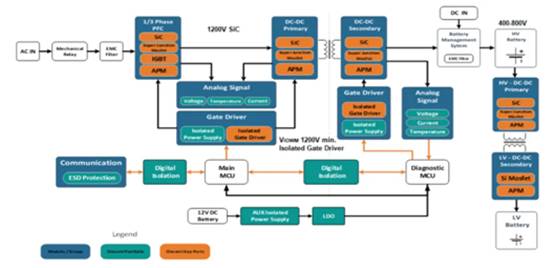
根据 Spartan 6 的实时运动分类体系为人群的主动监测和监控拓荒新途径。
人群的监控与监测现已成为当时的一个重要范畴。政府和安悉数分都现已开端寻求在公共场所智能监测人群的更先进的办法,然后防止在来不及采纳举动之前检测到任何反常活动。但是在有用到达这一意图之前还需求战胜一些妨碍。例如,假如需求一天 24 小时一同监测整个城市里一切或许的人群活动,仅靠全人工监测是不或许的,尤其在装置有数千部 CCTV 摄像头的状况下更是如此。
这个问题的处理计划在于开发全新的智能摄像头或视觉体系,凭借先进的视频剖析技能主动监测人群的活动,然后可以当即向中心操控站陈述任何反常事情。
规划这种智能摄像头/视觉体系不只需求规范的成像传感器和光学设备,还需求高功用视频处理器来履行视频剖析作业。运用这种功用强大的板载视频处理器的原因在于先进视频剖析技能具有较高的处理要求,大多数此类技能通常会运用核算密布型视频处理算法。
FPGA 十分合适于此类高功用要求的运用。凭借赛灵思 Vivado® Design Suite 中高层次归纳 (HLS) 功用完结的 UltraFast™ 规划办法,现在可以为 FPGA 轻松创立抱负的高功用规划。此外,赛灵思 MicroBlaze™ 等嵌入式处理器与 FPGA 可重装备逻辑的完美交融,让用户现在可以将具有杂乱操控流的运用方便地移植到 FPGA 上。
鉴于这种状况,咱们运用 Vivado HLS、赛灵思嵌入式开发套件 (EDK) 和 ISE® Design Suite 中根据软件的EDA东西,规划出一种用于人群运动分类和监测体系的原型。这种规划办法根据咱们所以为的软件操控和硬件加速架构。咱们的规划选用低成本的赛灵思 Spartan®-6 LX45 FPGA。咱们在较短时刻内即完结了整体体系规划,其在规划的实时功用、低成本和高灵敏性方面均展现出颇有远景的效果。
运用加权肯定差之和 (SWAD),咱们核算出图画上散布的 900 多个运动向量。
体系规划
整体体系规划分两个阶段完结。榜首阶段是开发人群运动分类算法。在这个算法的验证完结后,接下来是把它完结到 FPGA 中。在开发的第二阶段,咱们首要重视根据 FPGA 的实时视频处理运用的架构规划方面。具体作业包含开发实时视频流水线、开发硬件加速器,终究将二者集成并完结到算法操控和数据流中,然后完结体系规划。
下面介绍每个开发阶段,首要从扼要介绍算法规划开端,然后具体介绍如何将算法完结到 FPGA 渠道上。
算法规划
就人群监督和监控而言,文献中提出了多种算法。大多数此类算法从在人群场景中检测(或安置)特征点开端,然后随时刻推移盯梢这些特征点,收集运动核算数据。随后把这些运动核算数据投射到一些之前预先核算好的运动模型上,用来猜测任何反常活动 [1]。进一步改进包含集合特征点,盯梢这些集群而非独自的特征点[2]。
本文的人群运动分类算法根据相同的概念,除了咱们优先运用模板匹配办法进行运动估量,而不是选用 Kanade-Lucas- Tomasi (KLT) 特征盯梢器等传统办法。该模板匹配办法经验证标明,添加一些核算量能明显改进低对比度或对比度不断改变状况下的运动估量。
