在AI浪潮推进下,许多别致的AI运用迅猛而生。但这些运用十分场景化,既需求老练的CPU和GPU,也需求全新的AI处理器。IPU(Intelligence Processing Unit)便是一种为AI核算而生的革命性架构,现在,IPU现已在金融、医疗、电信、机器人、云和互联网等范畴获得成效。
近来,英国草创公司Graphcore发布了第二代IPU以及用于大规划体系级产品IPU-Machine: M2000(IPU-M2000),新一代产品具有更强的处理才能、更多的内存和内置的可扩展性,可处理极端巨大的机器智能作业负载。据了解,IPU-M2000可构建成IPU-POD64这一Graphcore全新模块化机架规划处理计划,可用于极大型机器智能横向扩展,供给史无前例的AI核算或许性,以及彻底的灵活性和易于布置的特性。它可以从一个机架式本地体系扩展到高度互连的超高功用AI核算设备中的1000多个IPU-POD64体系。

这款即插即用的机器智能刀片式核算单元能有拔尖的功用,得益于Graphcore全新的7nm Colossus MK2(也叫IPU GC200),并由Poplar®软件栈供给全面支撑。
可不要小看那这块IPU,它是台积电7nm工艺的作用,晶体管数量高达594亿个,裸片面积到达823平方毫米。这比两个月前英伟达最新发布的安培架构GPU A100的540亿个晶体管添加了10%。

IPU是一种全新的大规划并行处理器,此前报导,他们现已推出了根据台积电16nm工艺集成236亿个晶体管的GC2 IPU,120瓦的功耗下有125TFlops的混合精度、300M的SRAM可以把完好的模型放在片内。
据介绍,Graphcore最新的MK2对三大技能——核算、数据、通讯进行了颠覆性打破:
1.核算
Mk2 GC200处理器是比较杂乱的单一处理器,根据台积电7nm技能,集成了将近600亿个晶体管,具有250TFlops AI-Float的算力和900MB的处理器内存储。处理器内核从上一代1217提高到了1472个独立处理器内核,然后到达有近9000个独自的并行线程。相关于第一代产品,其体系级的功用提高了8倍以上。
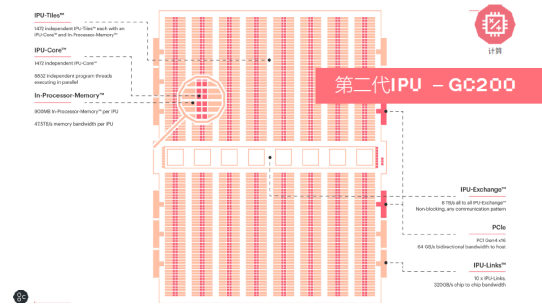
提到处理内存,可大致分为两部分:一部分是程序存储(Program Memory);另一部分是模型存储空间(Available Memory);其时的MK1具有300MB SRAM,算是单一芯片里边最大的存储容量,在相同程序存储空间下,MK2具有更大的Available Memory,相当于6倍以上的处理器内有用存储,大大提高了运算功率。这也使得每个IPU Memory的带宽是47.5TB/s。一同还包括IPU Exchange以及PCI Gen4跟主机交互接口;互联速度(IPU-links)也到达了320GB/s。

一个M2000的盒子里集成了4个GC200处理器,具有1PFlops16.16的算力,和近6000个处理器中心,以及超越35000个并行线程,In-Processor-Memory到达3.6GB。

2.数据
在处理数据方面,Graphcore提出了IPU Exchange Memory交换式存储的概念,较之英伟达HBM技能产品,Graphcore在M2000每个IPU-Machine里边经过IPU Exchange Memory,供给了将近超越100倍的带宽以及大约10倍的容量,这关于许多杂乱的AI模型算法大有裨益。
3.通讯
IPU-M2000具有内置的专用AI联网IPU-Fabric™。Graphcore创立了一个新的Graphcore GC4000 IPU-Gateway芯片,该芯片可供给令人难以置信的低时延和高带宽,每个IPU-M2000均可供给2.8Tbps。在从数十个IPU扩展到数以万计个IPU的过程中,IPU-Fabric技能使通讯时延简直坚持稳定。卢涛表明:“它可以从一个机架式本地体系扩展到高度互连的超高功用AI核算设备中的1000多个IPU-POD64体系。它还可以做到2.8Tbps超低延时,一同最多可以支撑64000个IPU之间横向扩展。经过直联或许是以太网交换机等技能做互联。此外,IPU-Fabric支撑AI运算里边的调集通讯或许全减缩(all-reduce)操作,这也是专门为AI运用从零开始规划的技能。”
IPU M2000的相关功用如下:
易于布置;
内含4个GC200 IPU,可到达1 PetaFlop 核算;
450GB Exchange Memory;
2.8Tbps IPU-Fabric,具有超低时延通讯;
可满意最严苛的机器智能负载;

罗旭介绍:“跟着IPU-M2000和IPU-POD64的推出,Graphcore进一步扩展了在机器智能范畴的产品竞赛优势。经过技能立异完结更强有力的产品线,这些立异可以供给客户所希望的职业抢先功用。关于寻求将机器智能核算添加到数据中心的客户而言,Graphcore最新推出的IPU-M2000凭仗其强壮的算力、易于扩展的灵活性和杰出的易用性,将具有极强的可行性和价值提高潜力。”
IPU MK2 VS IPU MK1,功用猛蹿
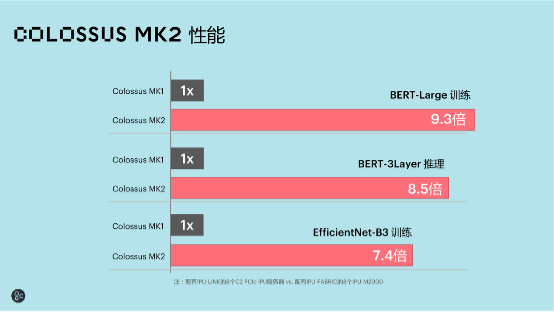
具有如此先进架构的IPU Mk2功用怎么?据介绍,第二代IPU GC2000(MK2)与第一代IPU(MK1)比较,实践功用提高了8倍。
在核算、数据和通讯这三块别离做了十分大的改善,总结下来有三大差异:
1.核算方面,它到达了两倍以上的peak才能,也便是Mk2峰值算力比Mk1的峰值算力高两倍,尤其是数据这块不同会很大;
2.根据六倍以上的处理器内有用存储,加上超越446GB的 IPU-Machine的流存储,其内存上的提高远非纸面上多出的600MB的优势;
3.根据大规划横向扩展IPU-Fabric技能,互联功用更强;
Mk2跟Mk1在体系级的比照,经过三个场景的比较,MK2都处于均匀8倍的功用提高。
Graphcore联合创始人兼CEO Nigel Toon表明,GC200是现在世界上最杂乱的处理器,可使立异者完结AI的革命性打破。
在IPU面前,GPU显得无能为力?
IPU的规划根底是Graphcore关于机器智能的Workload的了解。在所有方式的机器智能核算中,Graphcore企图从数据中揣度常识模型,然后运用这些学习的模型从其他数据揣度出新的成果。所以在很大程度上,作业量是由常识模型的性质来界说的。常识模型和对它们履行推理所需的算法最自然地表明为核算图。因而,他们用核算图来作为机器智能的根底表明办法。

其间核算图有以下特征:
1. 规划大,包括数千到数百万个极点,意味着巨大的并行性;
2. 稀少,必须在架构上习惯这种稀少性,由于它对处理器之间的存储器拜访形式和通讯形式有严重影响;
3. 数据的核算近似值;
4.模型参数的重用性,简略来说,卷积是空间重用,而回归是时刻重用。这种重用可以获取数据中的空间或时刻不变性。一同,假如重用参数,则会将其作用于给更多的数据,然后更快地学习;
5. 图形结构可以被视为静态,这关于构建高效的并行核算至关重要;
关于稀少性,还可以更进一步阐明。当咱们把图模型存储到物理可完结的存储器中的时分,存储器拜访的有用稀少度进一步添加。例如,一个图中的极点或许连接到相同挨近的100个相邻极点。可是,假如我将该极点的状况存储在具有线性地址的存储器中,则它只能有两个直接街坊。在低维存储器中存储高维核算图的作用是使邻域涣散在存储器中。这关于十分宽的向量机(如GPU)来说是一个潜在的问题。图处理有利于更细粒度的机器,然后有用地涣散和搜集(scatter and gather)数据。
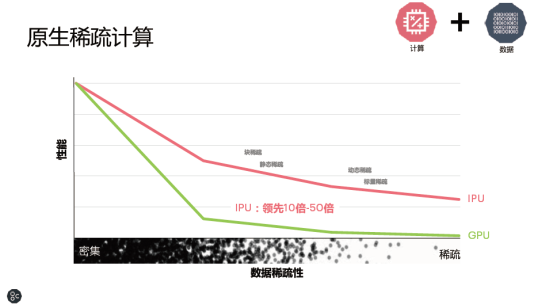
在原生稀少核算方面,把核算和数据结合起来看,就会看到IPU跟GPU天壤之其他体现。无论是数据仍是核算十分密布的情况下,从块稀少(block sparse)到动态稀少(dynamic sparse),GPU的体现实践上都很超卓,但跟着数据稀少性越来越高,IPU的优势会越来越显着,比GPU抢先10到50倍的功用。
这便是为什么IPU具有比GPU更多的处理器,每个处理器都规划用于处理较窄的向量。根据上述对机器智能的Workload的了解,Graphcore提出了IPU的规划。和CPU (scalar workload),GPU (low-dimensional workload)比较,IPU是为了high-dimensional graph workload而规划的。
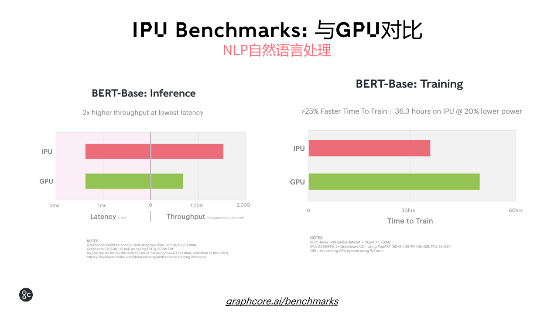
NLP方面,一机八卡的装备,IPU可以到达36.3小时的练习时刻,提高了25%。
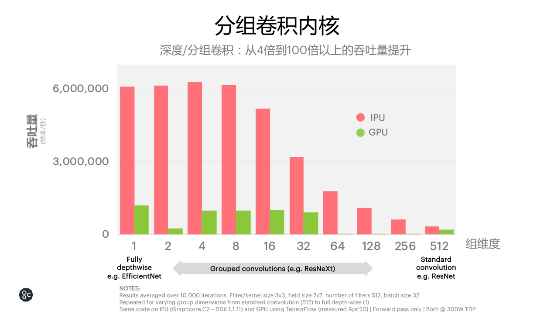
在分组卷积内核中,ResNeXt类型的模型下,Benchmark相对竞品有一个4倍到100倍的功用提高。
Graphcore IPU,大幅加快文本转语音模型
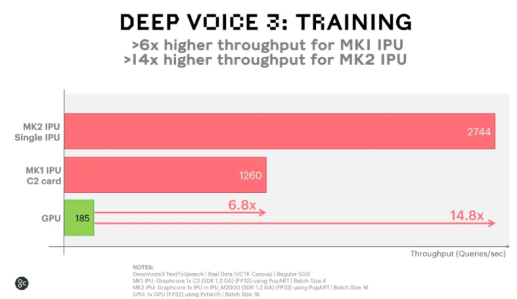
在Graphcore智能处理器(IPU)上,百度的Deep Voice 3完结了无与伦比的文本到语音的练习功用体现。IPU的一同架构特色以及与处理器一同规划的Poplar软件栈的优化一同促成了速度大幅提高。
与GPU PK一下,它的变现显得更拔尖。下图比较了IPU和GPU备选计划在练习期间的吞吐量数字。经过在具有2个Mk1 IPU(批处理巨细为4)的C2卡进步行数据并行练习,可以完结每秒1260个查询(QPS)的吞吐量,比较GPU完结了6.8倍加快(运用与C2卡相同的功率)。换言之,要在VCTK语料库上完结一个练习阶段,运用Mk1 C2卡大约需求35秒,而运用GPU大约需求4分钟。
经过IPU-M2000中的单个Mk2 IPU和16的批处理巨细,咱们获得了每秒2744个查询的吞吐量,比GPU快14.8倍。即便发布了最新的GPU,根据已发布的GPU比照成果,咱们预估第二代IPU依然有大约10倍的优势。
软件Poplar SDK——助力创立下一代机器智能
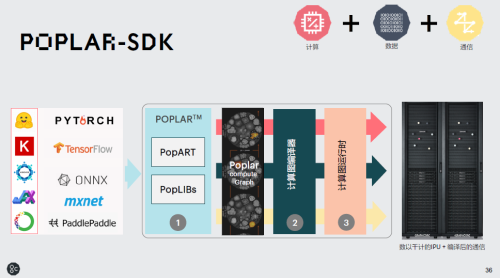
IPU规划意图很清晰,专为机器智能或AI运用场景而打造的,可一同做练习和推理。” Graphcore高档副总裁、我国区总经理卢涛表明,“IPU是一个处理器,针对IPU咱们开发的 Poplar®软件,对程序员来说,在 IPU 进步行开发便是写一个TensorFlow或许Pytorch 的程序,易用性十分好。”
据悉,Poplar®现在现已供给750个高功用核算元素的 50 多种优化功用,支撑规范机器学习结构,如TensorFlow1、2,ONNX和PyTorch,很快也会支撑 PaddlePaddle。
Graphcore此次最新发布的SDK 1.2首要特性包括:
1.集成了先进的机器学习结构。
2.进一步敞开初级其他API,首要是为上层的算法供给一个低层次API接口。
3.添加结构支撑,包括对PyTorch和Keras的支撑。
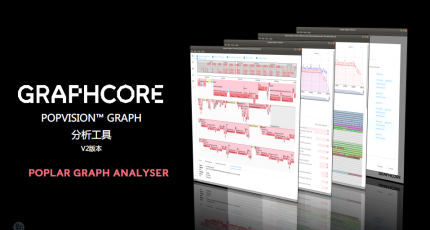
要开发一个好模型,除了SDK以及杰出的驱动和上层结构支撑以外,东西也十分重要。为此Graphcore发布了一款根据一个图形的剖析东西——PopVision 核算图,它可以做到根据算子层面,检测整个体系,将算力,内存的运用情况用图形界面直观的出现出来。
除此之外,Graphcore还正式发布根据IPU的开发者云,面向我国的客户、大学、研究机构和个人研究者免费运用,使得前沿的机器智能立异者可以轻松获取IPU进行前沿AI模型的云端练习与推理,然后在新的一波机器智能浪潮中获得要害打破。该开发者云是我国首款IPU开发者云,布置在金山云上,运用了IPU PCIe卡适配完结的浪潮NF5568M5服务器和戴尔DSS8440服务器。

为了更好地赋能我国AI立异者,合作开发者云,Graphcore的立异社区现已全面正式上线,社区渠道包括微信、知乎、微博以及Graphcore行将上线的中文立异社区网站。立异者们可以在自己常用的交际渠道上轻松向Graphcore全球的科学家发问,获取IPU硬件产品与软件更新的最新资讯、阅览深度技能文章、并与其他立异者们一同沟通生长。
究竟什么是推理和练习?
AI智能处理单元最首要的作业便是练习和推理,那么二者有何差异?在Q&A环节中罗旭给出了答案:“推理比练习要简略许多,除前向核算外,练习首要还会涉及到反向核算。关于底层需求支撑的算子。练习也会比推理多几倍;相同从底层的硬件视点来讲,练习关于处理器的通用性要求会更高。”
现在机器智能开展的方向之一便是Continuous Learning。假如在一个架构上可以一同很好的支撑Training和Inference当然十分抱负。不过从现在来看,Deep Learning中的Training和Inference仍是有较大差异,运算量的巨大不同,精度要求不同,算法的不同,布置的Constraints等等都会收到约束。
现在,第三类AI处理器遭到的重视度越来越高,IPU能否更好完结CPU和GPU不拿手的AI使命成为名副其实的革命性架构?Graphcore的IPU能否很好的处理这些问题?定论还需时刻来考量。