上节首要介绍在资源受限的ARM设备上,在各种类型的操作体系上的挑选,在C言语编程视点,怎么构建代码才干更好的辅导编译器compiler进行优化,比方数据对齐data alignment,数据类型data type的挑选,C言语函数调用的参数传递办法,以及编译器对结构体和数组的根本处理办法,下节则首要介绍编译器的运用规矩,怎么辅导编译器进行合理的优化,以及体系级的NEON优化,从cache运用到体系功耗操控等。
关键字:ARM Cache 体系 优化 C言语 功率 功耗操控 体系架构 编译器 efficient NEON
C编译器并非一窍不通
简略地说, C编译器并不能依据程序员的代码就彻底了解程序员的实在目的,而且一般为了保证程序的正确履行,一般编译器会做”最坏的”假定。最显着和最著名的比方是”指针的混叠走样”。这意味着编译器有必要做假定经过任何指针的写都或许改动任何一个内存的地址,这对编译器的优化有十分严峻的影响。
其他的比方便是编译器有必要假定大局数据是易挥发的(volatile),在其他函数内,循环计数也是或许会随时被修正的。好消息是在大多数状况下,程序员能够很简略给编译器供给额定的信息来协助编译器优化。在其他状况下,你也能够改写你的代码以更好的表达你的目的和更好的传达特定的条件。例如假如你知道某一特定循环将总是至少履行一次,那么do-while循环将会是比for(;;)是一个更好的挑选。这是因为对C言语的for循环在第一次迭代循环前需求测验是否中止。编译器会因此被迫在两个当地重复测验for的开始和完毕,以保证功用的正确。也会你会说现代的分支猜测硬件支撑会削减这些循环前后的杂乱的分支调整,可是总体上最好的仍是经过给编译器更多的辅导来削减这些不必要的分支。ARM编译器里还有许多关键字来给代码加上许多辅导信息,如下面的__pure, __restrict以及__promise关键字。
__pure:关键字标明函数没有负面影响,没有对大局数据的拜访,即成果只取决于输入参数,两次相同的输入得到的输出也是相同的。
__restrict:该声明用该指针指向区域的写操作不会改动其他指针或许引证指向的数据。这个关键字关于循环优化尤为有用因为它添加了编译器的自由度,编译器就能够采纳一些改换,如unroll等。
__promise:标明在程序的特定规模内,某个条件一向为真,如下面比方中的表达式:

__promise intrinsic这儿告知编译器循环计数器在那个循环内,循环计数器是大于0的,而且能被8整除。这就能让编译器把for循环转化为do-while,而且能够进行把循环打开至多8次而不必忧虑循环鸿沟问题。这种办法特别适用于NEON处理器的向量化操作。
C编译器并非无所不能
C编译器不能彻底的了解程序员的目的,相同C编译器也不是什么事情都能做。C编译器不能发生许多指令,特别是最近ARM架构中引进的指令,这首要因为这些指令的语义跟C言语并不彻底一致。娴熟的程序员能够手艺鞋汇编代码来运用这些新指令,可是运用ARM C编译器供给的丰厚的intrinsic函数将更为简略些。下面的比方是运用ARMv6今后引进的SMUSD和SMUADX指令完结的复数乘法,

一下的代码是汇编的输出

假如编译器能inline内联这些函数,也就没有函数调用的开支了,这也是运用内敛的函数完结相关于写汇编的完结的优势,即坚持代码的可移植性和可读性。
NEON编译器的NEON支撑
C编译器还能经过intrinsic函数和内联的数据类型来直接拜访NEON多媒体处理器的操作。以下是一个数组乘法的直接完结,左面的C代码完结,右侧的是对应的汇编言语。汇编代码只列出了循环核。

下面的一对是相同的循环运用NEON intrinsics的完结和相应的汇编代码。需求留意的是该循环现已打开4次来反映NEON的数据加载、乘法和存储,每次处理都是4个32-bit的带宽。这大幅下降了履行周期。而循环的额定开支也由迭代次数下降而削减。