为将这一办法用于运动估量,咱们将视频帧划分为更小矩形贴片组成的网格,然后运用根据加权肯定差之和 (SWAD) 的办法对每个贴片的当时图画和之前图画进行运动核算。每个贴片相应地供给一个运动向量,用于阐明该特定方位两帧之间的运动规模和方向。效果便是需求在整个图画上核算超越 900 个运动向量。核算这些运动向量触及的具体进程如图1所示。
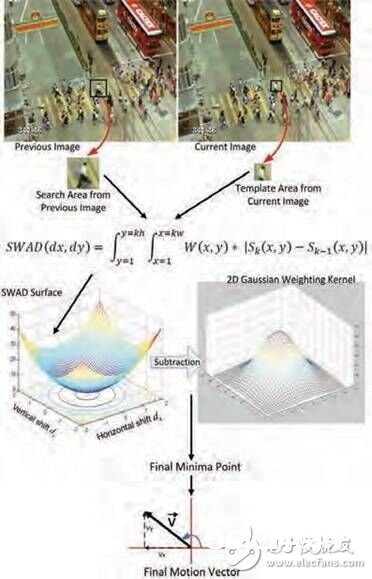
图 1:核算运动向量的进程,从图画收集开端(上)
此外,咱们运用加权高斯内核完结图画中遮挡区和零对比度区的可靠性。并且,用于核算一个运动向量的一个贴片处理作业独立于其它贴片的处理作业,因而该办法十分合适运用 FPGA 上的并行完结计划。
在核算完好个图画上的运动向量后,该算法随即核算它们的核算特色。这些特色包含均匀运动向量长度、运动向量数量、运动的主导方向和相似目标。
其他咱们还核算了运动向量方向的 360 度柱状图,进一步剖析其规范误差、均匀误差和误差系数等特色。这些核算特色随后被投射到预先核算好的运动模型上,然后将当时运动分类到几大类别之一。随后咱们运用多个帧来解说这些核算特色,然后承认分类效果。
预先核算好的运动模型选用加权决策树分类器的方法构建,其充分考虑了这些核算特色来对所调查到的运动进行分类。例如,假如调查到运动速度快并且场景中有动量骤变,一同运动方向随机或超出图画平面,就可以分类为或许的惊惧状况。该算法的开发作业运用微软 Visual C++ 合作 OpenCV 库完结。算法的完好演示请参阅本文文末供给的 Web 链接。
FPGA 完结计划
体系规划的第二阶段是该算法的 FPGA 完结进程。 这一步完结作业有它自己的规划难题,例如 FPGA 规划现在要包含视频输入/输出和帧缓存。此外,有限的资源和可用功用或许需求必要的规划优化。
鉴于这些规划特色和其它架构考虑,整个 FPGA 完结计划被分为三个部分。榜首部分是在 FPGA 上开发通用的实时视频流水线,用于处理必要的视频输入/输出和帧缓存。第二部分是开发算法专用硬件加速器。终究在规划的第三阶段,咱们把它们集成到一同,完结算法操控和数据流。这就完结了整个根据 FPGA 的体系规划。
下面临这个进程的每一阶段进行更具体的介绍。
实时视频流水线
在为 FPGA 渠道开发任何视频处理运用时,实时视频流水线都是最重要的构建模块。这个流水线对用户躲藏了视频输入/输出和帧缓存相关的杂乱存储器办理作业,而是供给了简略的拜访界面以供用户处理视频帧数据。
虽然在这方面貌前有几种先进的、商业答应的视频流水线[3],咱们挑选构建针对这个用处的定制视频流水线。咱们根据赛灵思 EDK 构建该流水线,运用定制视频收集/显现端口处理视频输入/输出数据。这个流水线也可以方便地进行装备,然后用于其它赛灵思 FPGA 系列。
视频收集端口担任解码来自视频 ADC 的输入视频流数据并在本地缓存。随后该数据被转发至主存储器,用于创立视频帧。与此相似,视频显现端口担任对本地缓存中存储的视频帧数据进行编码,然后将其转发到视频 DAC 中供显现运用。视频输入输出端口衔接到 MicroBlaze 主机处理器的主外设总线,该处理器担任处理与主存储器之间的视频数据流量。
