所谓报文内容过滤,望文生义是对IP包数据段的载荷进行过滤,过滤规矩是字符串方式的数据内容。以IDS体系为例,管理员依据所把握的侵略状况事先为体系设定侵略规矩,这些规矩的一个重要组成部分便是IP数据载荷的某些内容,具体体现为字符串。当体系接纳到一个IP包后,IDS的内容过滤部分就会用自身的体系算法将规矩库中的字符串逐一和包的内容匹配,一旦匹配了某个字符串,则证明匹配了相应的规矩。
跟着网络信息杂乱化以及安全需求多样化,对报文内容过滤的需求也愈加火急。首先从安全视点来看,防火墙和侵略监测体系急需高功率的报文内容过滤算法。因为当今的侵略行为和攻击方式更具有杂乱性,首要体现在数据载荷的内容中呈现特征字符串,例如蠕虫病毒“Nimda”、“Code Red”、“Slammer”都包括特别的字符串;从网络运用来看,运用于深度报文分类的路由设备、流量操控等相同需求取得而且对IP数据内容分类,例如一些多媒体数据、P2P数据都含有特定的字符串信息作为自身的标识;别的从信息获取的视点来看,技侦范畴和数据开掘怎么从海量数据中开掘有用信息和情报资源,相同需求内容过滤。
1、内容过滤的代表算法
1.1 AC算法
AC算法即由Aho和Corasick提出的多形式匹配算法(即一次查找查找能够断定多个字符串匹配问题)。简略地说,AC 算法运用了有限主动机的结构来接纳并存储规矩库中一切的字符串。主动机是结构化的,这样每个前缀都可用仅有的状况来标识,乃至是那些多个形式的前缀,这样杂乱的前缀就能够简略的转化为状况机中的一个状况。当文本T中下一个字符不是形式中预期的下个字符中的一个时,会有一条失利链指向那个状况,代表最长的形式前缀,一起也是当时状况的相应后缀。在实践中,咱们设定三个函数:状况搬运函数goto()、成功匹配输出函数output()、匹配失利跳转函数failure()。
1.2 王的多形式匹配算法
王永成教授等人规划了更多重视了多形式匹配过程中字串之间的彼此联系,对AC算法进行了改善0。算法在主动状况机思维的基础上,运用了BM算法0的跳转思维,即利用了匹配过程中匹配失利的信息,越过尽可能多的字符。完结了快速的多形式匹配算法。在匹配的过程中,相同运用goto()函数搬运当时状况,在找到匹配成果之后output()函数输出成功信息。而在匹配失利的时分,运用skip函数大幅度划文本T,削减goto()函数的调用次数,然后进步过滤功率。
1.3 Bloom Filter算法
Bloom Filter法开始多用于数据库存储和查询结构,近年来也运用于IP包内容过滤等范畴。Bloom Filter算法的原理是找到k个hash函数,其值域都是{1,2,…,m}一起设定一个形式矢量M,其长度为m。关于规矩库P中的每个形式,核算 hash1(p)、……、hashk(p) ,每次核算所得的 hashx(p)依据其数值对应到形式矢量的相应方位。这样,一个形式经过k个hash函数核算所得k个值,从而对应到形式矢量的k个方位,构成一个形式矢量。在查找的过程中,在文本中取出同p相同长度的字符串,经过k个hash函数核算后生成其相应的形式矢量,用这个形式矢量和库中的各个形式矢量比较,能够确认是否匹配。
1.4 Dharmapurikar的算法
Dharmapurikar 等人修改了根本的AC算法,并引入了Bloom filter,规划了依据硬件的匹配计划。该算法拓宽了AC状况机的输入带宽,从1byte扩展到Gbyte。相应的状况机内部对一个状况改动也要判别一组Gbyte的数据。而关于文本T尾部缺乏Gbyte的部分,选用并行的G-1个过滤单元,专用于过滤剩下长度为1、2、……、G-1的部分。而在状况搬运的过程中,运用了Bloom Filter过滤掉了不可能发生状况搬运的输入,极大地进步了匹配功率。而关于数量很少的状况搬运操作,经过查找off-chip的存储单元中的hash表来确认状况搬运和相应的匹配成果。本文在此基础上作进一步研讨。
