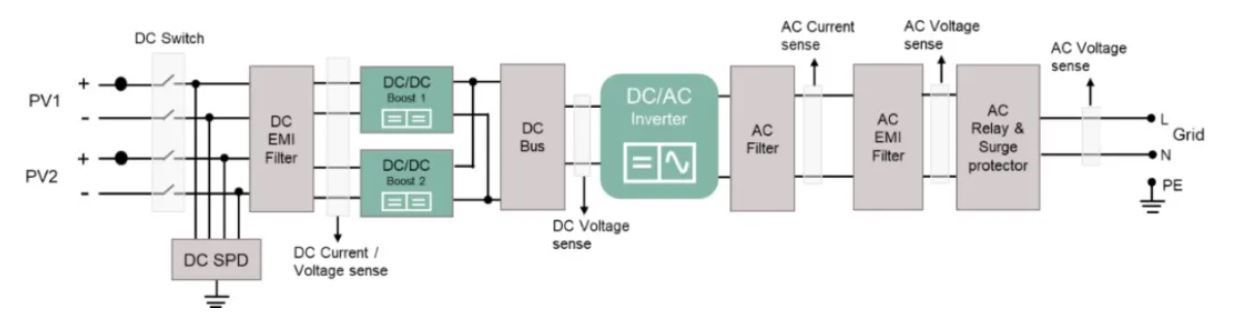
导言
跟着信息技术的不断发展和网络技术的不断遍及,种 类繁复、敏捷便利的电脑文娱已然成为人们日常日子中必不 可少的重要组成部分。在许多日常休闲文娱活动中,电脑休 闲游戏凭仗它的便利性、益智性、互动性、简略性等许多优 点,成为榜首挑选。
作为中华文化博学多才的代表之一,我国象棋不只流 传长远,并且东西简略,操作便利,是一项很好的智力运 动,可丰厚文化日子,陶冶情操,培育品质,开发智力,启 迪思维。下我国象棋时,赤色方先走,黑色方后走,之后红 黑两方轮番走。当一方的将(帅)被对方的棋子吃掉,又或 者某一步之后将帅相互直接会面,又或许是被困得现已无棋 可走时,便是对方赢棋。两边下棋时,为了打败对方,有必要 细心慎重地考虑对方的走法,多揣摩两边下面几步,这样棋 局才会愈加精彩美观。两边斗智斗勇轮番走棋,称为博弈。
1 极大极小算法(minmax algorithm)
极大极小算法一直站在博弈一方的立场上给棋局估值, 有利于本方的棋局给予一个较高的价值分数,不利于本方( 有利于对方)的给予一个较低的价值分数,两边好坏不明显 的局势则给予一个中心价值分数。在本方行棋的时分,挑选 价值极大的子节点走棋,对方行棋则挑选价值极小的子节点 走棋,这便是一个极大极小进程。为表述便利,咱们将实施 极大值查找的一方称为max方,另一方称为min方。Shannon 在1950年首要提出了极大极小算法,然后奠定了核算机博弈的理论基础。
2 Alpha-Beta查找算法
Alpha-Beta查找:通过向子结点传递Alpha和Beta值,引 发剪枝,Alpha表明本方最优值,跟着查找不断变大,所以 开端一般取无穷大。Beta表明对方最坏值,随查找不断变 小,初始时取正无穷大。剪枝的功率直接影响了Alpha-Beta 查找功率,剪枝越多,功率越快。假如每个结点在查找榜首 个子结点时就发生剪枝,则查找的结点数到达最小;假如剪 枝发生在每个结点的最终一个子结点上,则等同于没有剪 枝,查找的结点数到达最大。
3 着法摆放次序的优化
3.1 静态着法启示
静 态 着 法 启 发 是 指 不 依 赖 于 搜 索 结 果 的 着 法 排 序 方 式,即程序剖析了某个局势后,不通过查找,就大致应该知 道哪些着法应该首要测验。在4种着法启示中,吃子启示是 静态着法启示,由于吃子着法数量不多,并且往往许多状况 能马上得到实惠,所以需求首要考虑。而置换表启示、杀手 着法启示和前史表启示,都依赖于从前查找的成果,因而属 于动态着法启示的领域。
在文章中,吃子着法是有挑选的,即“表面上马上能

图1 着法生成次序
得到实惠”的 着 法 。 因而笔者用 了一个称为M V V (LVA ) 的战略,在 被 吃 子 有 保 护 的 情 况 下 , 考 虑 M V V ( 被 吃 子 价 值 ) – L V A ( 攻 击 子 价 值 ) 的 值,而在被 吃子没维护 的状况下, 只考虑MVV 的值,然后 对 这 种 策 略 产 生 的M V V (LVA ) 值作排序, 并 选 择M V V (LVA )大于零的着法首要查找。
3.2 置换表启示和低出(高出)鸿沟的批改在置换表中保存一个着法,一方面能够运用置换表来
取得首要变例,但最首要的作用是置换表启示。在勘探置换 表时,虽然局势射中但深度没到达要求时,至少能够得到一 个着法,这个着法应该首要查找,简直一切的象棋程序都是 这么做的。哪些着法应该被保存到置换表中呢?实践证明, PV结点中的最佳着法,以及Beta结点中发生切断的着法,都 应该被保存到置换表中,而Alpha结点虽然也要保存,但不 需保存着法(置换表着法是空的),由于Alpha结点的每个着 法都回来Alpha值,咱们不知道哪个着法是最好的。
明显, 当勘探置换表找到P V结点或Beta结点(但深度不行) 时, 就会有需求首要查找的置换表着法。 那么, 找到Alpha结点时,是否还会有置换表着法呢?我国象棋程序“纵马奔腾”采取了一个称为“低出(高出)鸿沟的批改”策
