0 导言
在航空航天、医疗服务、地质勘探等杂乱运用领域,需求处理的数据量急剧增大,需求高功能的实时核算才干供给支撑。与多核处理器比较,众核处理器核算资源密度更高、片上通讯开支明显下降、功能/功耗比明显提高,可为实时体系供给强壮的核算才干。
在杂乱运用领域傍边,不同运用场景对核算的需求或许不同。例如,移动机器人在作业时,或许需求一同履行途径规划、方针辨认等多个使命,这些使命需求一同履行;在对遥感图画处理时,需求对图画数据进行配准、交融、重构、特征提取等多个进程,这些进程间既需求一同履行,又存在前驱后继的联系。因而,依据众核处理器进行核算形式的动态结构,以习惯不同的运用场景和运用使命成为一种新的研讨方向。文献[1]研讨了具有逻辑核结构才干的众核处理器体系结构,其基本思想是依据多个细粒度处理器核构建成粗粒度逻辑核,将不断添加的处理器核转化为单线程串行运用的功能提高。文献提出并验证了一种依据类数据流驱动模型的可重构众核处理器结构,完结了逻辑核处理器的运行时可重构机制。文献 提出了一种支撑核资源动态分组的自习惯调度算法,经过对使命簇的拆分与兼并,动态构建可弹性分区的核逻辑组,完结核资源的阻隔优化拜访。
GPGPU(General – Purpose Computing on GraphicsProcessing Units)作为一种典型的众核处理器,有关研讨多面向单使命并发履行方面的优化以及运用算法的加快。本文以GPGPU为渠道,经过研讨和规划,构建了单使命并行、多使命并行和多使命流式处理的多核算形式处理体系。
1 众核处理机
1.1 众核处理机结构
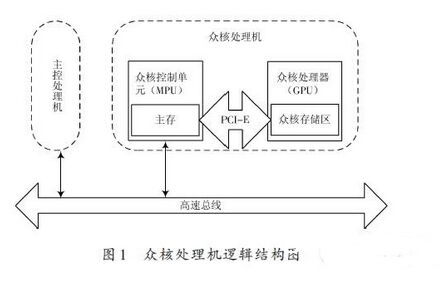
众核处理机是依据众核操控单元(MPU)与众核处理器(GPGPU)相结合的主、协处理方法构建而成,其逻辑结构如图1所示。众核处理机由众核操控单元和众核核算单元两部分组成,其间众核操控单元选用X86结构的MPU,与众核核算单元之间经过PCI-E总线进行互连。
1.2 CUDA流与Hyper-Q
在一致核算设备架构(Compute Unified Device Ar-chitecture,CUDA)编程模型中,CUDA流(CUDA Stream)表明GPU的一个操作行列,经过CUDA流来办理使命和并行。CUDA 流的运用分为两种:一种是CUDA 在创立上下文时会隐式地创立一个CUDA流,然后指令可以在设备中排队等候履行;另一种是在编程时,在履行装备中显式地指定CUDA 流。不论以何种方法运用CUDA流,一切的操作在CUDA流中都是依照先后次序排队履行,然后每个操作按其进入行列的次序脱离行列。换言之,行列充当了一个FIFO(先入先出)缓冲区,操作依照它们在设备中的呈现次序脱离行列。
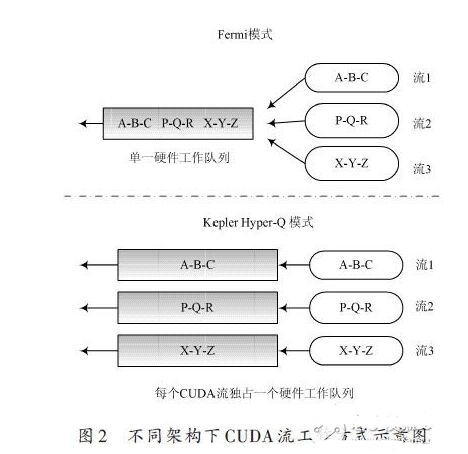