2、内容过滤算法描绘
2.1 算法的并行结构
关于字符串匹配而言,一个匹配单元是1-byte,这样一个匹配模块一次的输入为1byte。假如能够将输入带宽从1-byte拓宽到G-byte的话那么过滤速率明显也相应的进步了G倍。
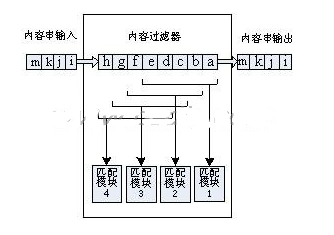
图1 一个G=4的内容过滤器
图1以一个G=4的实例说明晰并行内容过滤器的算法结构。过滤器由四个完全相同的过滤模块并行组成,其间每个模块一次接纳必定长度(B)的字串,进行过滤核算,下个周期接纳下一组B长的字串。而关于整个过滤器而言,每个周期流入Gbyte的数据,流出Gbyte的数据。以过滤模块1为例,当时窗口接纳串为“abcde”,下一个周期窗口内的串为“efghi”。尽管关于每个模块而言,每次会改动G=4个字节,可是因为存在了并行的4个模块,且每个模块的判别窗口都距离1byte,这样就不会漏掉数据流中的任何一个方位。假如规矩会集含有字符串“cdefg”的话,那么明显模块3对当时窗口过滤之后会给出一个匹配成果,而其他三个模块都不会有匹配成果发生。这样的并行结构经过运用处理方位上彼此比邻的G个匹配模块,处理了主动状况机模型中关于输入字串1byte的约束,展宽了过滤带宽,从而进步了过滤速率。
2.2 匹配模块的内部结构
图1中的一个匹配模块是一个独立的内容过滤单元,也是一个独立的状况机转化单元。其内部依据输入的G-byte的字串核算状况搬运以及匹配的射中成果。下面介绍一个匹配模块的原理结构。
图2所示的是一个4byte宽的状况机模型,状况的每次搬运都需求4byte的数据(≤4)。例如,判别S6=“elephant”,在当时状况q0的状况下,输入串为“elep”时,状况搬运q0—〉q4,接着输入“hant”,状况搬运到q7,此刻有匹配的成果输出。而一般的状况机,需求8次的状况搬运。
在过滤的过程中更多的规矩串并不是B的倍数,例如“phone”,在第一次状况搬运中因为“phon”的存在由q0搬运到q3,尔后至需求判别下个输入中是不是后缀“e***”就能够判别是否射中了s5,相同还有“technically”中的后缀“lly”等。对长度为1到B-1之间的后缀,选用并行的B-1个后缀判别子模块。一起注意到关于长度恰好是B的整数倍的规矩串,能够了解成有一个长度为0的后缀,这样便于同上述并行的B-1个后缀判别子模块一起组成B个并行的运算结构。图3给出了一个B=4的状况下的一个匹配模块的结构,其间4个Bloom Filter别离处理后缀长度为0、1、2、3的状况。然后经过查表得到状况搬运联系以及成果输出状况。
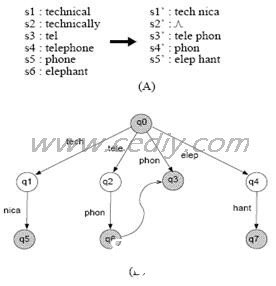
图2 一个4byte宽(B=4)的状况机
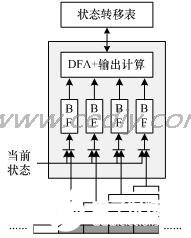
图3 B=4状况下的一个匹配模块
2.3 运用Bloom Filter
如前文所述,因为状况搬运表占用很大的存储空间,需求运用off-chip的RAM来保存。而通常状况下外部存储器的读取带宽很小,不能支撑一个模块的B个查表要求。其实在真实状况中只要很少的状况下才会有状况的转化,这时运用Bloom Filter来滤掉很多的不会发生状况改动的输入。一个状况搬运联系能够标明成:
《当时状况,输入字串》 ==〉《下个状况,输出信息》
