R是进行运算、清洗、汇总及生成概率核算等数据处理的一个绝佳挑选。此外,由于它独立于途径、短期内不会消失,所以生成的程序能够在任何当地运转。而且,它具有非常棒的辅佐资源。
本文摘录自James D.Miller编撰的《数据科学核算学》(StaTIsTIcs for Data Science)一书,该书由Packt Publishing出书。
R是一种易上手的语言和环境,它自身很灵敏且专心于核算核算,因而成为运算、清洗、汇总及生成概率核算等数据处理的一个绝佳挑选。
此外,以下是用R进行数据清洗的其他原因:
由于许多数据科学家都在运用R,所以它短时刻内不会消失。
R独立于途径,因而能够在恣意当地运转程序。
R有绝佳的辅佐资源—Google一下,你就能够看到。
注:虽然作者将示例数据命名为“赌博数据”(Gamming Data),它仅仅用来演示代码的赌博数据。
离群点
对离群点最简略的解说是:离群点是和其他数据不匹配的数据点。依照常规,任何过高、过低或许反常(依据项目布景)的数据都是离群点。作为数据清洗的一部分,数据科学家一般要辨认出离群点并用通用的办法处理它:
删去离群点的值,乃至是离群点对应的实践变量。
转化变量值或变量自身。
让咱们来看一下实践事例中怎么用R辨认并处理数据离群点。
老虎机在赌博界非常盛行(老虎机的操作办法是把硬币投入到机器中,并拉动把手来决议报答)。现在大部分老虎机都电子化了,编程使它们的一切活动都能被继续追寻。在本文的事例中,赌场的投资者期望运用这些数据(以及各种弥补数据)来调整盈余战略。换句话说,什么能让老虎机赚更多钱?是机器的主题仍是类型?新机器比旧机器或旧式机器更有利可图吗?机器的方位会发生怎样的影响?低面额的机器会赚更多钱吗?咱们测验用离群点来找到答案。
给定一个调集或赌博数据库(格局为逗号分隔或CSV文本文件),其间包含的数据如老虎机的方位、钱的面额、月份、日、年、机器类型、机器的年纪、促销、优惠券、气候和投币量(投币量是放入机器的钱币总额减去付出的数额)。
作为一个数据科学家,第一步要对数据进行综评(有时称为概述),此刻咱们要确认是否存在反常值,第二步是处理这些离群点。
进程一 数据概述
R使这一进程变得非常简略。虽然能够经过许多办法编程求解,但咱们要测验用最少的程序代码或脚原本处理问题。将CSV文件界说为R的变量(命名为MyFile)并将文件读入为数据框(命名为Mydata):
MyFile《-“C:/GammingData/SlotsResults.csv” MyData《- read.csv(file=MyFile, header=TRUE, sep=“,”)
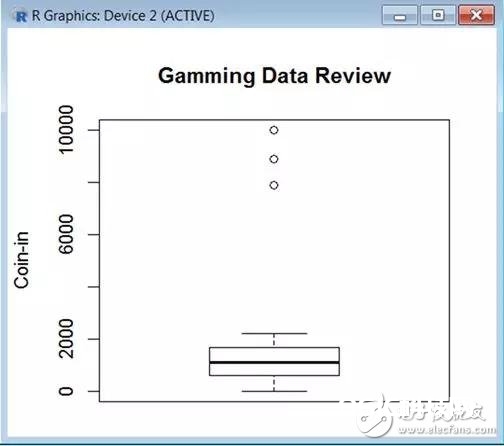
在核算学上,箱型图是一种简略的办法以得到核算数据集的散布、变异性和中心(或中位数)相关信息,所以咱们将用箱型图来研讨咱们能否辨认出中位数Coin-in以及能否找到离群点。为了达到这些,咱们能够让R画出文件中每个老虎机的Coin-in值,制作箱型图的函数如下:
boxplot(MyData[11],main=‘GammingData Review’, ylab = “Coin-in”)
注:Coin-in是文件中的第11列,所以直接将它作为boxplot函数的参数。此外还增加了一个可挑选的参数(再次着重,本文已尽量坚持代码的简练度),以便在可视化图中增加标题。
履行前文的代码能够得到下图作用,包含中位数(中位数在箱型图中是中心横穿的线)以及四个离群点:

进程2-处理离群点