视频端口可以生成中止,以告诉 MicroBlaze 处理器在视频输入端口有可用的新数据或视频输入端口需求新数据。两种视频端口选用“往复式”缓存办理计划,这样即使是 MicroBlaze 处理器都无法当即呼应视频端口,也不会发生缓存溢出或欠载。图2所示是视频端口与 MicroBlaze 处理器之间的互联。
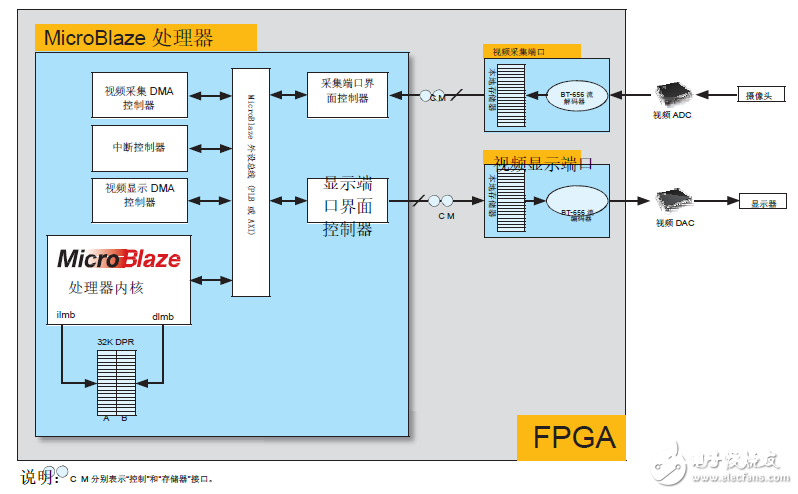
图 2:视频端口及其互联
视频端口规划用于检测和生成视频行数量、场 ID(假如是隔行视频)和视频输入/输出流中的其它操控信息。当有满足数量的视频数据被视频输入端口缓存,或当视频显现端口恳求的数据到达满足数量时,该信息就会经过视频端口的中止服务例程 (ISR) 传递给 MicroBlaze 处理器。这些服务例程相应地经过 DMA 完结视频端口本地存储器和主存储器之间的视频数据传输。
除了视频端口 ISR,还有咱们称之为“视频帧行列 API”的一套高档视频帧行列办理功用在这些 ISR 和用户层运用之间作业。该 API 担任保持多个收集帧和显现帧的行列,以支撑双帧或三帧缓存计划。在MicroBlaze上运转的用户运用能轻松取得视频收集帧,或运用“视频帧行列 API”功用供给视频显现帧。图 3 显现了在层级结构中各级其他相关功用。
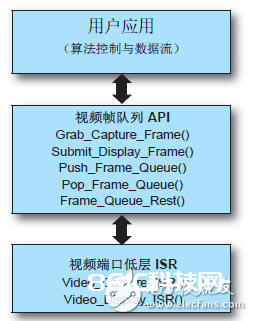
图 3:视频端口 ISR 和视频帧行列 API 功用
将 MicroBlaze 用作主机处理器以衔接体系中的各个构建模块能发生很多优势。例如咱们可以运用 MicroBlaze 方便地衔接各种外部存储器(SRAM、SDRAM 等),加载或存储来自视频端口的视频帧数据。相似地,咱们可以运用 EDK 中的 DMA 操控器,在视频端口和主存储器之间传输视频数据。此外,咱们还可用 MicroBlaze 处理器以相同办法衔接定制硬件加速器。
这些“视频帧行列 API”功用加上视频端口 ISR 和视频输入输出端口让规划中的视频处理流水线的结构愈加完善。图 4 所示的是运用 FPGA 上的本视频流水线收集、处理和显现实践的视频帧。它还显现了经过核算出的运动向量缩小视图完结的画中画功用。

图 4:右下被运动向量网格掩盖的、经过 FPGA 处理后的实践帧
根据 Vivado HLS 的硬件加速器
在前文介绍的人群运动分类算法中,最为耗时、核算最密布的作业是核算运动向量。另一项体系作业——进行分类——因不触及像素级的处理,十分简略并且易于完结。注意到规划的这个方面,咱们为核算运动向量构建了一个硬件加速器。咱们凭借赛灵思 Vivado HLS,用 C/C++ 言语在 RTL 中对该加速器进行了规划、测验和归纳。
Vivado 生成的 RTL 代码的要害特征之一是其在很大程度上现已过了精心优化。Vivado HSL 把阵列存取(例如存储在阵列中的像素数据)归纳到存储器接口中,经过剖析代码主动生成所需的地址。Vivado HSL 还可剖析预先核算好的偏移和常量,然后十分快速地履行所谓的“跨步式”存储器拜访。跨步式存储器拜访从图画的多行数据拜访开端(就如同在 2D 卷积中)。