所以能够对2元组《当时状况,输入字串》进行hash运算,用成果查找状况搬运hash表,找到2元组《下个状况,输出信息》。Bloom Filter的效果便是滤掉很多不会查找到成果的元组,只在当时《当时状况,输入字串》有可能在hash表中查到成果的时分才答应对应项查找状况搬运表。这样极大地削减了查表次数,进步了算法速率。
2.4 Hash函数的硬件完结办法
关于Bloom Filter中运用的hash函数,要求易于硬件,占用尽可能少的时钟周期。H3算法供给了一个很好的处理计划。设子串的第i个字节为《bi1、bi2、……、bi8》,则这个方位上的一个hash值为:
hi=di1•bi1⊕di2•bi2⊕……⊕di8•bi8
其间dij是一个预设的随机矩阵的一个值。这样,从1到i的hash值为:
Hi=Hi-1⊕hi
可见,方位i上的hash函数能够经过i-1方位上的hash函数简略的算出。而且假如dij=di+1j的话,可见t时间的hi和t+1时间的hi-1是相同的,这样一切Hi就能够经过并行的移位结构在一个时钟周期内完结,而不必等候Hi-1的核算成果。相应的结构如图4所示,算法能够在一个时钟周期内算出一切Hi的值,十分快捷。
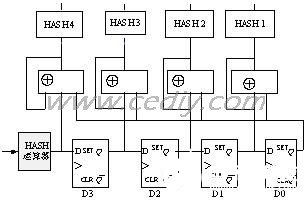
图4 硬件Hash函数的逻辑结构
3、FPGA完结
本文的试验体系运用的是Altera公司StratixII系列的EP2S60FPGA芯片。该芯片具有2.5Mb的片内RAM空间,能够支撑最多两个独立off-chip的DDR或QDR单元。输入信号是经过前端处理的POS信号,解为整载的IP报文数据。规矩随机地取自IDS体系SNORT的2000条规矩。
在完结的过程中运用8个并行的过滤模块,也便是每次输入8byte的数据。尽管更高的并行数量会进步体系的处理带宽,可是也相应需求占用更多的RAM空间,这儿考虑到SNORT的规矩相对较短(多散布在5-15byte),选用8byte并行的算法。Bloom Filter由6个并行的hash函数构成,每个hash函数对应的hash表选用2kbit,这样总共占用了2kbit*6*8*8=768kbit的片内RAM资源,约占总量的30%。经过核算,这样的Bloom Filter规划能够确保经过过滤操作之后,只要6e-10的假匹配存在(即对应的hash值标明当时元组《当时状况,输入字串》能够发生正确的状况搬运,然而在off-chip的RAM中找不到对应项)。这儿需求提一下,因为8个并行模块是同构的,其hash表也是相同的,假如运用时分的hash表查找办法或许Lucent memory core能够占用更少的RAM资源。
当试验体系FPGA作业在77MHz的状况下的时分,能够正确无误的过滤2.5Gpbs的IP报文数据。因为该算法运用的RAM和时钟频率都没有到达额定值,一起,内部Bloom Filter和状况搬运表的构成相同有待进一步优化,所以本文算法具有进一步晋级的潜力。
4、定论
本文针对现在网络传达速率急剧添加,数据处理规矩规划巨大的特色,提出了依据FPGA的IP报文内容过滤算法。本文在当时多种优异的内容过滤技能的基础上,充分利用了FPGA芯片高速并行处理和流水线操作的特色,提出运用并行的移位模块来拓宽过滤算法的处理带宽,使得算法支撑的IP报文速率得到了很大的进步。一起,为处理off-chip的RAM读取带宽受限的瓶颈,以及在状况搬运过程中读取下一个状况需求占用额定的时钟周期的问题,提出了用Bloom Filter过滤掉不会发生状况搬运的输入字串,进一步进步处理速率。别的,规划了仅需求一个时钟周期就能够完结hash核算的硬件电路,而且经过改善,能够在一个时钟周期内得到一切后缀长度的hash值,使得算法在FPGA中的流水功能增强。最终经过在试验体系中的测验,在77MHz的时钟下能够正确的过滤2.5Gbps的IP报文,而且有进一步晋级的潜力。
责任编辑:gt