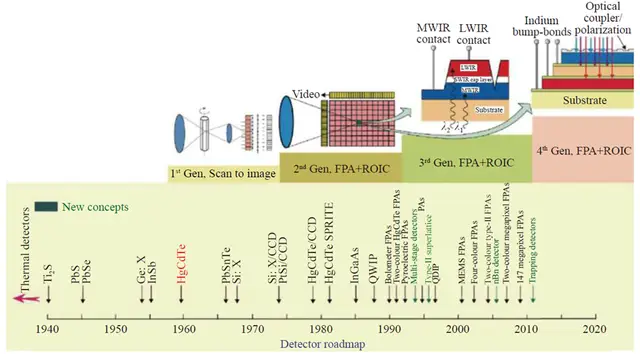
摘要 针对FFT算法依据FPGA完结可装备的IP核。选用依据流水线结构和快速并行算法完结了蝶形运算和4k点FFT的输入点数、数据位宽、分化基自在装备。运用Verilog言语编写,运用ModelSim仿真,由ISE综兼并下载,在Xilinx公司的Virtex-5 xc5vfx70t器材上以200 MHz的时钟完结验证,运算成果与其他规划的运算功率比照有必定优势。
在现代声纳、雷达、通讯、图画处理等领域中,数字信号处理体系常常要进行高速、高精度的FFF运算。现场可编程逻辑阵列(FPGA)是一种可定制集成电路,具有面向数字信号处理算法的物理结构。用FPGA完结FFT处理器具有硬件体系简略、功耗低的长处,一起具有开发时刻较短、本钱较低的优势。依据FPGA完结的数字信号处理体系具有较高的实时性和嵌入性,并能方便地完结体系集成与功用扩展。依据FPGA的硬件完结FFT一般有两种办法:(1)并行办法,其选用多个蝶形处理器并行运算,能对较高的数据采样率进行运算,但其硬件规划较大,当在FPGA上要完结较大点数的FFT时较为困难。(2)串行办法,选用一个蝶形处理器完结运算,运用的逻辑资源较少,但运算速度较慢。本文在串行办法的基础上完结了一种在FPGA上完结的可装备FFT IP核,具有输入点数可装备(完结0~4 096点自在装备)、数据位宽可装备、分化基可装备的特性。
1 原理剖析
自从基2快速算法呈现以来,人们仍在不断寻求更快的算法。基4 FFT算法比开端的基2 FFT算法更快,但从理论上讲,用较大的基数还可进一步削减运算次数,但要以程序(或硬件)变得更杂乱为价值。进步FFF处理速度的4个首要技能途径是选用流水线结构、并行运算、添加蝶形处理单元数目和高基数结构。
1.1 基2算法基本原理
点数N是2的整数次幂,将x(n)先按n的奇偶分红两组

1.2 基4算法基本原理
与基2算法相似,关于N点有限长序列x(n)的DFT依照时域分化打开有
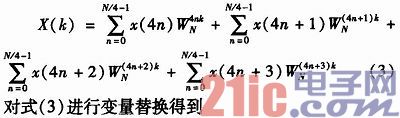
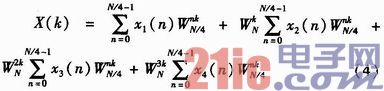
2 可装备FFT IP核硬件结构
现有的FFT IP核在硬件完结时不具备并行度可装备才能,只提供全循环、全流水、循环打开与流水结合等方法下的某种特定完结,可重用性较差,难以习惯不同的核算吞吐量和对核算资源和核算时刻的需求。可装备FFT IP核技能完结FFT算法流水、循环等并行化参数的可装备问题,统筹FFT转化点数、输入输出数据位宽、蝶形运算基数、输入输出FIFO深度的可装备,满意不同使用条件下IP复用的需求,习惯各种环境和数据吞吐量的FFT运算。可装备FFTIP核功用组成如图1所示。