在GPU 中,有一个CUDA 作业调度器(CUDA WorkDistributor,CWD)的硬件单元,专门担任将核算作业分发到不同的流处理器中。在Fermi架构中,尽管支撑16 个内核的一同发动,但由于只要一个硬件作业行列用来衔接主机端CPU 和设备端GPU,形成并发的多个CUDA 流中的使命在履行时有必要复用同一硬件作业行列,产生了虚伪的流内依靠联系,有必要等候同一CUDA流中相互依靠的kernel履行完毕,另一CUDA流中的ker-nel才干开端履行。而在Kepler GK110架构中,新具有的Hyper-Q特性消除了只要单一硬件作业行列的约束,添加了硬件作业行列的数量,因而,在CUDA 流的数目不超越硬件作业行列数目的前提下,答应每个CUDA流独占一个硬件作业行列,CUDA流内的操作不再堵塞其他CUDA流的操作,多个CUDA流可以并行履行。
如图2 所示,当运用Hyper-Q 和CUDA 流一同作业时,虚线上方显现为Fermi形式,流1、流2、流3 复用一个硬件作业行列,而虚线下方为Kepler Hyper-Q 形式,答应每个流运用独自的硬件作业行列一同履行。
2 众核多核算形式处理结构
为了充分发挥众核处理器的核算才干,众核处理体系面临不同的核算使命的特色,可构建三种核算形式,即单使命并行核算、多使命并行核算、多使命流式核算。
2.1 众核多核算形式处理体系结构
众核多核算形式处理体系结构如图3 所示。众核处理体系包含数据通讯、使命办理、形状办理、资源办理和操控监听模块。
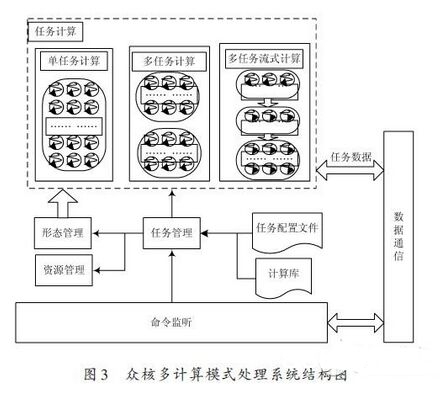
数据通讯模块:供给接口给主控机,担任接纳从主控机发送来的使命指令和使命核算所需的使命数据,而且最终将众核处理机运算完结的核算成果经过该模块回来给主控机。
操控监听模块:在众核处理体系运行时,实时获取主控机发送给众核处理机的使命指令,将其传送给使命办理模块,并接纳使命办理模块回来的使命指令履行成果。
使命办理模块:担任核算使命的加载进程,将操控监听模块发送来的使命指令存于使命行列,当众核核算单元需求加载使命进行核算时,从使命行列中获取使命指令,依据使命指令从使命装备文件中获取使命核算所需的使命信息,该使命信息包含了核算使命运行时所需的存储空间巨细、适合于该使命的核算形式、履行函数(即CUDA中的kernel函数)等内容,在核算使命在被加载前,需求告诉形状办理模块把众核核算单元切换到指定的核算形式下,并告诉资源办理模块分配存储空间,经过数据通讯模块获取使命数据,然后读取使命核算库,加载履行函数进行核算。
形状办理模块:接纳使命办理模块发送来的方针核算形式,切换到该种核算形式。
资源办理模块:依据使命办理模块发送的参数分配存储空间,包含众核操控单元的存储空间和众核核算单元的存储空间,众核操控单元的存储空间用于对使命数据进行缓存,然后经过数据传输的API接口把缓存在众核操控单元的数据传送到众核核算单元的存储空间,在核算时由从众核核算单元存储空间加载数据进行核算。