深化了解RCU完结
——依据内核2.6.21RCU完结
RCU(Read-Copy Update),望文生义便是读-仿制修正,它是依据其原理命名的。关于被RCU保护的同享数据结构,读者不需求取得任何锁就能够拜访它,但写者在拜访它时首要仿制一个副本,然后对副本进行修正,最终运用一个回调(callback)机制在恰当的机遇把指向本来数据的指针从头指向新的被修正的数据。那么这个“恰当的机遇”是怎样确认的呢?这是由内核确认的,也是咱们后边评论的要点。
RCU原理
RCU实践上是一种改善的rwlock,读者简直没有什么同步开支,它不需求锁,不运用原子指令,并且在除alpha的一切架构上也不需求内存栅(Memory Barrier),因而不会导致锁竞赛,内存推迟以及流水线阻滞。不需求锁也使得运用更简略,由于死锁问题就不需求考虑了。写者的同步开支比较大,它需求推迟数据结构的开释,仿制被修正的数据结构,它也有必要运用某种锁机制同步并行的其它写者的修正操作。
读者有必要供给一个信号给写者以便写者能够确认数据能够被安全地开释或修正的机遇。有一个专门的废物收集器来勘探读者的信号,一旦一切的读者都现已发送信号奉告它们都不在运用被RCU保护的数据结构,废物收集器就调用回调函数完结最终的数据开释或修正操作。
RCU与rwlock的不同之处是:它既答应多个读者一同拜访被保护的数据,又答应多个读者和多个写者一同拜访被保护的数据(留意:是否能够有多个写者并行拜访取决于写者之间运用的同步机制),读者没有任何同步开支,而写者的同步开支则取决于运用的写者间同步机制。但RCU不能代替rwlock,由于假设写比较多时,对读者的功能进步不能弥补写者导致的丢失。
读者在拜访被RCU保护的同享数据期间不能被堵塞,这是RCU机制得以完结的一个基本条件,也就说当读者在引证被RCU保护的同享数据期间,读者地点的CPU不能产生上下文切换,spinlock和rwlock都需求这样的条件。写者在拜访被RCU保护的同享数据时不需求和读者竞赛任何锁,只要在有多于一个写者的状况下需求取得某种锁以与其他写者同步。
写者修正数据前首要仿制一个被修正元素的副本,然后在副本上进行修正,修正结束后它向废物收回器注册一个回调函数以便在恰当的机遇履行真实的修正操作。等候恰当机遇的这一时期称为grace period,而CPU产生了上下文切换称为阅历一个quiescent state,grace period便是一切CPU都阅历一次quiescent state所需求的等候的时刻。废物收集器便是在grace period之后调用写者注册的回调函数来完结真实的数据修正或数据开释操作的。
要想运用好RCU,就要知道RCU的完结原理。咱们拿linux 2.6.21 kernel的完结开端剖析,为什么挑选这个版其他完结呢?由于这个版其他完结相对较为单纯,也比较简略。当然之后内核做了不少改善,如抢占RCU、可睡觉RCU、分层RCU。可是基本思维都是相似的。所以先从简略下手。
首要,上一节咱们说到,写者在拜访它时首要仿制一个副本,然后对副本进行修正,最终运用一个回调(callback)机制在恰当的机遇把指向本来数据的指针从头指向新的被修正的数据。而这个“恰当的机遇”便是一切CPU阅历了一次进程切换(也便是一个grace period)。为什么这么规划?由于RCU读者的完结便是关抢占履行读取,读完了当然就能够进程切换了,也就等所以写者能够操作临界区了。那么就天然能够想到,内核会规划两个元素,来别离表明写者被挂起的起始点,以及每cpu变量,来表明该cpu是否经过了一次进程切换(quies state)。便是说,当写者被挂起后,
1)重置每cpu变量,值为0。
2)当某个cpu阅历一次进程切换后,就将自己的变量设为1。
3)当一切的cpu变量都为1后,就能够唤醒写者了。
下面咱们来别离看linux里是怎样完结这三步的。
从一个比如开端
咱们从一个比如下手,这个比如来源于linux kernel文档中的whatisRCU.txt。这个比如运用RCU的中心API来保护一个指向动态分配内存的大局指针。
C++
struct foo {int a; char b; long c;};DEFINE_SPINLOCK(foo_mutex);struct foo *gbl_foo;void foo_update_a(int new_a){ struct foo *new_fp;struct foo *old_fp;new_fp = kmalloc(sizeof(*new_fp), GFP_KERNEL);spin_lock(&foo_mutex);old_fp = gbl_foo;*new_fp = *old_fp;new_fp->a = new_a;rcu_assign_pointer(gbl_foo, new_fp);spin_unlock(&foo_mutex);synchronize_rcu();kfree(old_fp);}int foo_get_a(void){ int retval;rcu_read_lock();retval = rcu_dereference(gbl_foo)->a;rcu_read_unlock();return retval; }