如图1所示,该IP首要包含RAM、ROM、地址发生模块、移位模块、挑选数据排序模块、可装备蝶形运算单元、精度调整模块和输出数据排序模块,Din_R和Din_I是FFT输入数据的实部和虚部,Dout_R和Dout_I是FFT改换成果的实部和虚部。RAM1和RAM2存储了FFT迭代进程中的输入数据,RAM3和RAM4存储了FFT迭代进程中的核算成果,RAM1和RAM2、RAM3和RAM4均为乒乓结构。地址发生模块首要发生向RAM写入数据和从RAM读出数据的地址。ROM中存储了FFT需求的旋转因子。
2.1 IP核全体计划
规划可装备FFT处理,其全体结构如图2所示,规划选用基2蝶形和基4蝶形运算两种装备方法,供用户挑选。输入数据实部和虚部分隔存储,需4个RAM,为完结对连续流输入可连续流输出,其模块构成如图2所示。
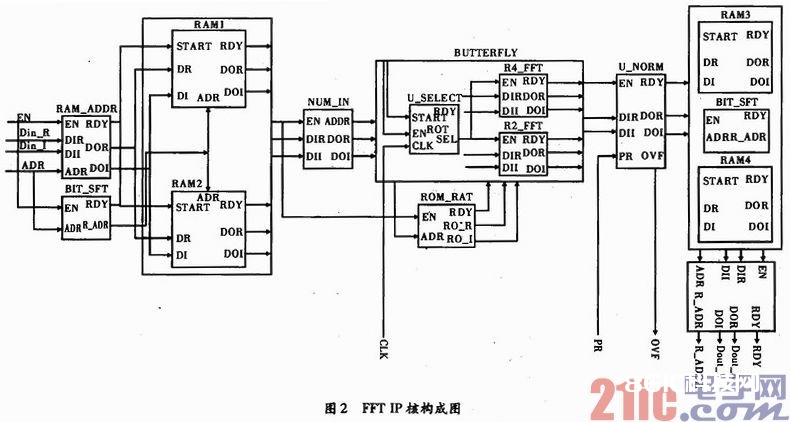
如图2所示,外部输入数据的实数部分Din_R、虚数部分Din_I,以及输入数据的地址信号ADR,首要进入RAM_ADDR单元,挑选适宜的时钟周期将不同点数的原始数据送入RAM单元,当输入数据的实数和虚数以及其地址准备好的时分,RDY输出1。BIT_SFT单元完结输入数据地址的移位改换,完结奇偶别离。当数据地址准备好时,RDY输出1,当RAM_ADDR或BIT_SFT这两个单元中的一个单元准备好时,便可触发RAM单元,将外部数据写入到RAM的指定地址。RAM中的数据契合可装备点数要求后,进入NUM_IN单元,其间输出的数据DOR/DOI便是契合基2蝶形或基4蝶形运算的数据次序。这些原始数据进入蝶形运算单元BUTTERFLY,蝶形单元经过U_SELECT单元挑选蝶形运算的分化基,完结基2蝶形运算、基4蝶形运算的可装备功用。其间R4_FFT是基4蝶形运算单元,B2_FFT是基2蝶形运算单元,蝶形运算进程中所需的旋转因子存储在ROM_RAT单元中,依据挑选不同分化基的蝶形运算,BUTIERFLY单元发生相应的地址,挑选其核算进程中的旋转因子。当蝶形运算完结后,成果数据进入U_CNORM单元,进行次序调整和精度处理;其间PR信号是用户指定的精度信号,PR[1:0]可提供3种精度,OVF信号是数据溢出信号,若置1标明FFT成果数据超出了表明规模,则要依照截位处理以确保数据精确。当数据输入完结后,成果数据进入NUM_OUT单元,因为DIT算法输出成果以倒序方法输出,一切需求NUM_OUT进行地址调整,FFT改换完毕后的成果实数部分Dout_R,虚数部分是Dout_I,地址信号是R_ADDR,以正确的次序和方法输出。
2.2 可装备蝶形单元模块
在FFT IP核的蝶形运算单元规划中,蝶形单元的运算进程:第一个时钟周期是将下结点与旋转因子复乘的实数乘法进行核算;第二个时钟周期是将复乘中的实数进行加减运算;在第三个时钟周期是核算复乘成果与上结点的加减运算,行将蝶形运算单元的成果输出。可装备蝶形运算经过在基2和基4两种分化基之间切换来完结,其模块图如图3所示。
