本文经AI新媒体量子位(大众号 ID: QbitAI)授权转载,转载请联络出处。
一只萌新,想把自己修炼成一个老练的NLP研究人员,要通过一条怎样的路?
有个名叫Tae-Hwan Jung的韩国小伙伴,做了一份完好的思想导图,从根底概念开端,到NLP的常用办法和闻名算法,知识点全面掩盖。
能够说,从0到1,你需求的都在这儿了:
这份精美的资源刚刚上线,不到一天Reddit热度就超越400,取得了连篇的赞许和谢意:
“肥肠感谢。”“我需求的便是这个!”“哇,真好啊!”
所以,这套丰富的思想导图,都包含了哪些内容?
四大版块
就算你早年什么都不知道,也能够从第一个版块开端入门:
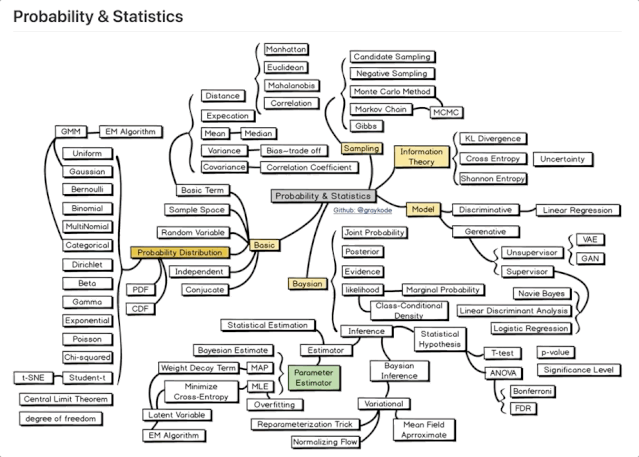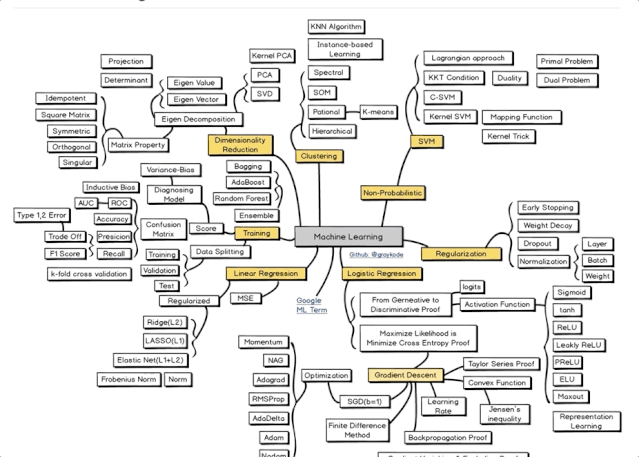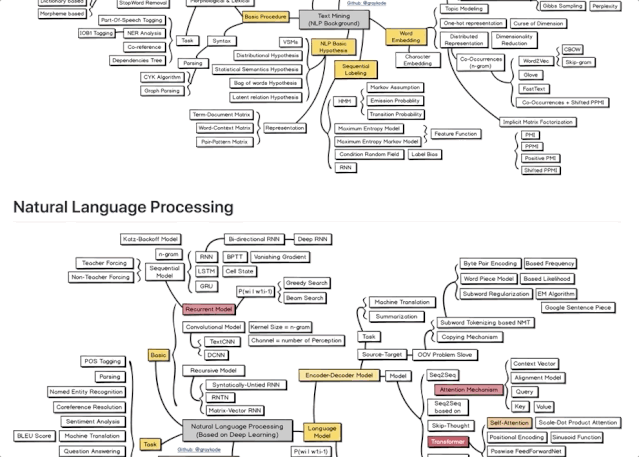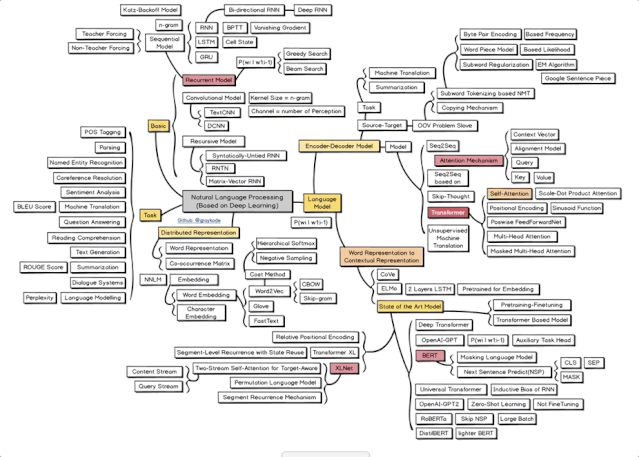
1 概率&计算
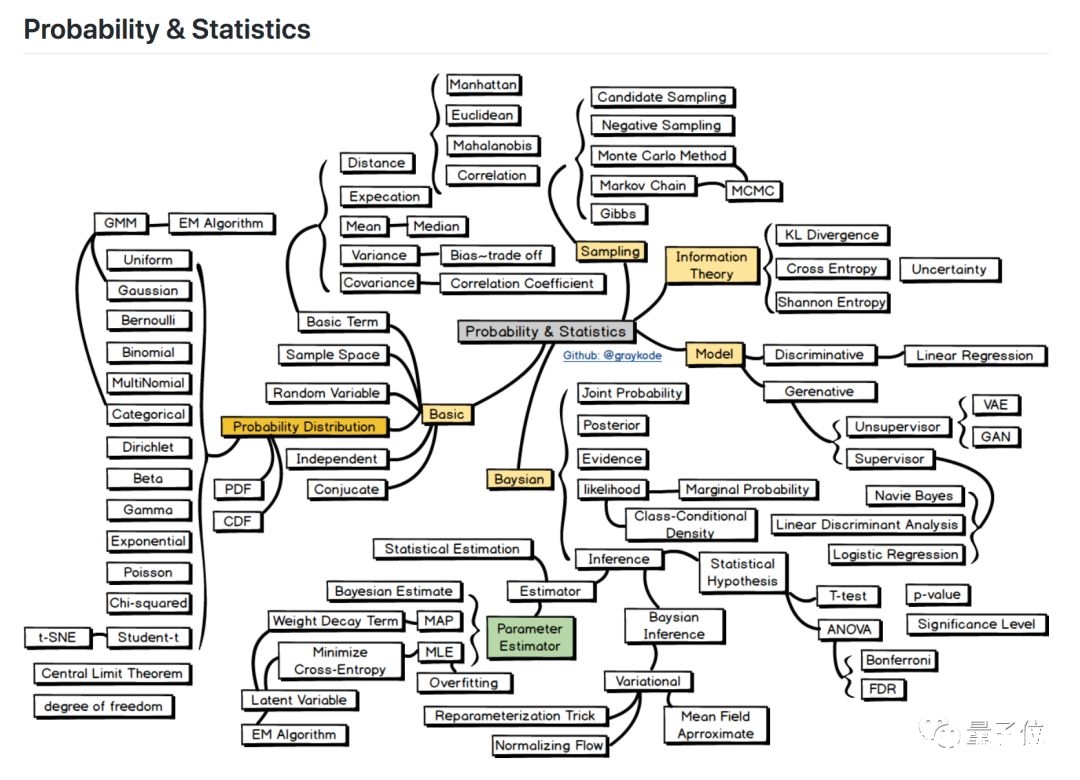
从中心的灰色方块,发散出5个方面:
根底 (Basic) ,采样 (Sampling) 、信息理论 (Information Theory) 、模型 (Model) ,以及贝叶斯 (Baysian) 。
