导言
直方图核算在图画增强和方针检测范畴有重要使用,比方直方图均衡,梯度直方图。直方图的不同品种和核算办法请见之前的文章。本章便是用FPGA来进行直方图的核算,而且使用FPGA的特性对核算进程进行加快。组织如下:
首要依据直方图算法进行FPGA架构规划,这儿首要考虑了怎么加快以及FPGA资源的使用两个要素;最终依据system Verilog建立一个验证体系。
FPGA规划架构
不论是图画灰度直方图仍是梯度直方图,本质上是对数据的散布进行计数。从FPGA视点来看,只关怀以下几点:
1) 依据数据巨细确认其散布区间,核算散布在不同区间的数据个数,区间的巨细能够调理,比方灰度直方图区间为1,梯度直方图一般大于1;
2) 怎么使用FPGA对直方图核算进行加快,以及怎么考虑到芯片有限资源;
首要来考虑加快方法,直方图核算进程用伪代码表明为:
For(int i=0;i Index = get_index(data[i]);
Hist[index]++;
}
Get_index函数是为了确认数据归于哪个区间,假如区间巨细为1,那么index便是数据本身。假如区间是均匀散布,那么就需求进行数据的巨细比较。假如区间巨细是2的幂次,那么index只需求数据进行移位得到。
FPGA在加快计算中最首要便是使用并行化和流水线,并行化便是将一个使命拆解成多个子使命,多个子使命并行完结。而流水线是在处理一个子使命的时分,下一个来的子使命也能够进行处理,处理模块不会等候。流水线本质上是对子使命也进行“切割”,切割的每一块能够在处理模块中一起进行。
核算N个数据,能够将N分红M份,在FPGA上一起进行M个核算,用伪代码表明为:
For(int k=0;k //并行化
For(int i=0;i Index = get_index(data[k][i]);
Hist[k][index]++;
}
}
假如区间不是2的幂次,就需求比较器,这样并行M次,就需求M个平等比较器,这对资源耗费很大。因而现在规划只是支撑2的幂次的区间。整个规划架构如图1.2。
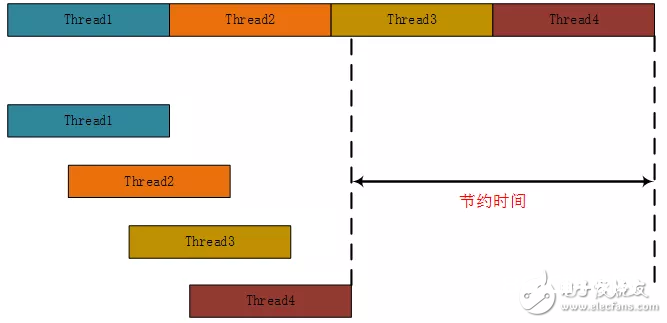
图2.1 流水线处理
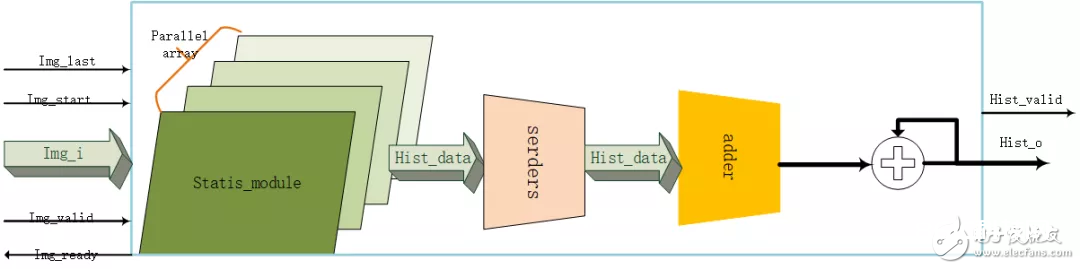
图2.2 直方图核算架构
首要分为以下几个模块:
1)statis:这个是中心核算模块,核算数据散布。ram中寄存直方图核算数据,地址对应着数据散布区间。这儿有一个问题需求考虑,在对ram中直方图核算数据计数时,需求读出然后计数。假如ram读端口没有寄存器,那么读出来直接加1,再写入。可是这样并欠好,由于ram不经过寄存器时序欠好。所以添加了一级寄存器,这样就形成了写入的延时,那么有或许下一次数据降临也会读取相同地址的数据,此刻读取到的直方图数据便是还没有写入的。为了处理这个问题,判别进入的前后两个数据是否相同,假如相同就不写入而持续计数,假如不同就写入。并行多个staTIs模块的代码为:
genvar i;
generate
for(i=0;i
staTIs #(
.PIX_BW(PIX_BW),
.HIST_BW(HIST_BW),
.ADDR_BW(HIST_LEN_BW),
.BIN_W(BIN_W)
)u_staTIs(