规划根据 Vivado 的加速器的首要考虑要素是并行处理运动向量的核算,最大极限地进步从主存储器中的数据读取。为此意图,咱们运用八个 Block RAM 并行加载和存储视频帧数据。硬件加速器的内核可以并行核算四个运动向量,并且在核算中它会用到一切八个 Block RAM。从主存储器传输到这些 Block RAM 的数据由 MicroBlaze 经过 DMA 加以操控。
Vivado HLS 生成的硬件加速器具有部分主动生成的握手信号,这些信号关于启停硬件加速器必不可少。 这些握手信号包含“发动”、“繁忙”、“搁置”、“完结”等标志。这些标志经过 GPIO 传送到 MicroBlaze 处理器以完结握手。图 5 所示为该硬件加速器、八个 Block RAM 和 MicroBlaze 处理器主外设总线之间的互联。
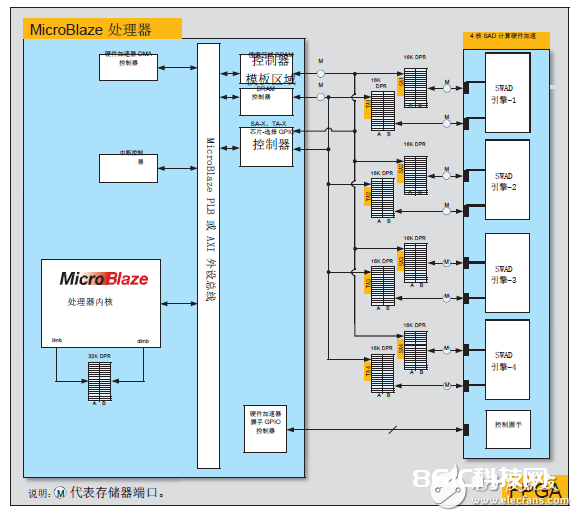
图 5:根据 Vivado HLS 的硬件加速器及其互联
图 5 平分别被命名为 SA1、TA1 到 SA4、TA4 的这些 Block RAM,每个的容量为 16KB。每对 SA1、TA1 到 SA4、TA4 可以保存核算一个完好行的运动向量所需的数据。因而硬件加速器在完结运转后,会输出四行运动向量写回到相同的 Block RAM 存储器中。这些核算完的运动向量随即由 MicroBlaze 处理器读回,然后把效果以运动向量网格的方法复制到自己的主存储器中。(图 4 所示的是被硬件加速器核算出的运动向量网格掩盖的实践帧)
该硬件加速器在 200MHz 频率下作业,核算整个图画的运动向量所需的悉数处理使命可以在缺乏 10 毫秒内完结,包含与存储器之间的一切数据来往传输。
算法操控和数据流
在视频流水线和硬件加速器开发安排妥当后,完结该体系的终究一步是把这两个单元与 MicroBlaze 主机处理器集成,并运用赛灵思软件开发套件 (SDK_,用 C/C++ 完结用户层运用的算法操控和数据流。 在赛灵思 SDK 中完结算法操控和数据流能为规划带来极大的灵敏性。这是由于用户可以用相同的办法规划和集成新的硬件加速器,一同还可以修正必要的操控和数据流以集成新的硬件加速器。终究得到的便是一种软件操控、硬件加速的规划,其灵敏度可比美纯软件完结计划,一同其功用可比美纯硬件完结计划。
本文介绍的人群运动分类算法的操控和数据流从经过视频帧行列 API 功用收集视频帧开端。当视频帧获取结束,用户运用把当时的和之前的视频帧数据传输到硬件加速器,完结运动向量的核算。
此刻体系在软件中核算运动向量的核算特色和分类效果。这样做的原因是这些进程不触及任何像素级处理,只会添加很少的处理开支。当分类效果核算完结时,用屏幕显现(OSD)功用把效果和运动向量显现在处理后的帧上。这些屏幕显现功用也是在赛灵思 SDK 顶用 C/C++ 言语完结的。
这些构建模块(实时视频流水线、硬件加速器和算法操控/数据流)悉数安排妥当后,整体体系规划即告完结。随后咱们对根据 FPGA 的完结计划进行了测验,并与之前的桌面 PC 型完结计划比较效果的准确性。两个效果是完全一致的。咱们运用来自明尼苏达大学数据库( http://mha.cs.umn.edu/proj_recognition.sht- ml )和来自www.gettyimages.com 的各种测验视频对本体系进行了测验。