现在咱们发现数据中的确存在离群点,咱们要处理这些点以确保它们不会对本研讨发生负面影响。首要,咱们知道Coin-in有负值是不合理的,由于机器输出的钱币必定不会比投入到机器中的硬币多。依据这个准则,咱们能够从文件中删去Coin-in为负值的记载。此外,R能够协助咱们用subset生成一个新的数据框,新数据会集只要Coin-in中的非负值。
咱们要将subset数据框命名为noNegs:
noNegs《- subset(MyData, MyData[11]》0)
接下来,咱们要再一次画图以确认现已删去负值离群点:
boxplot(noNegs[11],main=‘GammingData Review’, ylab = “Coin-in”)
这就发生了新的箱型图,如下图中所示:
咱们能够用相同的办法去除Coin-in中极点的正值(大于1500美元)得到另一个数据子集并再次画图:
noOutliers《-subset(noNegs, noNegs[11]《1500) boxplot(noOutliers[11],main=‘GammingData Review’, ylab = “Coin-in”)
当你对数据进行不同的迭代后,主张你保存大部分版别的数据(假如不是最重要的)。你能够用write.csv这个R函数:
write.csv(noOutliers,file=“C:/GammingData/MyData_lessOutliers.csv”)
注:大部分数据科学家在整个项目中采纳通用的命名规矩。文件的姓名应该尽或许明晰以便往后协助你节省时刻。此外,特别是在处理许多数据时,你需求留意内存空间的问题。
以上代码的输出成果如下:
范畴常识
接下来,另一个数据清洗的技能是依据范畴常识整理数据。这并不杂乱,这种技能的关键是运用数据中无法发觉的信息。例如,当咱们知道Coin-in不行能有负值时,咱们排除了Coin-in负值的状况。另一个事例是飓风Sandy突击美国东北部的时刻。在这段时刻内,机器的Coin-in值都很低(非零)。数据科学家应该依据信息判别是否要移除某段特定时期内的数据。
有效性查看
穿插验证是一种协助数据科学家在数据库中运用规矩的技能。
注:有效性查看是核算数据清洗中最遍及的方式,而且是数据开发者和数据科学家都非常了解的流程。
数据清洗时能够设定恣意数量的有效性准则,这些准则要遵从数据科学家的意图或方针。例如有如下准则:数据类型(例如,某个字段必定要是数值型),规模约束(数据或日期要在一个特定规模内),要求(某个字段不能为空或没有值),仅有性(一个字段,或字段的结合,必定是数据库中仅有的),组成员(这个值必定是列表中的值),外键(事例中必定要被界说的清晰的值或满意特别规矩),正则表达式方式(简略地说便是这个值的格局满意预设的格局),穿插字段验证(事例中的字段组合要满意特定规范)。
依照前文说到的内容,咱们来看一些事例,从数据类型开端(也称为强制准则)。R供给的六个强制函数如下:
as.numeric
as.integer
as.character
as.logical
as.factor
as.ordered
as.Date
这些函数,结合一些R的常识,使得在数据库中转化数据变得简略。例如,以前文的赌博数据为例,咱们能够生成新的赌博成果文件,其间年纪值被存为字符型(或文本值)。为整理它,咱们需求将其转化为数据型。咱们能够运用以下R代码完结快速转化:
noOutliers[“Age”]《-as.numeric(noOutliers[“Age”])
一个需求留意的当地:用这种简略办法时,假如有数据不能转化,需求将其设定为NA值。在类型转化中,最大的作业是了解需求输入什么数据以及哪些数据类型是合法的;R有很广泛的数据类型,包含标量、向量(数值型,字符型,逻辑型),矩阵,数据框及列表。
