四叉树结构,这更适用于不同的图画场景。每一个终究确认巨细的块只需求一个独立的猜测办法。图5是HEVC图片编码中块区分和猜测办法的一个比如。能够看出当一个块能够经过独自的某一个视点进行猜测的时分,则不需求区分为更小的块。而场景信息较为杂乱区域则需求区分为较小的块。编码器的一项重要使命,便是寻觅最佳的块区分办法和最优的猜测视点。

图5. HEVC图片编码块区分及猜测办法
图6(a) 便是依据终究的块区分办法和猜测办法得到的猜测图片。猜测图片和原始图片的差值(残差)经过DCT改换,量化之后,终究经过熵编码器输出。图片猜测的残差如图6(b)所示。在解码器中,依据得到的残差数据,并进行和编码器相同的猜测,能够得到终究的重构图片,图6(c)所示的便是重构数据。因为编码进程需求用到重构数据作为参阅数据,因而在编码器也需求进行重构的进程。原始图片如图6(d)所示,能够看出,重构的图片和原始图片丢失十分小。

图6. HEVC图片编码进程中的猜测,残差,重构以及原始数据
在HEVC的帧内编码中,因为要进行最佳编码办法的查找,形成编码器的核算杂乱度高。传统的CPU无法到达抱负的吞吐量。现在的GPU尽管也很多使用的图片和视频范畴,可是GPU的并行化更适用的是各个像素点进行相同操作,完结之后再进行下一步的并行化操作。这并不利于HEVC图片编码各个模块操控较为杂乱的状况。在Nvidia的GPU中,图片和视频编解码也选用的专用的芯片来处理。 而FPGA能够完结各个不同的模块的流水化运算,完结时间上的并行。 一起,因为仅仅进行帧内编码,不同图画之间是彼此独立的,在FPGA中也能够规划多路的编码器,对不同的图片进行并行的编码紧缩。
当然,关于依据块猜测的图画编码办法,也存在一些约束FPGA并行化完结要素。可是,这些受到约束的部分,也能够经过FPGA规划的特点来处理。例如,如图4所示,帧内猜测的参阅点需求经过重构的办法得到,这就添加了不同块之间的依靠性,约束了块之间的并行化,和流水化规划。在实践的FPGA规划中,能够在进行猜测办法初选时,用原始数据代替重构数据作为参阅,而在终究编码时用重构数据在作为参阅数据。在FPGA的完结进程中,也能够更改扫描次序,优先处理那些有依靠联系的像素点。此外,在自习惯熵编码部分,因为存在更新码表和更新概率估量的进程,部分比特数据进行熵编码时,也存在依靠联系。 在实践的FPGA规划进程中,能够经过将这些需求进行编码的数据进行分组,将没有依靠联系的数据分为一组,一起,经过数据缓存,能够预先判断接下来的数据是否存在依靠联系,然后进步熵编码的吞吐量。
HEVC图画编码算法的FPGA完结
FPGA图画编码架构
现在,咱们图片事务现已完结WEBP和HEVC格局的FPGA硬件加快,下面以HEVC I帧图画硬件加快举例,阐明图画编码在FPGA中是怎么完结的。
FPGA的逻辑架构首要包含渠道部分和HEVC编码器IP部分,其间FPGA渠道首要包含PCIE DMA以及DDR总线相关逻辑,这部分逻辑首要完结和host CPU的数据通讯以及和FPGA板卡上的DDR通讯。如图7所示,FPGA架构上实例化了4个HEVC core(详细几个是和FPGA资源有关),每一个HEVC core完结HEVC编码算法的完好处理,这儿4中心并行作业,也便是同一时间,4个编码使命能够并行作业,一起输出4条HEVC码流。
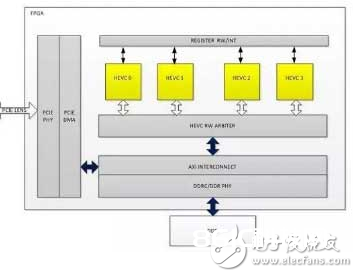
