分组暗码具有速度快、易于标准化和便于软硬件完结等特色,已成为信息与网络安全中完结数据加密、数字签名、认证及密钥办理的中心体系之一。跟着暗码学和芯片规划技能的开展,专用暗码处理器作为一个高速、灵敏的完结办法已被广泛认可。专用分组暗码处理器的指令集包括了较多运算指令,这些运算指令的灵敏性与履行功率在必定程度上决议了体系处理数据的灵敏性与速度。移位操作具有较好的打乱与分散作用,又易于软硬件完结,所以其运用频率十分高,因而移位操作指令的规划成为专用分组暗码处理器指令集规划的要害之一。本规划依据32位RISC微处理器,提出了可适配的、支撑多路并行履行的移位操作指令RPSI(Reconfigurable and Parallel Shift Instruction),可以完结字节移位、亚字移位、字移位以及双字的级联移位,并经过指令组合完结长字移位。文章给出了相应移位运算单元的硬件规划,终究给出了移位运算单元的功用剖析。
1 分组暗码算法中的移位操作
分组暗码算法顶用到了很多的移位操作,但其履行形式各不相同。
移位操作依照所移位数是否可变,分为固定移位和不定移位。依据常量的固定移位是分组暗码处理中一种最首要的移位形式,它使数据比特抵达指定的方位,且算法不易遭受守时进犯,包括移位位数及其补码的寄存器内容也可反抗能量进犯[6],在Rijndael、DES、RC6等41种分组暗码算法中有25种算法运用了固定移位[1]。依赖于分组运算中心数据或子密钥的不定移位形式,使不同子数据途径上的分组之间有了较好的打乱与分散作用,因而具有较强的反抗线性暗码剖析的才能,现在现已得到广泛运用。地点剖析的41种分组暗码算法中有10种算法运用了不定移位。表1给出了移位操作在常用分组暗码算法中的运用。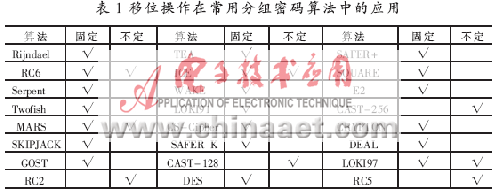
移位操作依照其移位办法,可分为循环移位办法和逻辑移位办法,其间,循环移位办法运用较多,如Serpent[2]、Twofish[3]、MARS[4]等算法均运用了循环移位。
移位操作依照移位方向,可分为左向移位和右向移位办法。
依照移位的操作位宽,可分为字节(8bit)移位、亚字(16bit)移位、字(32bit)移位、双字(64bit)移位及长字(128bit)移位。除DES算法移位操作的操作位宽为28bit外,其他算法的操作位宽均为2n bit(n=34567)。考虑到一些专用范畴,像军事运用,有些专用暗码算法所运用的移位操作位宽已达到256bit, 但因当时分组暗码算法的处理位宽多为32bit,所以字移位操作的运用频率相对较高。
2 RPSI的规划及其可扩展、可级联特性研讨
2.1 RPSI的规划
经对分组暗码算法中移位操作特征的剖析可知,完结一个指定的移位操作,需求确认其移位位数是否可变,选用何种移位办法、移位方向及移位操作位宽,所以移位操作指令的func域要包括的四个参数为:source、com、width、mode,加上标识移位位数是当即数的shift域,以及指令本身的操作数域rd、rs1及rs2,其指令格局如表2。
对func域上的source、come、width、mode适配不同的值后,此指令就可以完结不同的移位操作。因为当时常用暗码算法的处理位宽多为32bit,且本规划是依据32位RISC微处理器,所以设定其操作数rd、rs1,rs2的位宽为32bit的寄存器数,imm为5bit的当即数,它依据参数source而定。