完结计划效果
整个规划只运用了 Spartan-6-LX45 FPGA 上 30% 的Slice LUT、60% 的 BRAM 和12% 的 DSP48E 乘法器资源。图 6 所示是硬件设置(上)和实践体系输出。硬件设置由 Digilent Atlys Spartan 6 FPGA 板和定制视频接口卡组成,运用视频 ADC 和 DAC 可为 FPGA 供给视频输入/输出功用。如欲观看该体系的具体演示视频,敬请拜访下列 Web 链接:
http://www.dailymotion.com/video/x2av1wo_fpga-based-real-time-hu-man-cro.。.
http://www.dailymotion.com/vid-eo/x23icxj_real-time-motion-vec-tors-comp.。.
http://www.dailymotion.com/video/x28sq1c_crowd-motion-classifica-tion-us.。.
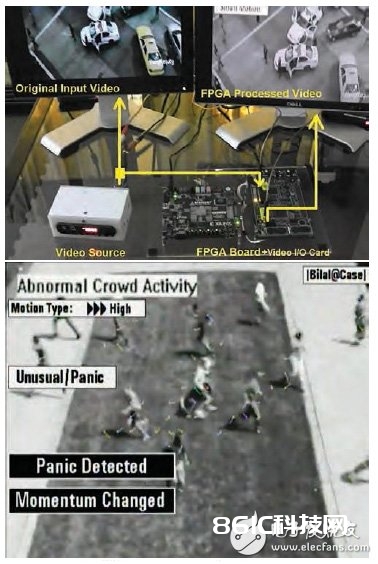
图 6:硬件设置(上)和把场景分类为惊慌的实践 FPGA 处理后的帧
巨大的未来潜力
FPGA 是面向实时视频处理等需求高功用的运用的抱负渠道。开发这种运用要求进行必定的架构考量,以充分发挥所选 FPGA 的功用优势。此外运用 EDK 和 Vivado HLS 等先进东西,可以以比过去高得多的功率和更短的开发时刻完结整体体系规划。
因而正如咱们在本文中所展现的,运用上述东西在 FPGA 上完结功用要害型运用有着巨大的潜力。有这样成功运转的渠道作为先例,咱们希望把这一效果推行用于处理更多的技能问题,例如主动化交通监测、医院中的主动病患调查等更多的运用。
参考资料
1. Ramin Mehran、Mubarak Shah,《运用社会力模型检测反常人群行为》,IEEE 核算机视觉与模式识别 (CVPR) 国际会议,迈阿密,2009年
2. Duan-Yu Chen、Po-Chung Huang,《根据运动的人群反常事情检测》,《视觉核算和图画显现期刊(Journal of Visual Computation and Image Representation)》,2011 年第 2 期第 22 卷,第 178-186 页
3. OmniTek OSVP:http://omnitek.tv/sites/ default/files/OSVP.pdf
道谢
作者在此道谢合著者 Shoab A. Khan 教授奉献的巨大构思以及 Darshika G. Parera 博士和 Umair Ahsun 博士给予的出色创意。
作者:Muhammad Bilal 在读理科硕士 先进工程研究中心,巴基斯坦伊斯兰堡 bilal.case.edu@gmail.com
Shoab.A. Khan 教授 先进工程研究中心( www.case.edu.pk ) 巴基斯坦伊斯兰堡 shoab@case.edu.pk