图7. FPGA内部逻辑架构
FPGA内部逻辑首要包含:
HEVC CORE 0-3:H265编码器IP,完结HEVC的编码算法;
PCIE/DMA:完结和host CPU进行通讯;
REGISTER RW/INT:寄存器读写以及中止处理;
HEVC RW ARBITER:总线读写裁定模块;
AXI INTERCONNECT/DDRC/DDRY: 总线操控拜访DDR逻辑;
FPGA图画编码流程
FPGA HEVC core内部算法处理流程如图8所示:分为当时图画载入,intra猜测初选,intra猜测精选,CABAC编码,码流输出。
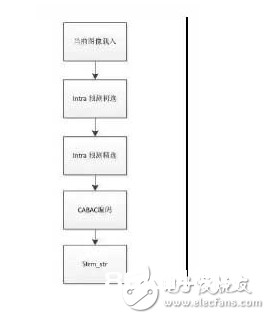
图8. HEVC core内部算法处理流程
那么怎么规划HEVC core完结算法功用呢?这儿,编码器模块流水线规划成四级流水,如图9所示,四级流水CURLD/PINTRA/SEL/CABAC处理功用规划挨近,并行起来后,均匀处理每个LCU需求8400个周期,假如依照1080p图片总共510个LCU核算,单核理论上编码能够到达编46 帧/s (FPGA电路完结频率200M),这样4核并行能到达184帧/s。
详细来说,CURLD完结当时图画的载入逻辑,PINTRA完结intra猜测初选35种办法的遍历,得到最优的猜测办法,这级流水算法上做了优化,猜测参阅像素没有像传统办法挑选重构像素,而是挑选当时像素做参阅像素,这样优化,使得intra猜测初选能够独自区分为一级流水,和intra猜测精选分隔,使得编码器全体处理功用添加一倍。SEL完结帧内猜测办法精选以及RDO办法挑选,猜测块巨细支撑32/16/8,因为涉及到改换量化等运算量大的逻辑,这一级流水是整个编码器的资源耗费大户,规划上在算法上以及逻辑资源耗费上做了权衡;CABAC模块完结头信息的码流生成以及每个LCU的语法元素和残差的编码,并完结码流的打包输出,这一级流水的首要问题在于CABAC的功用是否足够快,然后应对QP比较小编码更多bin的处理及时。
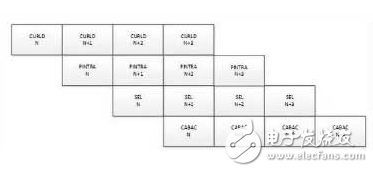
图9. 运算模块流水线
功用和收益
用FPGA完结JPEG格局图片转成HEVC格局图片,图片分辨率巨细为1920×1080,FPGA处理延时比较CPU下降7倍,FPGA处理功用是CPU机器的10倍,FPGA机型单位功用本钱是CPU机型的1/3(参见图10)。
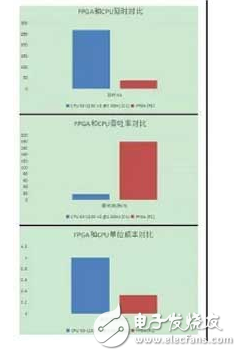
图10.图片转码FPGA和CPU比照
总归,图片算法的FPGA完结,假如不考虑FPGA资源、硬件完结架构和处理功用,CPU图画紧缩算法能够彻底在FPGA进行“仿制”完结,FPGA算法紧缩功用能够彻底同等CPU。可是实践没那么抱负,FPGA算法完结要一致考虑FPGA功用,资源,算法完结杂乱度等要素,只要联合规划才干规划出最优异的计划,为了发挥FPGA硬件完结的速度优势,算法进行优化是有必要要做的,归纳考虑各方面,咱们在实践使用中,往往FPGA的算法完结要做一些“退让”。别的,某种类型的FPGA一旦被选定,它的运算以及布线资源往往有个理论值,算法的完结一起要考虑FPGA资源的使用状况,怎么能在相同的FPGA资源上完结最好的紧缩算法成为规划的难点。咱们用FPGA进行算法完结的方针—–完结算法功用尽量挨近CPU,图片处理吞吐量,以及处理推迟让CPU望其项背。