工程师在倒装芯片设计中常常运用从头布线层(RDL)将I/O焊盘从头分配到凸点焊盘,整个进程不会改动I/O焊盘布局。但是,传统布线才能或许不足以处理大规模的规划,因为在这些规划中从头布线层或许十分拥堵,特别是在运用不是最优化的I/O凸点分配办法情况下。这种情况下即便选用人工布线,在一个层内也不或许完结一切布线。
跟着对更多输入/输出(I/O)要求的进步,传统线绑定封装将不能有用支撑上千的I/O。倒装芯片安装技能被广泛用于代替线绑定技能,因为它不仅能减小芯片面积,而且支撑多得多的I/O。倒装芯片还能极大地减小电感,然后支撑高速信号,并具有更好的热传导功用。倒装芯片球栅阵列(FCBGA)也被越来越多地用于高I/O数量的芯片。
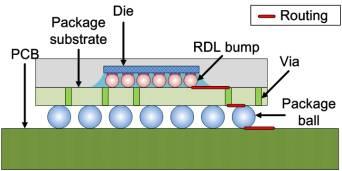
图1:倒装芯片横截面:信号线经过包括从头布线层在内的三个面。
从头布线层(RDL)是倒装芯片组件中芯片与封装之间的接口界面(图1)。从头布线层是一个额定的金属层,由中心金属顶部走线组成,用于将裸片的I/O焊盘向外绑定到比如凸点焊盘等其它方位。凸点一般以栅格图画安置,每个凸点都浇铸有两个焊盘(一个在顶部,一个在底部),它们别离衔接从头布线层和封装基板。因而从头布线层被用作衔接I/O焊盘和凸点焊盘的层。
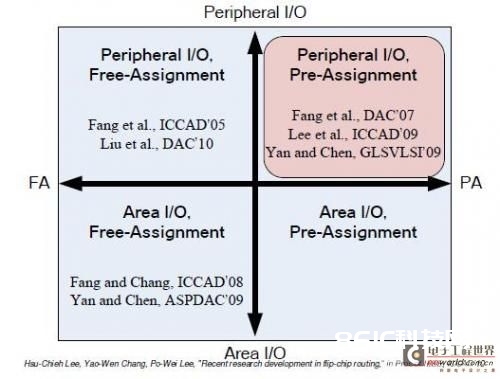
图2:自在分配(FA)和预分配(PA)是两种焊盘分配办法。外围I/O(PI/O)和区域I/O(AI/O)是两种倒装芯片结构。
倒装芯片结构与焊盘分配
以往研讨现已清晰了两种倒装芯片结构和两种焊盘分配办法,如图2所示。自在分配(FA)和预分配(PA)是两种焊盘分配办法,而外围I/O(PI/O)和区域I/O(AI/O)是两种倒装芯片结构。
两种焊盘分配办法的差异在于凸点焊盘和I/O焊盘之间的映射是否界说为输入。自在分配的问题是,每个I/O焊盘都能够自在分配到恣意凸点焊盘,因而分配与布线需求一同考虑。而对预分配来说,每个I/O焊盘有必要衔接指定的凸点焊盘,因而需求处理杂乱的穿插衔接问题。预分配问题的处理比主动分配要难,但对规划师来说则愈加便利。
两种倒装芯片结构别离代表不同的I/O布局图画。AI/O和PI/O的应战别离在于将I/O放在中心区域和将I/O放在裸片外围。现在PI/O愈加盛行,因为它简略,规划本钱低,尽管AI/O理论上能够供给更好的功用。
图3给出了一个PI/O比如。外围一圈绿色矩形代表I/O焊盘。赤色和黄色圆圈代表电源和地凸点,而蓝色圆圈代表信号凸点。坐落裸片中心的那些电源/地凸点被分类为网状类型,信号凸点被分类为栅格类型。

图3:从头布线层顶视图,图中显现了栅格图画的凸点焊盘和外围的I/O焊盘。
上述一切作业都会集在单层布线。它们将布线约束在一个金属层,每个网络都有必要在这个层完结布线。一般的方针是尽或许地削减走线长度。优化算法需求在布通率为100%的条件下完结。这种办法被证明能够很好地处理每种从头布线层的布线问题,条件是存在单层处理计划。
有用的从头布线层布线计划
从头布线层布线和凸点分配都是额定的完结使命,它们有助于规划从线绑定过渡到倒装芯片。凸点分配的意思是将每个凸点分配到指定的I/O焊盘。因为对大多数规划来说I/O焊盘坐落裸片外围,因而飞线和信号走线看起来像是从芯片中心到四周鸿沟的网状图画。
图3显现的是一个运用两层从头布线层的实在份额规划比如。金属层10(M10)和金属层9(M9)完结一切信号网络布线,并别离完结电源/地(PG)网格和电源布线。一般有数量很多的信号网络需求布线。凸点焊盘的占用面积比较大,在布线阶段常被认为是影响布线的妨碍。

图4:拥堵的从头布线层的布线处理计划。
图4(a)显现了一个拥堵的从头布线层比如,其间netA、netB……netF这6条网络显现为飞线。这种规划如此拥塞,以致于在单个层(如M10)上底子不或许到达100%的布通率。一种处理计划是添加从头布线层(如M10)的面积。这相当于添加裸片尺度,如图4(b)所示。别的一种处理计划是再添加一层从头布线层(如M11),如图4(c)所示。尽管从工程视点看具有实践可操作性,但从本钱视点看两种处理计划都是不行承受的。
代替性结构
一种更有用的选项是被称为伪单层布线的概念,它要占用已有金属层(如M9)上的一小块区域。假如所占用的区域用于非功用要害功用,这种办法就具有可操作性,而且极具本钱效益。
在图4(d)中,M9的一些区域(粉色区域)被用来完结布线。这儿咱们假定鸿沟线(打点的灰线)和裸片鸿沟之间的区域用于辅佐布线。伪单层布线办法规避了本钱问题,而且降低了拥堵布线的难度。尽管前述作业会集于单层布线,但伪单层布线在小块区域内运用了两层布线。
这种办法适用于从头布线层,因为M9一般用于衔接电源地和I/O焊盘,而且最重要的M9功用是将电源平均分配到内核中的每个逻辑门。成果M9外围区域的重要性就没有中心区域高,使得信号网络能够与电源地网络共享M9外围区域。
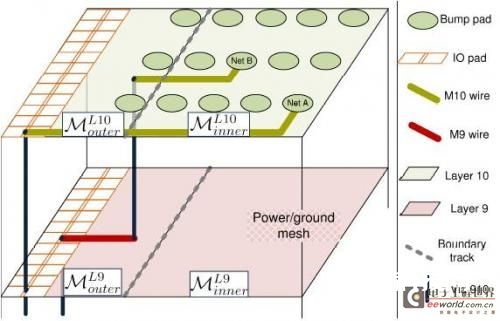
图5:别离坐落第9层和第10层的第一和第二个从头布线层。电源地网放置在M_inner^L9。可布线的区域是M_outer^L10 ∪ M_inner^L10 ∪ M_outer^L9。从头布线层布线的问题表现在衔接凸点焊盘Bi和输入/输出焊盘Oi之间的网络Ni。第一和第二个从头布线层别离是M9和M10,见图5。咱们依据鸿沟线将这个区域命名为内部/外部区域。整个从头布线层被划分为4个区:M_inner^L9、M_outer^L9、M_inner^L10和M_outer^L10。
术语界说
● 可布线区(伪单层):M_outer^L10 ∪ M_inner^L10 ∪ M_outer^L9
● 外部区:M_outer^L10 ∪ M_outer^L9
● 内部区:M_inner^L9 ∪ M_inner^L10
伪单层从头布线层的布线问题是在可布线区内完结网络Ni的Bi和Oi的实践连线,并最大极限地减小内部区的面积。这也意味着鸿沟线不是固定的。处理计划便是要确认鸿沟线的方位。