数据清洗中咱们要重视的另一个范畴是正则表达式。在实践中,特别是当处理的数据来历于许多途径时,数据科学家的确面临如下问题:字段不是抱负的格局(关于当下方针而言)或许字段值的格局不共同(或许会引发过错的成果)。例如日期、社会安全号码(SSN)以及手机号码。依据数据的来历,你不得不从头输入(如前文描绘),可是一般状况下,你需求依据方针将数据从头界说为能够运用的方式。
注:从头输入数据是很重要的,这样R就知道将值作为现在的数据而且你能够正确运用各种R数据函数。
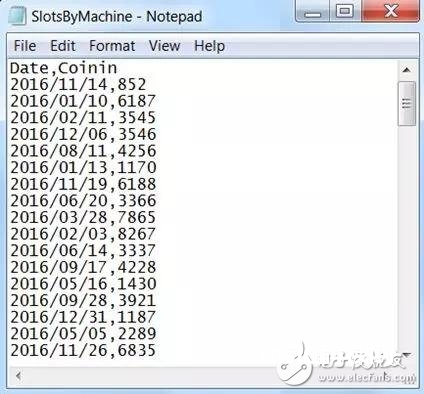
一个常见的事例是当数据包含方式为YYYY/MM/DD的日期数据时,你想按每周汇总的方式呈现出时刻序列剖析,或许其他需求日期值的操作可是或许需求从头界说日期格局,或许你需求将其变为R日期类型。所以,假定一个新的赌博文件——只要两列数据:日期和投币量,这个文件是一个老虎机每天的投币量。
新的文件记载如下截图所示:
数据科学家能够用各种数据清洗的事例。从验证每个数据点的数据类型下手,咱们能够用R函数class来验证文档的数据类型。首要(如咱们在前文事例中所作),读入CSV文件存为数据框:
MyFile《-“C:/GammingData/SlotsByMachine.csv” MyData《- read.csv(file=MyFile, header=TRUE, sep=“,”)
随后,咱们能够运用class函数,如下图截图所示:
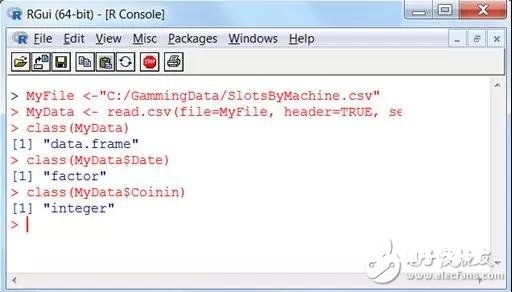
从上图中能够看到用class来显现数据类型。
MyData是用来保存赌博数据的数据框,日期Date是向量类型,投币量Coinin是一个整数。所以,数据框和整数是有意义的,可是要留意R将日期设置为向量(factor)类型。向量是分类变量,在汇总核算、绘图和回归中非常有用,但它不是非常适用日期型。为了处理这个问题,咱们能够运用R函数substr和paste,如下所示:
MyData$Date《-paste(substr(MyData$Date,6,7),substr(MyData$Date,9,10), substr(MyData$Date,1,4),sep=“/”)
以上代码从头界说了日期字段的格局。它将数据字段值分红三部分(月、日和年)然后依照抱负的次序(/分隔符(sep))张贴在一起,如下截图所示:
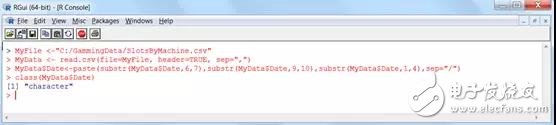
咱们发现这一行脚本将日期字段转化为字符类型,终究咱们能够用as.Date函数将值重设为日期(Date)类型:
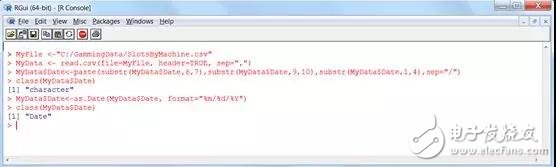
略微测验一下,就能够从头格局化来得到抱负的字符串或字符数据点。
改善数据
经过改善进行数据整理是另一种常见的技能,增加相关信息、现实或数据使得数据变得完好(或许更有价值)。这些附加数据的来历能够是用数据中现有信息或从其他来历增加信息进行核算。数据科学家花费时刻完善数据的原因有许多。
依据当时的意图或方针,数据科学家弥补的信息或许用于参阅、比较、比照或发现趋势。
典型的用例包含:
衍生现实核算
比照日历与财政年度的运用
转化时区
钱银转化
增加当时和前期方针
核算价值,如每天总出货量
坚持缓慢改动的维度
注:作为数据科学家,你要经常用脚原本改善数据,这个办法要比直接修改数据文档好得多,由于这样犯错的或许性更低而且能够保持原始文件的完好性。此外,树立脚本可让你将改善的进程重复运用于多个文件或收到的新版文件中,不需求重做相同的作业。