.clk(clk),
.rst(rst),
.clr(clr),
.enable(1‘b1),
.pix_valid(pix_valid),
.pix(img_i[i*PIX_BW +: PIX_BW]),
.hist_rd(branch_hist_rd),
.hist_raddr(branch_hist_raddr),
.hist(branch_hist[i*HIST_BW +: HIST_BW])
);
end
endgenerate
2)serders:这个是并转串。M个staTIs模块会发生M组hist成果,这些成果还要进行求和,那么就要用到加法树,假如M较大,会形成加法树很大,多以这儿加了serders能够调理加法树资源。
3) addTree:加法树。
module addTree #(
parameter DATA_BW = 32,//bit width of data
parameter TREE_DEPTH = 3,//depth of the add tree
parameter ADD_N = 4//add number
)
(
input clk,
input rst,
input [ADD_N*DATA_BW-1:0] adnd_x,
input [ADD_N*DATA_BW-1:0] adnd_y,
input adnd_valid,
output reg[DATA_BW-1:0] finl_sum,
output reg finl_sum_valid
);
reg [TREE_DEPTH-1:0]midl_valid;
genvar dept_i, leaf_i;
generate
for(dept_i=TREE_DEPTH-1;dept_i》=0;dept_i=dept_i-1)begin: ADD_DPET
localparam LEAF_N = 2**dept_i;
wire[DATA_BW-1:0] midl_sum[LEAF_N-1:0];
for(leaf_i=0;leaf_i
reg [DATA_BW-1:0] midl_add_x;
reg [DATA_BW-1:0] midl_add_y;
if(dept_i==TREE_DEPTH-1)begin
always @(posedge clk)begin
midl_add_x midl_add_y end
end
else begin
always @(posedge clk)begin
midl_add_x midl_add_y end
end
adder #(
.DATA_BW(DATA_BW)
)
u_adder(
.adnd_x(midl_add_x),
.adnd_y(midl_add_y),
.sum(midl_sum[leaf_i])
);
end
if(dept_i==TREE_DEPTH-1)
always @(posedge clk)begin
midl_valid[dept_i] end
else
always @(posedge clk)begin
midl_valid[dept_i] end
end
endgenerate
always @(posedge clk)begin
finl_sum end
always @(posedge clk)begin
if(rst)
finl_sum_valid else
finl_sum_valid end
endmodule
4) accum:累加器。假如加法树没有完结M个hist数据的求和,那么就需求经过累加器来完结。
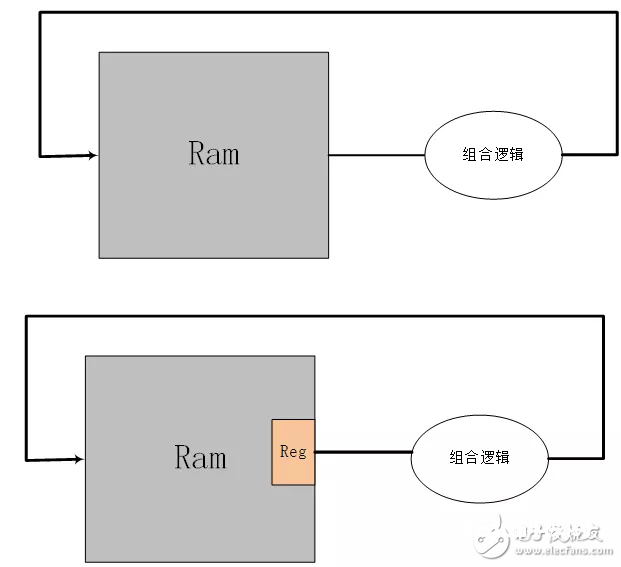
图2.3 对ram的处理
验证结构
1) img_trans:这个是随机化图画数据界说,首要经过SV中constraint来对图画巨细做一些束缚;
class img_trans;
rand int img_w;
rand int img_h;
rand int img_blank;
rand logic[`PIX_BW-1:0] img[`MAX_IMG_W*`MAX_IMG_H];
constraint img_cfg_cnst{
img_w img_w 》 0;
img_w % `PARALL == 0;
img_h img_h 》 0;
img_blank img_blank 》= 0;
}
extern function void write(input string f_name);
endclass
2) driver:发生image而且发送给DUT,一起经过mailbox发送给ref_model用于比照;
class img_obj;
logic [`PIX_BW-1:0] img_que[$];
endclass
class driver;
int img_w;
int img_h;
int img_blank;
logic [`PARALL*`PIX_BW-1:0] img;
logic [`PIX_BW-1:0] img_ele;
img_obj imgObj;
img_trans imgTrans;
extern task drive(mailbox img_mbx, virtual img_inf.test imgInf);
endclass
3) ref_model:自己核算直方图和DUT的成果进行比对;
class ref_modl;
logic [`PIX_BW-1:0] img;
int addr;
img_obj imgObj;
int hist[`HIST_LEN];
extern task calc(input logic clk, mailbox img_mbx);
extern task comp(virtual img_inf.test imgInf);
extern task run(input logic clk, mailbox img_mbx, virtual img_inf.test imgInf);
extern function void clear();
endclass
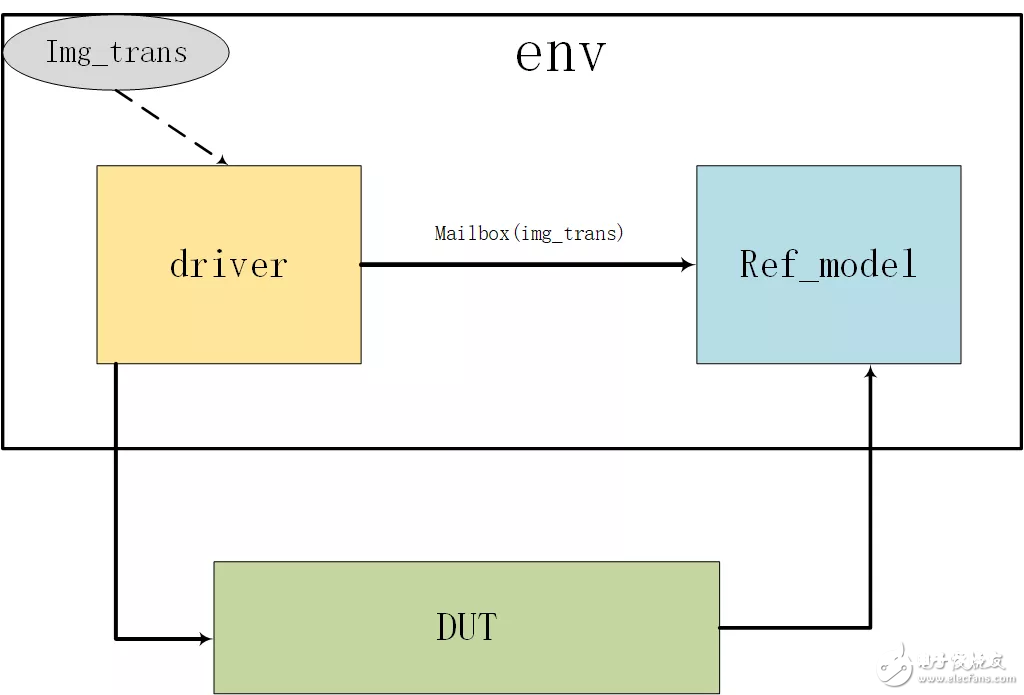
图3.1 验证架构图
最终添加一下modelsim仿真波形文件和成果,朴实为了添加篇幅。
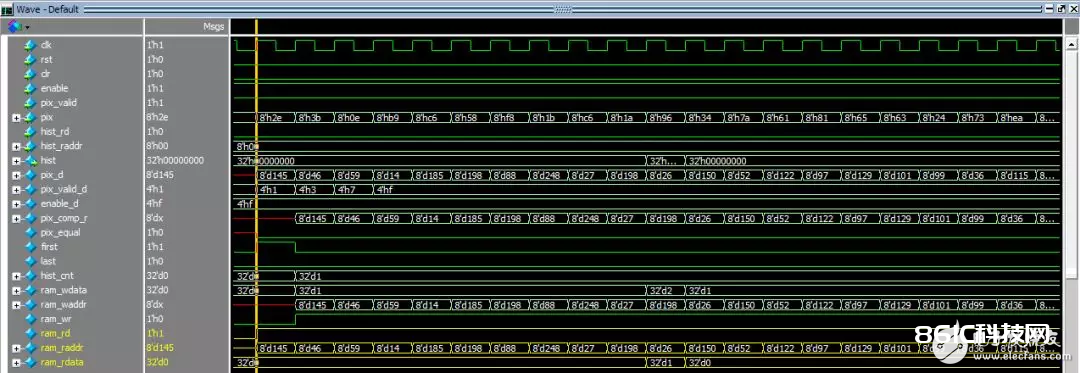
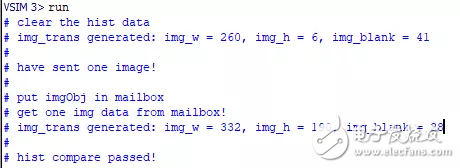
图3.2 modelsim仿真波形和成果