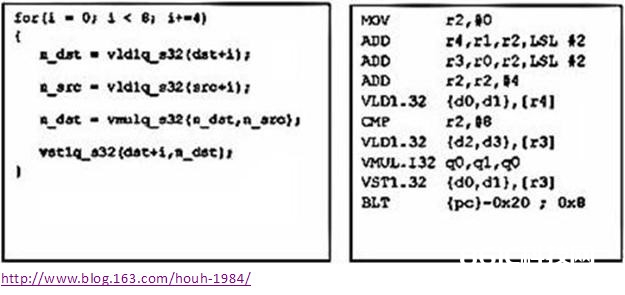
从以上的汇编,假如细心看的话,你会发现编译器并没有发生和C代码彻底一致的代码,这些指令的次第有所改动,这是编译器为了削减interlock然后最大化吞吐。Interlock是由指令的流水线stall发生的。这也是运用intrinsic相关于手写汇编的优势,你能够运用编译器的特性来把C代码周边的环境考虑进来做针对方针渠道的优化。
Data Cache运用
大多数运用程序员往往把cache作为操作体系OS层面需求考虑的问题。当然,cache的装备与办理是操作体系担任的,运用程序一般不允许干与cache操作。但这并不是说运用程序应该彻底忽视体系还存在cache这个现实,了解cache的结构来优化代码将能够供给巨大的功能进步。在写代码时考虑cache怎么操作这些数据将利于代码的功能一致性。
数据结构的对齐到cache行鸿沟将十分利于数据cache line的pre-load,cache需求依据数据拜访的时刻和空间接连性,因此更新数据的时分是依照cache行来更新的,C编译器供给了一个对齐数据到2的幂次的关键字如下所示:
int myarray[16] __attribute__((aligned(64)));
一些十分常见的算法还能够写成cache友爱(cache-friendly)办法以进步功能。众所周知,当数据被接连拜访屡次,这时cache的功能将十分高,因为这些接连拜访的数据此刻现已在cache内了,能够被Core重用(当时,条件是此刻的接连拜访的数据巨细没有超越cache的总巨细)。像矩阵乘法这种常见的算法因为其数据拜访次第会给cache功能带来必定的费事,下面是一个简略的矩阵乘法函数的完结,
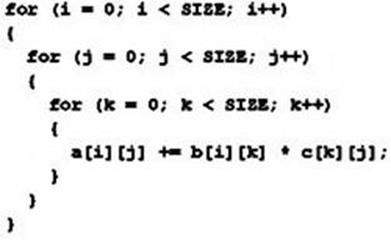
从完结中能够看出,数组a是被依照行接连拜访的因为其最右边的索引改变最快,同理b数组也是接连拜访的,可是数组c的确依照列拜访的,这种依照列跳着读取数据的办法的确不是cache友爱的,因为这种依照列依次读取的会常常更新cache数据因为会导致后边行将要用到的数据从cache空间被铲除出去。尽管运用程序开发时,cache体现往往都是隐含的,但这种功能的丢失的确会带来功耗的添加,因为cache的miss导致对外存的拜访次数添加,而且这些拜访都是burst突发的,因此会添加DDR功耗。有些数据的拜访形式的确十分不利于cache的reuse,这时需求考虑其他的完结尽或许的防止这种数据拜访。如在一个write-allocate的cache体系中,很多数据的写会让cache里堆满了后边不会用到的数据,这些数据一般不会用到,当然一般的cache体系都是可配的read-allocate的。现在的一些高档的ARM cache操控器现已能够处理这种write-allocate的状况,当呈现很多的鞋操作时暂时封闭write-allocate形式,这种主动的调整cache参数是彻底通明的,可是假如写代码时能考虑cache的特性,cache的架构,仍是对高功能代码十分有用的。
大局数据拜访
ARM构架的特点是你不能指定一个完好的32位的地址作为内存拜访的地址,这是因为ARM的指令字长决议的。因此一般拜访一个变量的内存地址需求被放置在一个寄存器或许至少一个开始地址在寄存器中然后加上一个简略的偏移量。这导致了关于每个这样的大局变量编译器在编译时有必要在运转时存储和加载基指针来拜访外部大局变量。假如一个函数拜访外部大局变量十分频频时,编译器需求假定它们在独立的编译单元,因此不能确认在运转时这些大局变量是否能同享同一基址寄存器。因此每个大局变量都需求一个独立的基址指针。假如你能让编译器揣度一群大局变量能共用一个存储器基地址时,他们能够经过基址的不同偏移来拜访。要做到这一点,最简略的办法便是缩小大局变量的规模,只在需求用到的模块里声明,但是不需求大局变量的运用程序少之又少,这并不是一个很切合实际的解决计划。最常见的解决计划是将大局变量或许相关的大局变量组成结构体。这些结构体在编译时能够保证放在一个基址加偏移的地址的。