回到咱们的赌博数据中,假定咱们在接纳老虎机的投币量文档,一起公司在美国大陆外的当地建立赌场。这些新地址正在向咱们发送文件,而且数据将归入到咱们的核算剖析中。咱们发现这些世界文件是以当地钱银核算的投币量。为了正确地对数据建模,咱们要将数据转化为美元。
场景如下:
文件来历:英国
运用钱银:英镑
将英镑转化为美元的公式非常简略,只要用数额乘以汇率即可。所以,在R中:
MyData$Coinin《-MyData$Coinin* 1.4
以上代码能够完结咱们想要的转化;可是,数据科学家要决议那种钱银将被转化(英镑)以及汇率应当是多少。这并不是什么大问题,可是咱们能够测验创立一个用户界说的函数来确认要运用的汇率,如下所示:
getRate《- funcTIon(arg){ if(arg==“GPB”) { myRate 《- 1.4 } if(arg==“CAD”) { myRate 《-1.34 } return(myRate) }
虽然之前的代码更简略,但以上代码说明晰创立逻辑的关键,以便咱们往后能够重复运用:
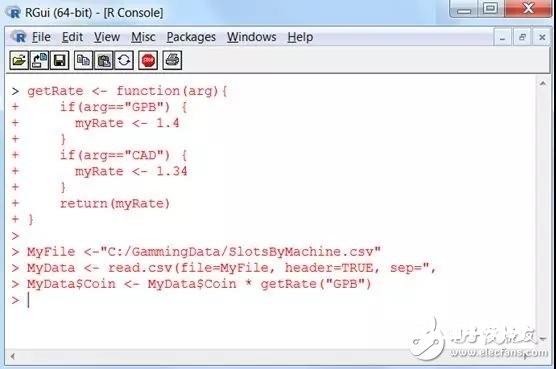
终究,为了使整个进程更完美,咱们要将函数贮存(在R文档中)以便将来运用:
source(“C:/GammingData/CurerncyLogic.R”)
随后:
MyFile《-“C:/GammingData/SlotsByMachine.csv” MyData《- read.csv(file=MyFile, header=TRUE, sep=“,”) MyData$Coin《- MyData$Coinin * getRate(“CAD”)
注:当然,在最抱负的状况下,咱们可改善函数以便在表或文件中依据国家代码查找汇率,这样汇率能够随即时价值而改动而且能够从程序中解耦数据。
数据谐和
依据研讨剖析的全体方针,数据科学家能够经过数据谐和来转化、翻译、或将数据值映射到其他抱负值。最遍及的事例是性别或国家代码。例如,假如你的文档中将性别编码为0和1或M和F,你想将数据转化为共同的MALE或FEMALE。
关于国家代码,数据科学家想要制作区域的汇总:北美、南美和欧洲,而不是分隔的美国、加拿大、墨西哥、巴西、智利、英国、法国和德国。在这种状况下,将发生算计值如下:
北美=美国+加拿大+墨西哥
南美=巴西+智利
欧洲=英国+法国+德国
需求着重的是,数据科学家或许会将一切包含性别的查询文档兼并在一起,称为gender.txt,可是文档中的性别编码不同(1,0,M,F,Male和Female)。假如咱们测验用R函数表,咱们会看到如下可了解的成果:
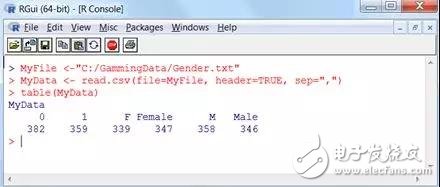
假如在最抱负的状态下进行可视化剖析:
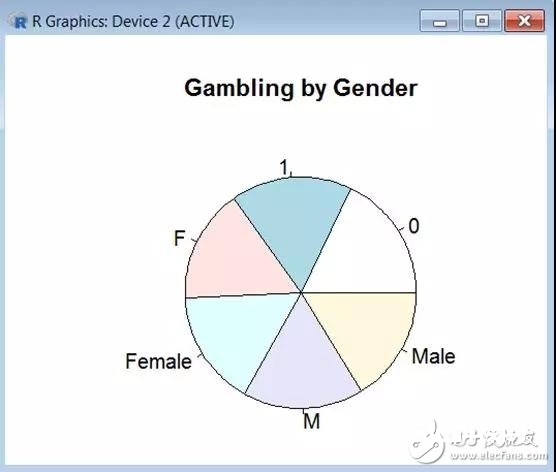
lbs= c(“Male”, “Female”) pie(table(MyData),main=“Gambling by Gender”)
咱们看到如下截图:
为了处理性别数据编码不共同的问题,我借用了前文事例中的概念并生成简略的函数来协助咱们从头编码:
setGender《- funcTIon(arg){ if(substr(arg,1,1)==“0”| toupper(substr(arg,1,1))==“M”) { Gender 《- “MALE” } if(substr(arg,1,1)==“1”| toupper(substr(arg,1,1))==“F”) { Gender 《- “FEMALE” } return(Gender) }