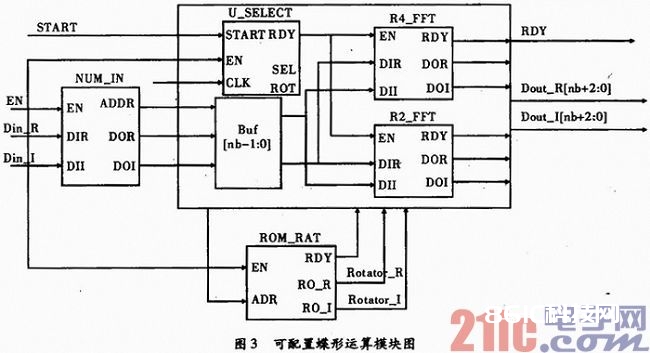
如图3所示,数据输入时能信号EN信号置1,则整个蝶形运算单元的数据输入模块NUM_IN、旋转因子模块ROM_RAT、分化基挑选模块U_SELECT进入使能状况;START信号置1,则分化基挑选单元U_SELECT模块开端进入状况机。依据用户设置,假如挑选基2算法蝶形运算单元,则将输入数据的实部和虚部送入R2_FFT模块;假如挑选基4算法蝶形运算单元,则将输入数据的实部和虚部送入R4_FFT模块;假如挑选混合基,则需求在状况机中参加判别条件,精确操控分支。当蝶形运算完结时,FFT运算成果数据的实数部分Dout_R[nb+2:0],虚数部分Dout_I[nb+2:0]比输入数据的位数[nb:0]扩展了3位,用于精度调整模块进行精度操控。
蝶形运算的旋转因子存储在ROM_RAT中,其间存储了基4运算和基2运算的旋转因子,实部和虚部分隔存储,经过外部信号EN对其使能,为操控ROM存储空间的占用,不同分化基的旋转因子可共用,经过地址信号ADR选取操控。
3 仿真、归纳成果剖析与验证
将规划的IP核进行依据ModelSim的仿真,设置时钟频率为200 MHz,数据位宽为36位,在基2和基4两种分化基下,剖析1 024点和4 096点的运算功率,其仿真图画如下所示。
图4是1 024,点的基2算法仿真成果,在这种算法下完结数据录入的时刻点为113.1μs,完结成果输出的时刻点为123.4μs,运算时刻为10.3μs。图5是1 024点的基4算法仿真成果,在该种算法下完结数据录入的时刻点51.3μs,完结成果输出的时刻点是61.6μs,运算时刻为8.3 μs。
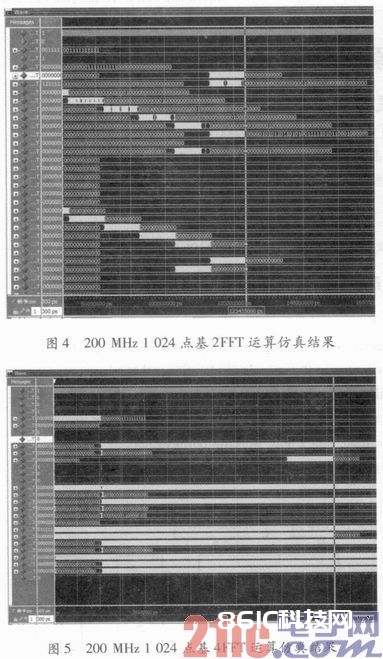
图6是4 096点的基2算法仿真成果,在这种算法下完结数据录入的时刻点533.1μs,完结成果输出的时刻点是574.1μs,运算时刻为40 μs。图7是4096点的基4算法仿真成果,在该种算法下完结数据录入的时刻点为245.7 μs,完结成果输出的时刻点是286.9μs,运算时刻为41.2μs。


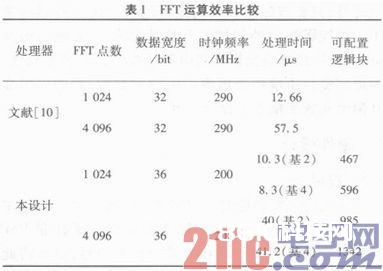
板级验证选用Xilinx公司的Virtex-5 xc5vfx70t器材进行归纳、布局布线和时序剖析。将得到的数据与其他规划完结进行比较,其耗费的资源,以及在200 MHz时钟情况下不同点数的FFT处理器进行一次处理需求的时刻,与文献换算后得到的数值比照如表1所示。
4 完毕语
本文规划的可装备FFT IP核具有灵活性强、简略扩展和规划可复用的特色,完结分化基可装备、位宽可装备、输入输出点数可装备。从验证成果能够看出,本文数据的可装备IP核具有结构简略及占用硬件资源恰当的特色,在FPGA中以完结高速数字信号处理,在处理速度和灵活性方面更有优势。跟着处理点数的添加,其优越性将愈加显着。