略,使得某些Alpha结点也存在置换表着法。
3.3 杀手着法启示
杀手着法启示(Killer Heuristic)根据这样一个思维,查找 某个结点时首要测验着法a1,由a1的后续着法b1发生切断, 回到本来的结点时再查找a1的兄弟结点a2时,假如b1仍旧是 a2的后续着法,那么b1很有或许也会发生切断。
采 用 杀 手 着 法 启 发 时 , 需 要 构 造 一 个 称 为 KillerMoves[MaxPly]的大局数组。查找到深度为Ply的结点 时,首要测验KillerMoves[Ply]的着法(条件是该着法在当时 局势下是合理的),查找完这个结点时,把发生切断的着法 (假如有的话)记录到KillerMoves[Ply]。由此发生的作用,就 是当亲兄弟结点没有杀手着法时,会找到堂兄弟结点的杀手 着法。
3.4 着法生成次序
运用本文3.1节所提出的静态点评启示,结合置换表启 发和杀手启示,本文提出了一个较好的着法生成次序,以取 代以往以棋子为主键的摆放次序。 如图1所示。
运用启示式办法对着法次序进行优化后,能大大削减 查找的节点数,试验成果如表1所示,其间优化前的着法顺 序指的是以棋子为主键的摆放次序。从表中能够看出。跟着 查找深度的添加,优化的着法次序所起的功效越来越大, 这 也验证了剪枝的功率与着法次序高度相关。
4 内部迭代加深和优化战略
4.1 迭代思维
开始有一个思维,便是一开端只查找一层,假如查找的时刻比分配的时刻少,那么查找两层,然后再查找三层, 等等,直到你用完时刻停止,这便是迭代的思维。内部迭代 加深优化着法次序,内部迭代加深是指当对一个节点进行 深度为d(d相对较大)的查找时,首要对其进行d-2的浅层搜 索,然后进行剪枝,找出一个最优的着法,然后持续进行搜 索,假如时刻没有用完相同查找到d-2层,否则在时刻用完 后间断查找。这会极大地进步查找深度和功率。
4.2 时刻战略
时刻战略在各个象棋程序中差异很大,有的程序底子 没有时刻战略,只能设定固定的查找深度,或许在固定的 时刻间断考虑,例如我国象棋协议现在就没有时刻战略。UCCI协议能够把时限规矩告知引擎,由引擎主动分配时刻,时限规矩能够是以下两种:
(1) 时段制,即在限制时刻内走完规则的步数。
(2) 加时制,即在限制时刻内走完好盘棋,但每步会加 上几秒。
不 管 处 理 哪 个 规 则 , 都 会 分 配 一 个 合 适 的 时 间
(ProperTime)用来走棋,这个时刻是这样核算的:
(1) 时段制:分配时刻 = 剩余时刻 / 要走的步数;
(2) 加时制:分配时刻 = 每步添加的时刻 + 剩余时刻 /
20 (即假定棋局会在20步内完毕);
4.3 杀棋战略
是否能找到杀棋和查找深度有关,某一深度下找不到 杀棋,但深一层查找就或许找到;但和一般局势不同的是, 假如必定深度能找到杀棋,那么更深的深度会得到相同的结 果。因而,假如找到杀棋,那么程序要运用不同的战略。对 于处理杀棋局势,往往用到以下几个战略:
(1) 置换表的存取战略,前面从前介绍过,假如置换表中存储的某个局势已被承认找到杀棋,那么勘探到这样的局
面时就不需求考虑深度条件。
(2) 根结点做迭代加深时,找到杀棋后查找就当即停 止。
(3) 给当时局势赋予一个分值区间(-WIN_VALUE, WIN_ VALUE),假如根结点的一切着法中,除了一个着法能够支 撑(即分值大于-WIN_VALUE)以外,其他着法都会输掉(即 分值都小于-WIN_VALUE),那么应该当即回来这个唯一着 法。别的假如某个根结点现已找到一个着法满足抢先对手巨 大优势(即分值大于WIN_VALUE),其他的着法就不用持续搜 索下去,能够直接回来这个着法。
5 定论
针对我国象棋中的着法摆放,本文将置换表着法、 静 态点评较优的着法和杀手着法排在前面,其他着法按前史得 分顺次降序排在后边,然后得到了一个较好的着法生成顺 序,使游戏电脑愈加智能,添加了游戏趣味性。