虚拟现实技能可分为两类[1],一类是依据三维图形生成的虚拟场景技能,另一类则是依据实景收集经过几许改换取得近似的实在场景。反射式全景传感器十分适合于构建实景收集的实在场景。在曩昔的十年中, 多种反射式全景传感器相继问世[2]。反射式全景传感器由摄像机和曲面反射镜组成, 与一般摄像机不同的是,它可以一次性收集360°圆周内的悉数现象, 因而得到了广泛运用[3]。
现在,反射式全景技能的研讨首要将注意力会集在几许改换算法和镜头校对算法的改善,对收集和显现的同步性问题研讨甚少,如文献[1]和文献[4]所做的作业是在图形作业站完结的,便携性差,无法习惯嵌入式多媒体运用的要求。另一方面,实践运用中往往要求打开后的平面显现图画有较高的分辩率,而反射镜体积的约束使成像分辩率有限,打开后的图画呈现有规则的锯齿失真和灰度阶梯化现象。这就需求经过相应的视频后处理算法生成人眼可以承受的图画。上述两个问题给反射式全景视频的实时平面显现在嵌入式视频处理渠道上的运用带来应战。
1 全景图画打开算法及其存在的问题
1.1 全景图画打开算法

1.2 失真现象的发生原因及处理
经过改换打开后的平面图画,其坐标改换对错线性采样进程,即采样点呈环状散布,不同半径的环状采样点数相同。假如以原图画最大半径的采样点数作为基准对整幅图画进行打开,则半径越小扩大倍数越高,然后导致原图画中接近圆心的部分打开后存在显着的锯齿化和阶梯化失真现象。详细地说,因为像素值的不接连性,直接扩大图画会使这种不接连性被扩大。锯齿失真便是因为扩大了图画边际的锯齿状像素发生的;阶梯失真的发生,则是因为不接连的图画梯度边际像素值直接被仿制扩大,使原先并不显着的梯度边际像素值被扩大为肉眼可以分辩的一个接一个的阶梯。
2 算法的改善和硬件完结
考虑到在平面图画的扩大研讨中,为防止图画失真,常选用经典的双线性插值和三次线性差值及其改善算法[5~7]。而全景图画的打开与平面图画的扩大存在不同,每个像素的邻域方位不固定,对错线性的扩大进程。因而经典的差值算法及其改善算法不能运用于全景图画的打开。依据上述全景图画打开的特性,结合FPGA硬件的可完结性,提出算法如下:对打开的图画选用参数可变的高斯空间滤波,其根本思路是对打开后的图画依据锯齿和阶梯失真的程度,运用不同尺度的高斯滤波窗进行空间滤波。
3 硬件体系完结
实时反射式全景视频处理要求高的处理才能。例如,NTSC制式视频规范要求30帧/s,每帧约0.25 M像素,即每秒7.5 M像素流量;PAL制式视频规范要求25帧/s,而每帧的像素数却更多,总的像素流量与NTSC制式根本适当。而对每个像素的处理量取决于选用的详细算法。一般的办法是运用DSP处理器阵列或单片高端DSP完结。考虑到本算法的查找表操作,需求很多的存储器资源,关于DSP处理器来说,因为本钱和空间的约束,需求外接DRAM存储器和杂乱操控逻辑,而外接存储器操控逻辑存在带宽约束,使其成为DSP高速图画处理的首要瓶颈之一。别的,考虑到往后更高分辩率显现导致的更高的数据处理量,DSP的完结计划将愈加难以完结。FPGA供给了可代替的视频处理渠道,FPGA支撑高效并发数据流结构,这关于图画处理算法的实时完结至关重要。此外FPGA内部的嵌入式SRAM存储器是查找表操作的抱负挑选。
3.1 全体硬件体系规划
本体系完结渠道以Altera的FPGA芯片Cyclone II EP2C70F896C6为中心。体系的首要模块结构如图2所示。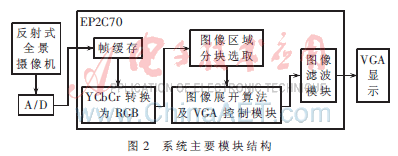
因为平面显现器一次只能显现90°场景,故将全景图画分为四块,待需求显现时再经过打开算法模块进行打开核算并显现。图画打开算法及VGA操控模块为本体系中的中心模块。因为图画打开时有用图画信息占原图的3/4,为了节约资源,本文对分块之后的图画挑选出有用图画部分存入M4K存储器中,运用VGA操控模块发生的VGA队伍扫描信号和正余弦查找表实时发生M4K存储器读地址,完结打开算法。模块结构如图3所示。
3.2 空间滤波器的硬件规划
图4为二维图画滤波器的结构图。输入像素在Line Buffer中前移,发生推迟的一行。Buffer的深度依赖于每一行的像素数。这些推迟的行的像素不断输入滤波器组。在每个滤波器节点,像素被做特定的滤波操作,悉数累加器的成果在地址树叠加后发生滤波器输出。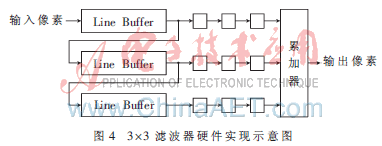
一般硬件履行功率用累加次数来衡量。这样,非对称滤波器的杂乱度就正比于m×m。m×m是卷积和的尺度。锯齿失真噪声按捺功用由m×m的高斯核完结,这个核在图画上按行滑动。所谓参数可变的空间滤波器,即m×m的高斯核尺度是可调理的。考虑到高斯函数的核算触及三角函数运算,每次尺度改动时选用硬件核算生成新的高斯核的办法不当,且跟着高斯核的尺度增大核算时刻也相应增大。为了满意时钟同步的要求就必须供给最大高斯核核算所需的时刻,作为每个高斯核核算的固定延时,这样做显然在小尺度的高斯核核算时刻中存在很多的冗余等待时刻,这对整个体系的实时性十分晦气。考虑视频图画的尺度是必定的,故选用查找表记载高斯核序列,因为高斯核的尺度相关于整幅图画十分小,且其序列个数与图画的行数呈正比,故占用的存储空间也不大。这儿将图画划分为12个横向带状区域,最上方的带状区域选用3×3的高斯核,而下一行则在上一行的基础上+2,以此类推,最终第n带状区域所运用的高斯核的尺度为2n+1=25。
4 试验
4.1 硬件体系实时性
本文中体系的推迟指视频流进入FPGA到VGA显现的时刻差,在体系中表现为A/D输出数据管脚(iTD1_D)上呈现的第一个数据和D/A输入数据管脚(oVGA_R,oVGA_G,oVGA_B)上呈现的第一个数据之间的时刻差。
运用Quartus II中集成的SignalTap在线逻辑剖析仪对体系推迟进行丈量。SignalTap的作用是在体系中增加一个与JTAG接口相连的模块,将用户关怀的管脚数据波形经过JTAG接口上传。因为FPGA芯片内部SRAM的约束使SignalTap数据长度有限,所以本文规划了一个计数器模块对上述时刻差中的体系时钟(iTD1_CLK27,27 MHz)进行计数,然后核算得到体系推迟,以证明本体系的实时性。
因为开机时刻的差错,所以每次核算所得的计数值都不相同。本文对打开前、打开后无滤波和打开后滤波别离试验10次,对一共30次的试验成果进行剖析得到体系推迟。30次试验成果如表1所示。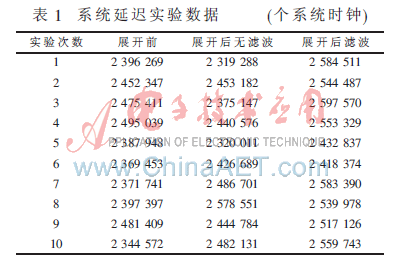
别离取均值后得到打开前数据推迟为2 417 159个体系时钟,即体系推迟为89.254 ms;打开后无滤波数据推迟为2 432 706个体系时钟,即体系推迟为90.100 ms;打开后滤波数据推迟为2 533 135个体系时钟,即体系推迟为93.820 ms。其间打开算法和滤波算法耗时别离为0.846 ms和3.720 ms。直观调查,显现器显现内容的移动和实践物体移动根本一起进行。
4.2 实践显现作用
别离进行直接打开、参数固定和参数可变高斯空间滤波器处理后打开阐明三者差异。
在图5(b)中,打开图画下部锯齿和阶梯失真十分显着;图5(c)中尽管下部锯齿被消除,可是上部图画也变得含糊,图画细节被严重破坏;图5(d)中运用的参数可变高斯滤波器坚持了图画上部的细节,一起消除了下部的锯齿。
本文以ALTERA干流FPGA为开发渠道,完结了对反射式全景摄像机所得的视频流的实时平面打开,并运用参数可变高斯滤波器对打开后发生的锯齿和阶梯失真进行了有用的按捺,一起保留了图画的细节。本体系打开算法耗时0.846 ms,滤波算法耗时3.720 ms,而VGA显现64.4帧/s,均匀每帧为15.528 ms,远远大于本体系算法总耗时4.566 ms。本体系可以在一帧的时刻内完结算法,可以满意绝大多数高速运用的要求。