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
struct foo {
int a;
char b;
long c;
};
DEFINE_SPINLOCK(foo_mutex);
struct foo *gbl_foo;
void foo_update_a(int new_a)
{
struct foo *new_fp;
struct foo *old_fp;
new_fp = kmalloc(sizeof(*new_fp), GFP_KERNEL);
spin_lock(&foo_mutex);
old_fp = gbl_foo;
*new_fp = *old_fp;
new_fp->a = new_a;
rcu_assign_pointer(gbl_foo, new_fp);
spin_unlock(&foo_mutex);
synchronize_rcu();
kfree(old_fp);
}
int foo_get_a(void)
{
int retval;
rcu_read_lock();
retval = rcu_dereference(gbl_foo)->a;
rcu_read_unlock();
return retval;
}
如上代码所示,RCU被用来保护大局指针struct foo *gbl_foo。foo_get_a()用来从RCU保护的结构中取得gbl_foo的值。而foo_update_a()用来更新被RCU保护的gbl_foo的值(更新其a成员)。
首要,咱们考虑一下,为什么要在foo_update_a()中运用自旋锁foo_mutex呢?假定中心没有运用自旋锁.那foo_update_a()的代码如下:
C++
void foo_update_a(int new_a) { struct foo *new_fp; struct foo *old_fp; new_fp = kmalloc(sizeof(*new_fp), GFP_KERNEL); old_fp = gbl_foo; 1:————————- *new_fp = *old_fp; new_fp->a = new_a; rcu_assign_pointer(gbl_foo, new_fp); synchronize_rcu(); kfree(old_fp); }
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
void foo_update_a(int new_a)
{
struct foo *new_fp;
struct foo *old_fp;
new_fp = kmalloc(sizeof(*new_fp), GFP_KERNEL);
old_fp = gbl_foo;
1:————————-
*new_fp = *old_fp;
new_fp->a = new_a;
rcu_assign_pointer(gbl_foo, new_fp);
synchronize_rcu();
kfree(old_fp);
}
假定A进程在上图—-标识处被B进程抢点.B进程也履行了goo_ipdate_a().等B履行完后,再切换回A进程.此刻,A进程所持的old_fd实践上现已被B进程给开释掉了.尔后A进程对old_fd的操作都是不合法的。所以在此咱们得到一个重要定论:RCU答应多个读者一同拜访被保护的数据,也答应多个读者在有写者时拜访被保护的数据(可是留意:是否能够有多个写者并行拜访取决于写者之间运用的同步机制)。
阐明:本文中说的进程不是用户态的进程,而是内核的调用途径,也或许是内核线程或软中止等。
RCU的中心API
其他,咱们在上面也看到了几个有关RCU的中心API。它们为别是:
C++
rcu_read_lock() rcu_read_unlock() synchronize_rcu() rcu_assign_pointer() rcu_dereference()
1
2
3
4
5
rcu_read_lock()
rcu_read_unlock()
synchronize_rcu()
rcu_assign_pointer()
rcu_dereference()
其间,rcu_read_lock()和rcu_read_unlock()用来坚持一个读者的RCU临界区.在该临界区内不答应产生上下文切换。为什么不能产生切换呢?由于内核要依据“是否产生过切换”来判别读者是否已结束读操作,咱们后边再剖析。
rcu_dereference():读者调用它来取得一个被RCU保护的指针。
rcu_assign_pointer():写者运用该函数来为被RCU保护的指针分配一个新的值。
synchronize_rcu():这是RCU的中心地点,它挂起写者,等候读者都退出后开释老的数据。
RCU API完结剖析
lrcu_read_lock()和rcu_read_unlock()
rcu_read_lock()和rcu_read_unlock()的完结如下:
C++