System power management体系功耗办理
现在咱们转到操作体系层次的更广泛的体系问题。在大多数体系里操作体系操控着比方时钟频率、作业电压、独自core的功率操控状况等。运用程序一般不允许进行这些操控的。有一个最根本的关于功耗的问题一向广为争辩:是先用最快的速度完结核算的作业,然后最长时刻的进入休眠状况仍是把让处理器一向作业在电压和频率都下降的低功耗状况下更为节省功耗。现在这些争辩往往更着眼于日益增长的体系的静态功耗。从历史上看,静态功耗(首要是渗漏)现已大巨细于动态功率的耗费。但是芯片结构变得越来越小,走漏的添加这一现实使的静态功耗日益成为能耗的首要贡献者。现在的定论便是最好是敏捷完结使命,然后关机中止(防止走漏),而不是持续履行更长的时刻。
一个合理的规范
咱们需求的是一个衡量来结合功耗和一个特定的核算需求的运转时刻。这样一个衡量常常被称为”能量推迟积”或EDP(Energy Delay Product.图3所示)。尽管这样的衡量规范现已广泛运用于电路设计许多年,但现在软件开发范畴尚无公认的办法来推导或运用这样一种衡量。
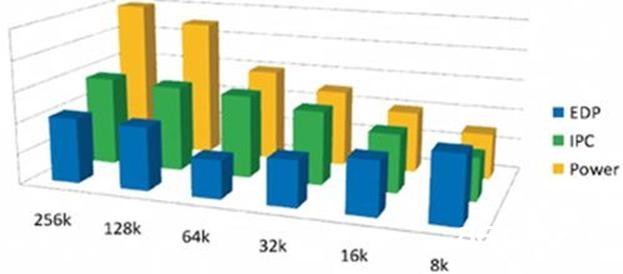
图3.能量推迟积
上面的比方显现[2]在决议cache缓存巨细上EDP衡量所起的辅佐效果。很显着一个更大的缓存会添加功耗。但是EDP衡量标明有一个的在64KB巨细邻近有一个比较合理的方位能取得更高的功能和功耗平衡。
办理子体系sub-systems
在一个单芯片体系里咱们有必要保证额定的核算引擎(如NEON)与外部外设(串口和相似的设备)只在需求的时分才发动。这是操作体系开发者需求考虑的调度问题,也是芯片厂商需求供给办理这些设备的特性。操作体系简直都需求依据特定的硬件渠道进行定制,例如飞思卡尔的i.MX51芯片包括一个NEON的监控器,党用不到NEON时会主动封闭。当碰到没有界说的指令时会经过中止唤醒该协处理器。
在多核体系,咱们能够自己挑选开关单一的中心以匹配体系的负载需求。单一Core的封闭敞开都是体系决议的,现在的ARM对称多核SMP Linux支撑一下特性:
1)CPU热拔插hotplug;
2)负荷平衡以及动态的优先级调整;
3)智能而且cach优化的调度算法;
4)每个cpu core都能动态电压和频率调整Dynamic Voltage and Frequency Scaling (DVFS);
5)每个CPU都有独立的功耗状况办理机制;
内核为通用的外部电源办理操控器装备了一个接口。这个接口需求针对特定渠道台来挑选可运用的特性。如TI的OMAP4渠道供给了再一个规模的电压和频率间调整的选项,经过运转评分(”Operating Performance Points”)体系会主动挑选最适合的功耗计划。这样设备的功耗依据体系负载不同能够从600微瓦到600 mW。
程序员需求做什么
在多核体系中,硬件的高功能或许让咱们决议一切都交给操作体系把,但是在写代码和装备操作体系时假如能考虑如下要素是十分重要的。
1)体系功率(System efficiency):智能和动态的使命优先级调度;负载平衡;
2)核算功率(Computation efficiency):数据,使命和函数等级的并行;削减同步开支overhead
3)数据功率(Data efficiency):有用运用存储体系特性,慎重保护cache一致性以防止cache波动和过错的core间同享。
总结
1)合理装备东西和硬件渠道;2)细心写代码和合理装备装备cache以尽或许削减外部内存拜访;3)速度优化以及合理运用NEON等运算加速器以削减指令履行数;