sourse的值可适配为1或0。适配为0时,代表所进行的操作为固定移位,imm为5bit的当即数;适配为1时,代表所进行的操作为不定移位,移位位数寄存在rs2中,rs2为32bit的寄存器数(取后5位);mode为移位形式,00时为逻辑左移,01时为逻辑右移,10时为循环左移,11时为循环右移。width是8bit、16bit或32bit移位位宽的挑选。width为00时,表明履行字节移位,一条指令可并行完结四组字节移位;width为01时,履行亚字移位,一条指令可并行完结两组;为10时,履行字移位。例如:指令IROLm Rd, Rs1, #3,它所完结的操作为:将寄存器Rs1中的32bit数按8bit分四组,别离进行固定的循环左移,移位位数为3;同理,进行相应的不定移位操作时,其指令为ROLm Rd, Rs1, Rs2,其移位位数由Rs2寄存器数的低5bit指定。图1(a)、图1(b)给出了当width为8时,履行四种字节移位操作指令的功用示意图,指令将输入的32bit数据分为4个字节,每个字节本身独登时进行指定形式的移位操作。图1(c)、图1(d)给出了当width为32bit时的字移位操作功用示意图。
2.2 RPSI的级联履行
跟着分组暗码算法干流分组宽度的添加,仅在32bit数据途径上的移位操作已不能满意要求,但因为RISC处理器32位位宽的局限性,不能改动其32bit的数据途径,因而在进一步研讨移位操作的根底上,提出了移位操作指令的级联履行形式,即64bit级联移位。
假定要履行的操作为64bit循环左移,移位位数为m,其指令为CROL Rd, Rs1, Rs2, #imm,这时指令格局中func域的com值是1,表明级联。Rs1、Rs2是64bit源操作数,Rs1中寄存的是64bit中高32bit,Rs2中寄存的是64bit中低32bit,Rd为意图操作数,运算后寄存的是64bit移位的高32bit成果。下一个时钟(第二步),交流64bit的凹凸32bit,运算后Rd寄存64bit移位的低32bit成果。
这样就在32bit的数据途径上完结了64bit的移位操作。其功用示意图如图2所示。
同理可履行循环右移操作。但在履行级联的逻辑移位操作时有所不同,进行逻辑左移时,第一步与循环移位相同,在第二步时,Rs1中寄存的是64bit中低32bit,Rs2中寄存的操作数是全零;进行逻辑右移时,在第一步时,Rs1中寄存的是64bit中高32bit,Rs2中寄存的操作数全为零,第二步与循环移位相同。
2.3 RPSI的组合履行
某些暗码算法的移位操作位宽是128bit,例如IDEA算法的子密钥生成中,就用到了长字移位操作。在级联移位指令的根底上,经过指令的组合完结128bit移位操作,或许更长位宽的移位操作,例如:要完结128bit的移位,需求履行四条级联移位指令。
以128bit逻辑左移5位为例,假定R4R3R2R1表明128bit待移位的数据,则履行指令CSHL Rd, R1, Rs, #5(Rs中的数是全零),得到移位后终究成果的31~0位;履行指令CSHL Rd, R2, R1, #5,得到移位后终究成果的63~32位,履行指令CSHL Rd, R3, R2, #5,得到移位后终究成果的95~64位;履行指令CSHL Rd, R4, R3, #5,得到移位后终究成果的127~96位。
再以128bit循环左移5位为例,假定R4R3R2R1表明128bit待移位的数据,则履行指令CROL Rd, R1,R4,#5,得到移位后终究成果的31~0位,履行指令CROL Rd,R2,R1,#5,得到移位后终究成果的63~32位;履行指令CROL Rd,R3,R2,#5,得到移位后终究成果的95~64位;履行指令CROL Rd,R4,R2,#5,得到移位后终究成果的127~96位。
同理,可以用这种多条指令组合的办法完结256bit的移位。128bit移位操作功用示意图如图3所示。
3 RPSI的硬件完结及其功用剖析
3.1 移位操作硬件完结算法研讨
传统的完结办法中,依据线性反应移位寄存器LFSR是完结移位操作的一种首要办法,LFSR通常以移1位运算为根底,循环移k位经过k次调用移1位根本运算完结,占用k个时钟周期,移位速度受移位位数的影响。因而关于移位位数较大的操作,选用LFSR进行循环移位运算很难满意高速数据处理的需求。
循环移位操作还可以看作是一类特别的置换,选用依据BENES网络的完结办法。可是,因为移位位数k的不确认性,导致装备信息生成电路较为杂乱,不利于软硬件完结。下面在对循环移位及逻辑移位别离研讨的根底上,给出了依据数据挑选器的完结办法。
(1) 循环移位的完结
令移位位数k=kn-12n-1+kn-22n-2+…+…k12+k0,则循环移位可以表明为: y=RSH(a,k),y的第j位y(j)可以表明为: y(j)=a((j±k)modN)
其间,履行左移操作时操作符为“-”,履行右移操作时操作符为“+”,N为操作数a的位宽。由此可得:
即:恣意位的循环移位操作分解为若干加减2i置换操作的级联。关于循环左移而言,循环移位操作可以分解为减2i置换操作。
循环左移操作算法描绘:
Input:操作数a, k=kn-12n-1+ kn-22n-2+…+k12+k0 Output:y
(1) y←a
(2) For i=n-1 downto 0 do
(3) For j= 0 to N-1 do
If ki=1 then
If j≤k then b(j)=y((j-2i)modN)
else b(j)=0
else b(j)=y(j)
(4) y=b Return (y)
当N=2n时,循环左移操作可以选用n级数据挑选器完结,每一级运用N个二选一数据挑选器,合计需求nN个二选一数据挑选器,体系的推迟相当于n级二选一数据挑选器的推迟。循环右移操作可以看作循环移位位数为N-k的循环左移操作,由此可以结构如图4所示的循环移位结构。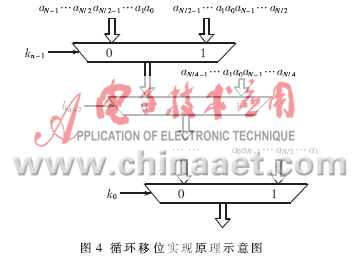
(2) 逻辑移位的完结
关于逻辑左移,上述算法可以修正如下:
Input:操作数 a,移位位数 k=kn-12n-1+ kn-22n-2+…+k12+k0 Output:y
① y←a
② For i=n-1 downto 0 do
③ For j= 0 to N-1 do
If ki=1 then
If j≤k then b(j)=y((j-2i)modN)
else b(j)=0
else b(j)=y(j)
④ y=b Return (y)
可以选用相似的办法对逻辑右移操作算法进行修正,本文不再赘述。在硬件完结时,可以经过将上述循环移位电路的每一个数据挑选器扩展为四选一完结支撑循环移位和逻辑移位的电路。
3.2 移位操作硬件单元的完结及功用剖析
依据依据数据挑选器的完结原理,用verilog言语完结了32bit数据途径上的移位操作硬件单元,用modelsim SE 6.0仿真软件进行了功用仿真,关于RPSI所指定的功用,均能正确完结。运用Design Compiler归纳东西进行了归纳,在0.18μm工艺下归纳成果如表3。
由前面剖析可知,要完结32bit数据途径上RPSI不同形式的移位操作,只需在图4的每个挑选输入上加一个四选一的数据挑选器,其要害途径即为一级四选一数据挑选器和六级二选一数据挑选器的途径推迟。
移位操作是暗码算法中常用的运算,特别是在密钥调度顶用于子密钥的生成。本文在剖析Rijndael、DES、RC6等41种分组暗码算法的根底上,首要对分组暗码算法中移位运算的操作特征进行了研讨,结合移位操作特征,提出了可适配的、支撑多路并行履行的RPSI;经过适配操作特征域上的source、com、width、mode四个参数,可完结固定或不定、循环或逻辑、左向或右向、不同位宽下的移位操作,可以支撑字节移位、亚字移位、字移位以及双字的级联移位,并经过指令组合完结长字移位;规划并完结了其硬件单元,给出了硬件单元的功用剖析。