此次,我加入了toupper函数,因而咱们不用忧虑大小写,而且有substr来操控长度大于一个字符的值。
注:假定参数的值是0,1,m,M,f,F,Male或Female,不然将会引发报错。
由于R将性别作为向量类型,我发现很难运用简略的函数,所以我决议生成新的R数据框来包容谐和后的数据。而且用一个循环来读入文档中的记载并将其转化为Male 或Female:
MyFile《-“C:/GammingData/Gender.txt” MyData《- read.csv(file=MyFile, header=TRUE, sep=“,”) GenderData《-data.frame(nrow(MyData)) for(iin 2:nrow(MyData)) { x《-as.character(MyData[i,1]) GenderData[i,1] 《-setGender(x) }
现在咱们将经过以下句子得到更适合的可视化成果:
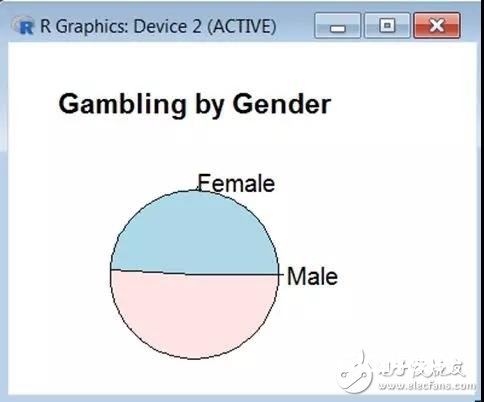
lbls= c(“Male”, “Female”) pie(table(GenderData),labels=lbls, main=“Gambling by Gender”)
以上代码的输出成果如下所示:
规范化
大多数干流数据科学家都现已留意到在开端核算研讨或剖析项目之前,将数据规范化作为数据整理进程一部分的重要性。这是很重要的,假如没有规范化,量纲不同的数据点对剖析的奉献会不平等。
假如你以为在0到100之间的数据点比0到1规模内的变量影响更大,你能够了解数据规范化的重要性。运用这些未经过规范化的变量,现实上在剖析中赋予较大规模的变量更多的权重。为了处理这一问题并均衡这些变量,数据科学家企图将数据转化为可比的量纲。
数据点的中心化是数据规范化中最常见的比如(虽然还有许多)。为了使数据点中心化,数据科学家把文件中的每个数据点减去一切数据的平均值。
R不是做运算,它供给了scale函数,其默许办法能够经过一行代码将文件中的数值中心化或减缩。让咱们来看一个简略的比如。
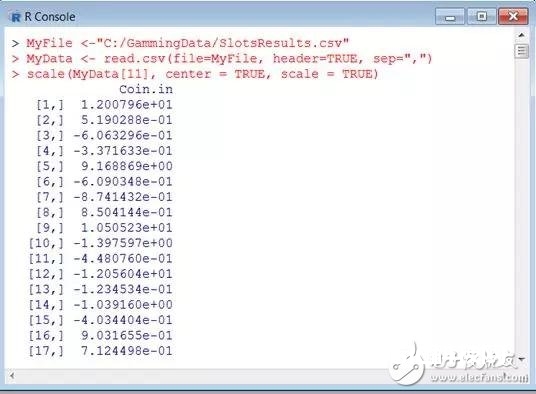
回到老虎机的事例中!在咱们的赌博文件中,你或许还记得有一个字段叫投币量(Coinin),它是一个表明投入到机器中美元总额的值,这被看作衡量机器盈余才能的方针。这似乎是咱们盈余才能剖析中运用的一个重要的数据点。可是这些金额或许是误导性的,由于不同的机器有不同面额(换句话说,一些机器承受美分,而其他机器承受一角硬币或美元)。或许机器面值的不同造成了不同的量纲,咱们能够运用scale函数来处理这种状况。首要,咱们鄙人面的截图中看到,Coin.in的值:
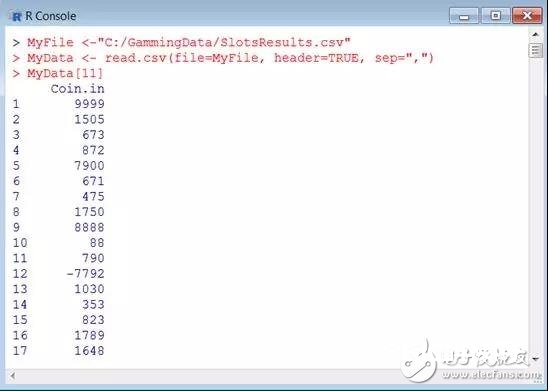
咱们能够经过以下句子对数据点Coin.in进行中心化处理:
scale(MyData[11],center = TRUE, scale = TRUE)
center的值决议了怎么行中心化。center为TRUE是需求对应的行减去Coin.in均值(省掉NA)。scale的值决议了怎么行缩放(在中心化之后)。假如scale的值是TRUE且center值是TRUE,那么缩放是经过除以(中心化后的)Coin.in的规范差来进行的。假如center值是False,将得到均方根值。
鄙人图截屏中看到了不同: