生成对立网络(GAN)是当今最盛行的图画生成办法之一,但点评和比较 GAN 发生的图画却极具挑战性。之前许多针对 GAN 组成图画的研讨都只用了片面视觉点评,一些定量规范直到最近才开端呈现。本文以为现有方针不足以点评 GAN 模型,因而引入了两个依据图画分类的方针——GAN-train 和 GAN-test,别离对应 GAN 的召回率(多样性)和准确率(图画质量)。研讨者还依据这两个方针点评了最近的 GAN 办法并证明晰这些办法功能的显着差异。上述点评方针标明,数据集杂乱程度(从 CIFAR10 到 CIFAR100 再到 ImageNet)与 GAN 质量呈负相关联系。
生成对立网络(GAN)[19] 是由一对存在竞赛联系的神经网络——生成器和判别器——组成的深度神经网络架构。通过替换优化两个方针函数练习该模型,这样能够让生成器 G 学会发生与实在图画类似的样本,还能让判别器 D 学会更好地鉴别真假数据。这种范式潜力巨大,由于它能够学会生成任何数据散布。这种模型现已在一些核算机视觉问题上取得了必定作用,例如文本到图画的转化 [56] 和图画到图画的转化 [24,59]、超分辨率 [31] 以及传神的天然图画生成 [25]。
自从提出了 GAN 模型后,近几年间呈现了许多变体,如以进步生成图画质量为意图的 GAN 模型 [12,15,25,36] 和以安稳练习进程为意图的 GAN 模型 [7,9,20,34,36,40,57]。通过调整附加信息(如类别标签),GAN 还能够被修正为生成给定类别图画的网络 [16,35,37,41]。完成这一主意有许多办法:连接标签 y 和生成器的输入 z 或中心特征映射 [16,35],运用条件批归一化 [37] 以及用辅佐分类器增强鉴别器 [41]。跟着这些办法的提出,有一个问题就变得重要了起来:该怎么点评和比较这些模型呢?
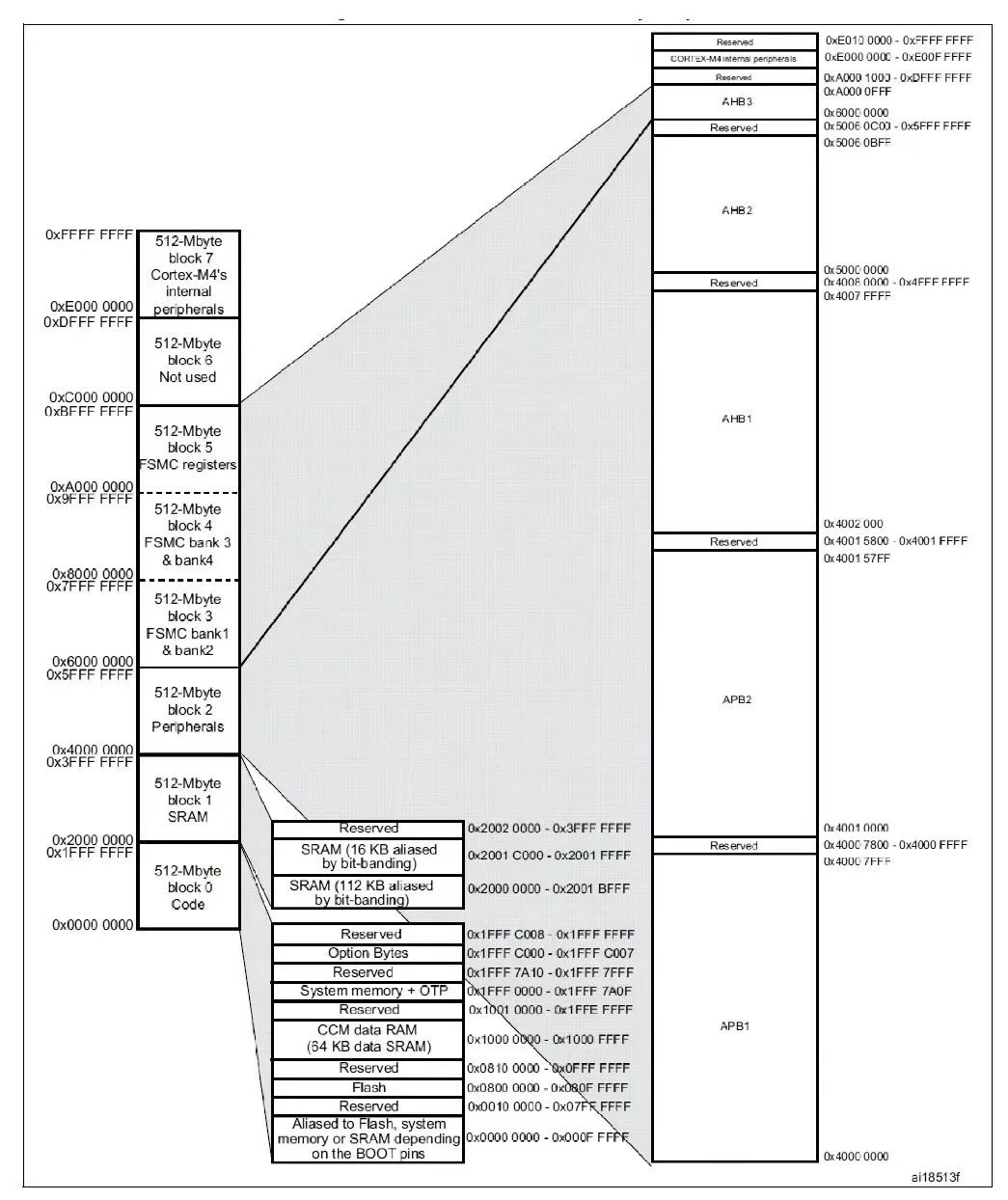
点评和比较 GAN,或者说点评和比较 GAN 发生的图画,是一件极具挑战性的事,部分原因是缺少清晰的、在可比较概率模型中常用的似然办法 [51]。因而,之前许多针对 GAN 组成的图画的作业都只用了片面视觉点评。如图 1 所示,当时最佳 GAN 生成图画的样本 [36],用片面点评办法无法准确点评图画质量。近两年的研讨现已开端测验通过定量办法点评 GAN[22,25,32,46]。
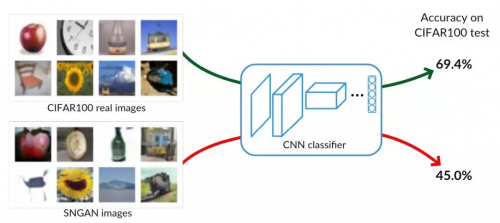
图 1:当时最佳 GAN 模型(如 SNGAN)[36] 生成传神图画,这些图画难以用片面点评法与实在图画进行比较。咱们的依据准确率的图画分类新办法处理了这个问题,并展现了实在图画和生成图画间的显着差异。