咱们的伪单层布线算法共有4步:第一步是区域性层分配、可移动的引脚分配和地图抽取。第二步是完结从一个凸点焊盘到一个引脚的网络布线。第三步是确认运用哪根线。第四步是完结从I/O焊盘到引脚的布线。图6显现了完结可移动引脚分配流程的简略比如。第一步最重要。好的可移动引脚分配能最大极限地削减从头布线层走线。
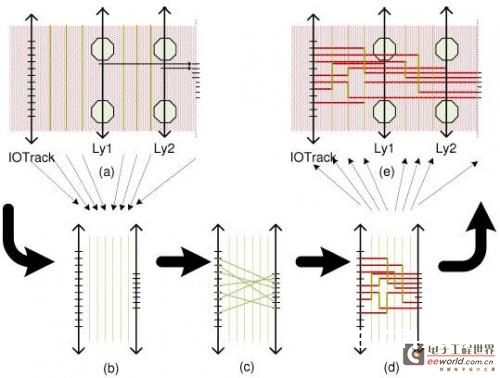
图6:这个简略比如解说了布线流程:(a)区域性层分配,可移动引脚的分配以及地图抽取。过程(b)和(d)描绘了运用哪根线以及运用通道布线完结从I/O焊盘到引脚的布线。(e)展现了从头映射进原始地图的布线成果。
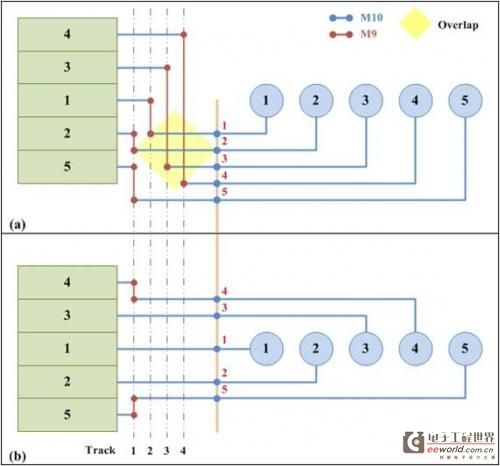
图7:可移动引脚分配的两个版别:(a)从单边排序的可移动引脚分配。(b)运用凸点引脚挑选算法的可移动引脚分配。凸点引脚挑选算法能够完结更少走线的布线成果。
图7显现了两种可移动引脚分配办法。第一个版别从同一边完结每排凸点的可移动引脚分配,因而引脚次序和凸点次序是相同的。这种办法能够快速完结可移动引脚分配,但缺陷是次序被凸点排固定了。假如凸点次序不抱负,就会发生很多的走线。
第二个也是引荐的办法是引脚挑选算法,如图8所示。第一步发生一切或许的可移动引脚次序,并在没有任何穿插网络的情况下完结从凸点到引脚的布线。第二步是依照最少穿插数量的原则从第一步挑选可移动引脚次序。凸点挑选算法保证凸点到引脚衔接没有任何穿插,引脚到焊盘的穿插数量最少。在运用凸点挑选算法后,再由通道布线算法完结从引脚到I/O焊盘的布线,并确认走线数量,分配走线资源。最终将布线成果从头映射到原始地图,完结伪单层的从头布线层布线。
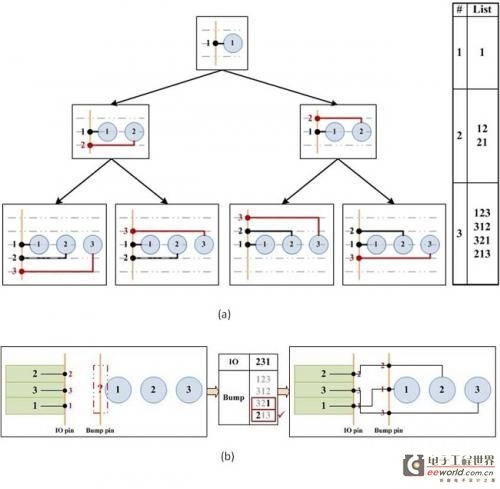
图8:凸点挑选算法。(a)发生可移动的引脚次序。(b)挑选可尽量削减可移动引脚和I/O焊盘间穿插衔接的引脚次序。
验证有用性
上述结构结构现已在一个大规模的商业项目中完结。首要,芯片被分为4个区:W、N、E和S。每个区包括100个以上的信号凸点。针对每个区,咱们的布线器能够在不到5秒的时间内发生成果并完结指令脚本的下载。经过在Encounter Digital Implementation (EDI)中提交这些脚本就完结了物理布线。这个成果也能够用任何引脚至引脚布线器完结,因为一切引脚方位都分配好了。规划规矩查看(DRC)判别一切成果都是好的。布线成果见图6和图7,一起总结在表I中,其间fcroute是在所界说的EDI中的倒装芯片布线器,p2proute是点到点布线器。因为没有签署发表协议,因而只显现了部分成果。

表I:布线成果小结。
本文小结
本文介绍了在伪单层上完结从头布线层布线的一种办法,这种办法能够用于过分拥塞以至于人工布线都无法完结单层处理计划的场合。伪单层布线办法供给了代替添加额定金属层或添加裸片尺度的可行办法。成功的要害是区域性层分配、可移动的引脚分配和地图抽取。这些技能将从头布线层的布线问题改变成为典型的通道布线问题。使用这种办法能够做到百分之百的布通率,而且最大极限地减小了两层布线的面积。