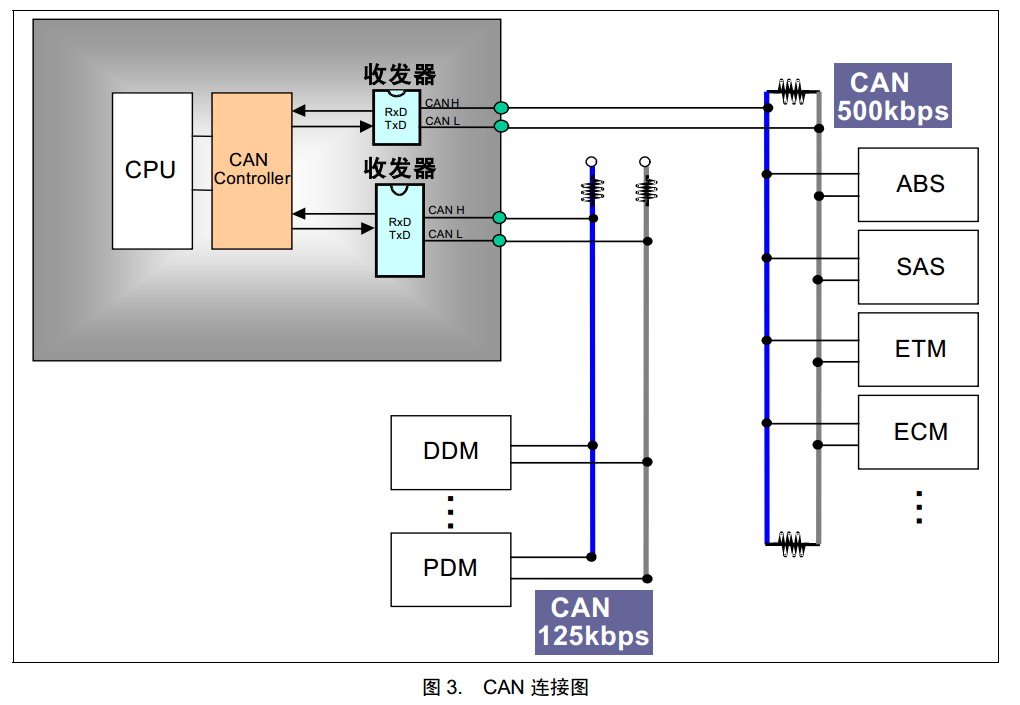
labview同其它任何高档言语相同,都支撑多种根本数据类型和复合数据类型,根本数据类型包括U8、U16、U32、I8、I16、I32,SGL,DBL,EXT等等,复合数据类型包括数组、簇、字符串、途径等。
同其它高档言语相同,也具有根本的程序结构,比方,次序结构、条件结构,循环结构等。也具有一些自己共同的程序结构,如行列、布告、信号、调集等等。
无论是数据类型仍是程序结构,都是和内存的运用严密地结合在一起的,所以深化地了解数据类型和类型之间的转化以及结构在内存中的存储办法是非常重要的。
LABVIEW 中涉及到数据类型转化时,会引起内存仿制操作。大的数据类型结构比方数组,字符串和簇在内存中实践占的空间比咱们料想的要大,因为LABVIEW一起在内存中也添加了许多必要的信息,正如咱们在类型描述符中谈到的。运用局部变量和全局变量也要引起内存的仿制操作,可是,恰当的编程办法能够防止这个问题。
(一)类型转化是怎么运用内存的
类型转化会发生两个问题:添加了类型转化时刻 需求拓荒新的BUFFER,增大了内存空间的运用。
有些类型转化是必要的,可是更多的情况下是咱们编程时不注意构成的,关于人为发生的类型转化要竭力防止。
LV是图形化编程办法,连线的色彩和线型代表了不同的数据类型,一起在转化处还会有一个强制转化点,一般是黑色或许赤色,咱们很简单看到在那里发生了隐含的类型转化。
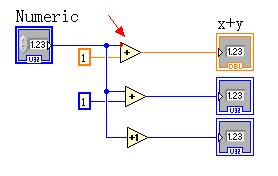
上面三个都是要完结+1操作,因为+节点虽然是多态的,能够习惯各种数据类型,可是默许是DOUBLE型的,因为我先生成了常量1,黄色,导致U32在+节点处发生的类型转化,最终输出的是DOUBLE类型。而第二个我是先衔接的U32,后主动生成的常量1,LABVIEW主动发生的U32常量而不是 DOUBLE,第三个直接调用+1节点,所以不会发生类型转化。所以编程风格是非常重要
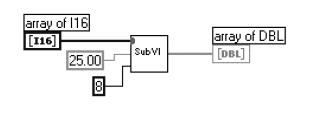
上面的图中,因为SUBVI需求的是DOUBLE类型的数组,而输入数组是I16的,所以发生了一个强制转化点,因而,会发生同I16SIZE相同的额定的DOUBLE数组。
关于SIZE非常大的数组,不恰当的类型转化耗费的内存是惊人的,看下面的图
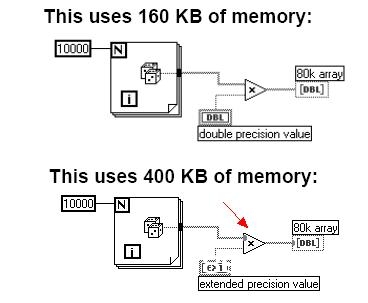
上图第一个框图,循环发生10000*64=80K的数组,因为没有类型转化,有效地内存重用,数据流上的履行数据是80K,前面板数组指示器的操作数据是80K,总计160K
看看上图中第二个框图,他用了惊人的400K,不过是乘以一个扩展精度的标量,构成一个扩展精度的数组,然后右从头强制转化成DOUBLE数组。看一下是怎么发生的。
—循环80K
—强制转化乘法后,数据流上的履行数据是160K
—强制转化成DOUBLE数组,生成别的的80K履行数据
—数组指示器 80K操作数据
总计:80K+160K+80K+80K=400K
能够看出中心乘法端子呈现的EXT是毫无意义的,不经意间,额定的240K内存被耗费掉了。
所以在数据流中假如数据类型不变,咱们将节约240K的内存,一个重要的准则便是:
尽量一直在数据流中坚持同一种数据类型
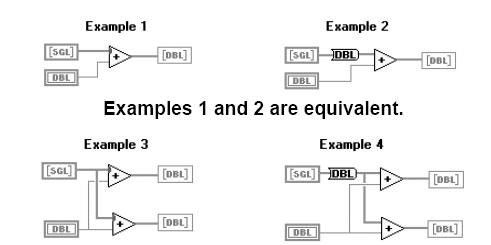
上图中,EXAMPEL1和EXAMPLE2是根本适当的,一个是隐含的强制转化点,一个是用显式的SGL–》DOUBLE转化节点,
它们用的内存是彻底相同的,但功能略微有些差异,隐含转化速度略微快了一点,而且节约的框图的空间,比较便利。
而EXAMPE 3和EXAMPLE 4则是彻底不同的,EXAPLE 3发生了二次隐含强制转化,而EXAPLE 4只要一次显式转化。节约了内存和运转时刻。
转化的方位也是很重要的,看看下面的图
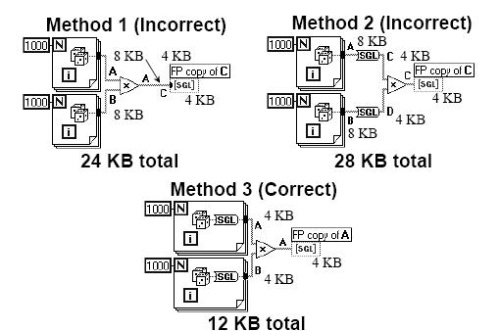
办法一中,两个数组别离发生8K的数据,其间上面的A的8K通过乘法后得到重用,在转化C处,发生了4K的履行数据(SGL 4BYTE),加上指示器中的操作数据4K,总计24K
办法二中,两个数组别离发生8K的数据,显式转化后,C、D处各发生4K的履行数据,乘法后C处的4K得到重用,加上指示器中操作数据4K,总计:8k+8k+4k+4k+4k=28k
办法三中,循环中对DOUBLE数据显式转化成SGL,因而两个数组各发生4K的数据,其间A处的4K通过乘法节点后得到重用,加上指示器的4K,总计12K。
关于标量,比方DOUBLE,64位,8个字节,即便发生了强制类型转化,能够不必要考虑的它的内存丢失。关于字符串和数组,因为它的SIZE是很简单被改动的又没有SIZE约束,要特别注重。
(二)数组和字符串
LABVIEW中的数组和字符串操作是最影响内存的运用和程序的运转速度。它影响速度的原因在于不断调用内存管理器来改动数组或许字符串的SIZE,LABVIEW自身也会在必要的时分改动数组和字符串的存储方位,比方在内存严重的时分,或许被转移到虚拟内存。
上面的节点是需求特别注意的,因为它们都直接改动的数组和字符串的巨细(元素个数),需求不断地调用内存管理器,假如是在一个循环中,会极大地下降程序的功能。
要点看一下BUILD ARRAY函数节点。
数组所占内存的总量,等于元素个数(size)乘以每个元素所占字节数。
比方包括10000个数据的DOUBLE类型,DOUBLE 64位,8个字节,占内存总量=10K*8=80K,但这是数组最终所占的字节数。当你改动数组巨细时,因为LV不能重用输入BUFFER,有必要进行额定的内存仿制,所以在改动的过程中,会极大耗费内存。所以为了有效地使用内存,尽量不要在循环中改动数组或许字符串的巨细。这样就能够重用输入BUFFER 到输出BUFFER。
树立一个数组有许多种办法,各种办法有很大差异。
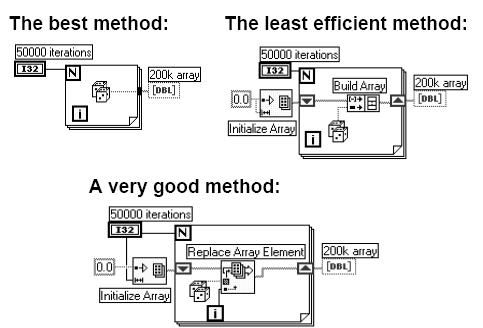
for循环是固定次数循环,因而在循环开端之前,就会为索引输出的数组请求内存空间,一次完结,在循环内部,不需求改动数组的巨细,因而功率是最高的。
第二种办法是功率最差的,每次循环时都要添加数组的巨细,循环调用内存管理器,是需求竭力防止的办法。
第三种办法用的初始化数组节点,整个数组的的内存空间也是一次请求的,在循环中替换数组的各个元素,而替换操作是能够重用内存的,这也是一个常用的比较好的办法,可是FOR循环是LV的根本结构,所以无疑功率是最高的。