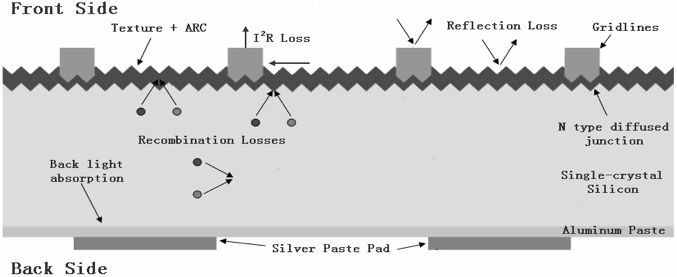
Socionext和大阪大学数据才能科学研讨所日前开发了一种深度学习办法,能够在极低光线条件下进行图画辨认和方针检测。
经过兼并多个模型,新办法能够在不生成很多数据集的情况下检测方针。
Socionext方案将这种新办法融入公司的图画信号处理器中,以开发新的SOC,以及环绕这些SOC的新摄像头体系,用于轿车、安全、工业和其他需求高功能图画辨认的运用。
在核算机视觉技能发展过程中,一个首要的应战便是怎么进步轿车摄像头和监控体系在恶劣照明条件下的图画辨认功能。
此前,运用传感器原始图画数据进行深度学习的办法,称为“在漆黑中学习看东西”。这种办法需求一个包括超越200000个图画的数据集,其间超越150万个注释用于端到端学习,用原始图画预备如此大的数据集既费钱又费时。联合研讨小组提出了新的范畴习惯办法,即运用现有的数据集,运用搬运学习、常识蒸馏等机器学习技能,树立一个所需的模型
新办法经过以下过程处理了这一难题:
(1) 运用现有数据集树立推理模型,
(2) 从上述推理模型中提取常识,
(3) 经过胶合层兼并模型,
(4) 经过常识蒸馏树立生成模型。它能够运用现有的数据集学习希望的图画辨认模型。
运用这种域自习惯办法,该团队运用在极点漆黑条件下拍照的原始图画,树立了一个方针检测模型“漆黑中的尤洛”,运用YOLO模型。
运用已有的数据集能够完成对原始图画方针检测模型的学习,而无需生成额定的数据集。
与现有的YOLO模型在图画亮度增强无法检测到方针的情况下不同,提出的新模型使原始图画辨认和方针检测成为可能。
这个模型所需的核算资源大约是基线模型的一半,该模型运用了曾经模型的组合。
这种办法的“原始图画的直接辨认”有望与其他许多运用一同,用于极暗条件下的方针检测。
Socionext方案将这种新办法融入公司的图画信号处理器中,以开发新的SOC,以及环绕这些SOC的新摄像头体系,并为轿车、安全、工业和其他需求高功能图画辨认的运用供给处理方案。