将 Inception 分数(IS)[46] 和 Fr´echet Inception 间隔(FID)[22] 作为与生成图画视觉质量相关的暂时方针。IS 通过核算图画发生的 (logit) 呼应和边沿散布(即在 ImageNet 上练习出来的 Inception 网络生成的悉数图画的均匀呼应)之间的 KL 散度衡量生成图画的质量。换句话说,IS 无法与方针散布的样本进行比较,仅可用于量化生成样本的多样性。FID 比较的是实在图画和生成图画间的 Inception 激活值(Inception 网络中倒数第二层的呼应)。但这样的比较将实在图画和生成图画的激活值近似为高斯散布(拜见等式(2)),核算其均匀值和方差,但由于过分粗糙而无法捕捉其细节。这些点评办法都依靠于通过 ImageNet 预练习的 Inception 网络,这对其他数据集(如面部数据集和生物医学成像数据集)来说远不行抱负。总而言之,IS 和 FID 是点评练习发展的有用方针,但它们无法点评实在国际中的使命。正如咱们在第 5 节中评论的那样,与咱们的方针(以表 2 中的 SNGAN 和 WPGAN-GP(10M)为例)不同,这些方针不足以准确区域别出当时最佳的 GAN 模型。
还有一种点评办法是依据准确率和召回率核算生成样本到实在数据流形间的间隔 [32]。高准确率意味着生成样本与数据流形很挨近,而高召回率意味着生成器的输出样本很好地掩盖了流形。这些方针仍是很抱负主义的,由于无法在流形不知道的天然图画数据上进行核算。实际上,[32] 中的点评办法也只能用在由灰度三角形组成的组成数据中。另一种用于比较 GAN 模型间隔的是 SWD[25]。SWD 是实在图画和生成图画间的 Wasserstein-1 间隔的估量值,它核算的是从图画的 Laplacian 金字塔表征中提取的部分图画之间的数据类似性。正如第 5 节所说,SWD 的信息量低于咱们的点评方针。
咱们在本文中提出了新的点评方针,是用 GAN-train 分数和 GAN-test 分数比较类条件的 GAN 架构。关于这两种方针,咱们都依靠神经网络架构来进行图画分类。为了核算 GAN-train,咱们用 GAN 生成的图画练习了分类网络,然后在由实在图画组成的测验集上点评了其体现。直接地说,这衡量了学习到的(生成图画)散布和方针(实在图画)散布间的差异。能够得出结论:假如学习用于差异针对不同类别的生成图画特征的分类网络能够对实在图画进行正确分类,那么生成图画与实在图画类似。换句话说,GAN-train 类似于召回率衡量,由于 GAN-train 体现好意味着生成的样本满足多样化。可是,GAN-train 也需求满足的准确率,不然分类器会遭到样本质量的影响。
咱们的第二个方针,GAN-test,是在实在图画上练习并在生成图画上点评得到的网络的准确率。该方针与准确率类似,值比较高意味着生成的样本与(不知道)天然图画散布近似。除了这两个方针外,咱们还研讨了 GAN 生成图画在强化练习数据方面的作用。能够将其视为衡量生成图画多样性的方针。咱们在图 1 顶用 GAN-train 方针阐明晰咱们的点评办法的作用,尤其是在片面点评不充分的状况下。咱们将在第 3 节评论这些点评方针的细节。
正如第 5 节中广泛的试验效果以及弥补资料和技能陈述中的附录 [5] 所示,与之前评论的一切点评方针比较(包含没有得出结论的人类研讨),这些方针在点评 GAN 方面的信息要丰厚得多。尤其是咱们还对当时最佳的两个 GAN 模型(WGAN-GP[20] 和 SNGAN[36])以及其他一些生成模型 [45,47] 进行了点评,以供给基线比较。用 MNIST[30]、CIFAR10、CIFAR100[28] 和 ImageNet[14] 数据集点评了图画分类体现。试验效果标明,跟着数据集杂乱度的添加,GAN 图画的质量显着下降。
论文:How good is my GAN?

论文链接:https://arxiv.org/pdf/1807.09499.pdf
摘要:生成对立网络(GAN)是当今最盛行的图画生成办法之一。虽然现已有了不少能够直观感遭到的令人形象深化的作用,但一些定量规范直到最近才呈现。咱们以为现有方针不足以点评模型,因而在本文中引入了两个依据图画分类的方针——GAN-train 和 GAN-test,这两个方针别离对应的是 GAN 的召回率(多样性)和准确率(图画质量)。咱们依据这两个方针点评了最近的 GAN 办法并证明晰这些办法功能的显着差异。此外,咱们的点评方针清楚地标明,数据集杂乱程度(从 CIFAR10 到 CIFAR100 再到 ImageNet),与 GAN 质量呈负相关联系。
3. GAN-train 和 GAN-test
条件 GAN 模型的一个重要特征是生成的图画不只要传神,还要能辨识出归于一个给定的类别。一个能够完美捕获方针散布的抱负 GAN 能够生成一个新的图画数据集 S_g,这个数据集与原始的练习集 S_t 没什么差异。假定这些数据集巨细相同,依据这两个数据会集的恣意一个练习出来的分类器应该有相同的验证准确率。当数据集满足简略(例如 MNIST[48])时确实是这样(见 5.2 节)。在这种最佳 GAN 特性的推进下,咱们规划了两个分数来点评 GAN,如图 2 所示。
图 2:GAN-train 和 GAN-test 图示。GAN-train 依据 GAN 生成图画练习了一个分类器,并在实在图画上进行测验。该方针点评了 GAN 生成图画的多样性和实在性。GAN-test 依据实在图画练习了分类器,并在 GAN 生成图画上进行点评。该方针点评了 GAN 生成图画的实在性。
GAN-train 是在 S_g 上练习,在由实在图画组成的验证集 S_v 上测验的分类器的准确率。当 GAN 不行好的时分,GAN-train 会比在 S_t 上练习出来的分类器的验证准确率低。形成这种状况的原因有许多,例如,(i)与 S_t 比较,方式下降导致 S_g 的多样性下降;(ii)生成样本不行传神,以至于分类器无法学到相关特征;(iii)GAN 能够将类别混在一同并混杂分类器。不幸的是,咱们无法确认 GAN 的问题在哪。当 GAN-train 的准确率与验证集的准确率附近时,意味着 GAN 发生的图画质量很高且和练习集相同多样化。正如咱们在 5.3 节中所说的那样,多样性会跟着生成图画数量的改动而改动。咱们将在本节结尾的点评评论中对其进行剖析。
GAN-test 是在原始练习集 S_t 上练习,但在 S_g 上测验得到的分类器的准确率。假如 GAN 能很好地进行学习,这就会是一项简略的使命,由于这两个数据集的散布是相同的。抱负状况下,GAN-test 应该和验证准确率附近。假如 GAN-test 显着高了,那就意味着 GAN 过拟了,即它仅仅简略地记住了练习集。相反,假如 GAN-test 显着低了,则阐明 GAN 无法很好地捕获方针散布且 GAN 生成的图画质量堪忧。留意,该方针无法阐明样本的多样性,由于能够完美回忆每一个练习图画的模型能够得到很高的分数。GAN-test 与 [32] 中的准确度相关,它量化了生成图画与数据流形之间的挨近程度。
为了深化了解 GAN 生成图画的多样性,咱们通过巨细不同的生成图画数据集得到了 GAN-train 准确率,将其与依据相应巨细的实在数据练习得到的分类器的验证准确率比较较。假如一切的生成图画都是完美的,GAN-train 的 S_g(其间 GAN-train 等于小尺度练习集的验证精度)的巨细将会是 S_g 中不同图画数量的杰出估量。咱们在实践中观察到,在 GAN 生成样本数量确认的状况下,GAN-train 准确率是饱满的(见第 5.3 节中的图 4(a)和 4(b))。这是一种衡量 GAN 多样性的办法,与 [32] 中的召回率类似,都是衡量 GAN 掩盖的数据流形的分数的办法。
5. 试验
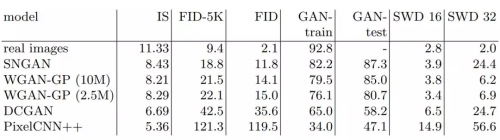
表 1:CIFAR10 试验。IS:越高越好。FID 和 SWD:越低越好。为了进步可读性,此处的 SWD 值扩展了 1000 倍。GAN-train 和 GAN-test 是以百分比方式给出的准确率(越高越好)。

图 3:榜首列:SNGAN 生成的图画。其他列:来自 CIFAR10「train」的 5 幅图画,最挨近基线 CIFAR10 分类器特征空间中榜首列的 GAN 图画。

表 2:CIFAR100 试验。细节参阅表 1 标题。
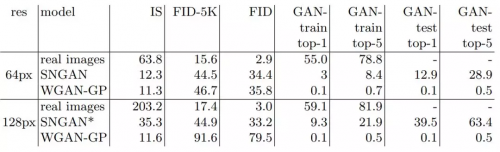
表 3:ImageNet 试验。SNGAN* 指通过 850k 次迭代练习得到的模型。细节参阅表 1 标题。
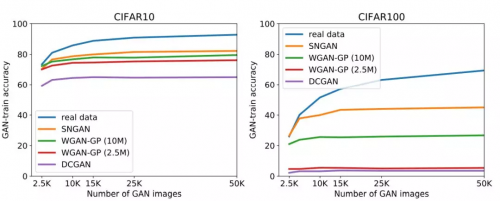
图 4:改动生成图画数据集巨细对 GAN-train 准确率发生的影响。为了便于比较,咱们还展现改动实在图画练习数据集巨细对效果(蓝色曲线)发生的影响(最好以 pdf 格局检查)。
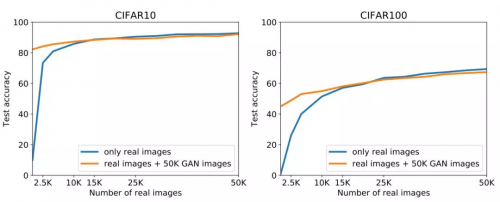
图 5:用实在图画和 SNGAN 生成的图画结合的数据集练习分类器的效果。

表 4:用减缩的实在图画数据集练习的 SNGAN 的数据强化。在实在图画数据集或实在图画和 SNGAN 生成的图画相结合的数据集(real+GAN)上练习得到的分类器。分类器准确率以百分数方式表明。