每个方面,都有许多知识点和办法,需求你去把握。
究竟,有了概率计算的根底,才干昂首阔步进入第二个板块。
2 机器学习

这个版块,一共有7个分支:
线性回归 (Linear Regression) 、逻辑回归 (Logistic Regression) 、正则化 (Regularization) 、非概率 (Non-Probabilistic) 、聚类 (Clustering) 、降维 (Dimensionality Reduction) ,以及练习 (Training) 。
把握了机器学习的根底知识和常用办法,再正式向NLP进发。
3 文本发掘
文本发掘,是用来从文本里取得高质量信息的办法。

图上有6个分支:
根本流程 (Basic Procedure) 、图 (Graph) 、文档 (Document) 、词嵌入 (Word Embedding)、序列标示 (Sequential Labeling) ,以及NLP根本假定 (NLP Basic Hypothesis)。
汇集了NLP路上的各种必备东西。
4 自然言语处理
装备齐了,就该实践了。这也是最终一张图的中心思想:
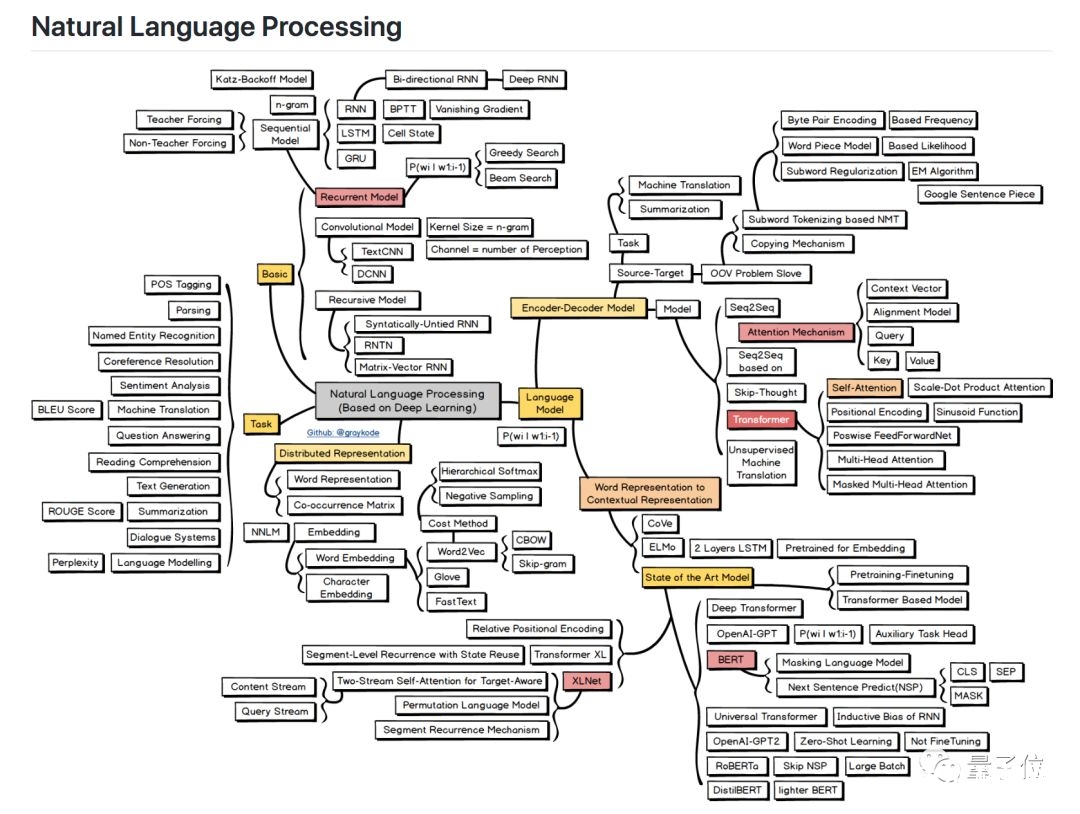
尽管只要4个分支,但内容丰富。
一是根底 (Basic) ,具体梳理了NLP常用的几类网络:循环模型、卷积模型和递归模型。
二是言语模型 (Language Model) ,包含了编码器-解码器模型,以及词表征到上下文表征 (Word Representation to Contextual Representation) 这两部分。许多闻名模型,比方BERT和XLNet,都是在这儿得到了充沛拆解,也是你需求努力学习的内容。
三是分布式表征 (Distributed Representation) ,许多常用的词嵌入办法都在这儿,包含GloVe和Word2Vec,它们会一个个变成你的好朋友。
四是使命 (Task) ,机器翻译、问答、阅览了解、心情剖析……你已经是合格的NLP研究人员了,有什么需求,就调教AI做些什么吧。
看完脑图,有人问了:是不是要把各种技能都完成一下?
韩国少年说:“不不,你不必把这些全完成一遍。找一些感觉风趣的,完成一波就好了。”

△ 作者Tae-Hwan Jung,来自庆熙大学
One More Thing
Reddit楼下,许多小伙伴对这套脑图表明崇拜,而且想知道是用什么做的。
韩国少年说,Balsamiq Mockups。
GitHub传送门:https://github.com/graykode/nlp-roadmap
Reddit传送门:https://www.reddit.com/r/MachineLearning/comments/d8jheo/p_natural_language_processing_roadmap_and_keyword/