#define rcu_read_lock() __rcu_read_lock() #define rcu_read_unlock() __rcu_read_unlock() #define __rcu_read_lock() do { preempt_disable(); __acquire(RCU); rcu_read_acquire(); } while (0) #define __rcu_read_unlock() do { rcu_read_release(); __release(RCU); preempt_enable(); } while (0)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
#define rcu_read_lock() __rcu_read_lock()
#define rcu_read_unlock() __rcu_read_unlock()
#define __rcu_read_lock()
do {
preempt_disable();
__acquire(RCU);
rcu_read_acquire();
} while (0)
#define __rcu_read_unlock()
do {
rcu_read_release();
__release(RCU);
preempt_enable();
} while (0)
其间__acquire(),rcu_read_acquire(),rcu_read_release(),__release()都是一些挑选编译函数,能够疏忽不可看。因而能够得知:rcu_read_lock(),rcu_read_unlock()只是制止和启用抢占.由于在读者临界区,不答应产生上下文切换。
lrcu_dereference()和rcu_assign_pointer()
rcu_dereference()和rcu_assign_pointer()的完结如下:
C++
rcu_dereference()和rcu_assign_pointer()的完结如下: #define rcu_dereference(p) ({ typeof(p) _________p1 = ACCESS_ONCE(p); smp_read_barrier_depends(); (_________p1); }) #define rcu_assign_pointer(p, v) ({ if (!__builTIn_constant_p(v) || ((v) != NULL)) smp_wmb(); (p) = (v); })
1
2
3
4
5
6
7
8
9
10
11
12
rcu_dereference()和rcu_assign_pointer()的完结如下:
#define rcu_dereference(p) ({
typeof(p) _________p1 = ACCESS_ONCE(p);
smp_read_barrier_depends();
(_________p1);
})
#define rcu_assign_pointer(p, v)
({
if (!__builTIn_constant_p(v) || ((v) != NULL))
smp_wmb();
(p) = (v);
})
它们的完结也很简略.由于它们自身都是原子操作。只是为了cache一致性,插上了内存屏障。能够让其它的读者/写者能够看到保护指针的最新值.
lsynchronize_rcu()
synchronize_rcu()在RCU中是一个最中心的函数,它用来等候之前的读者悉数退出.咱们后边的大部份剖析也是围绕着它而进行.完结如下:
C++
void synchronize_rcu(void) { struct rcu_synchronize rcu; init_compleTIon(&rcu.compleTIon); /* Will wake me after RCU finished */ call_rcu(&rcu.head, wakeme_after_rcu); /* Wait for it */ wait_for_completion(&rcu.completion); }
1
2
3
4
5
6
7
8
9
10
void synchronize_rcu(void)
{
struct rcu_synchronize rcu;
init_completion(&rcu.completion);
/* Will wake me after RCU finished */
call_rcu(&rcu.head, wakeme_after_rcu);
/* Wait for it */
wait_for_completion(&rcu.completion);
}
咱们能够看到,它初始化了一个本地变量,它的类型为struct rcu_synchronize.调用call_rcu()之后.一向等候条件变量rcu.competion的满意。
在这儿看到了RCU的另一个中心API,它便是call_run()。它的界说如下:
C++
void call_rcu(struct rcu_head *head, void (*func)(struct rcu_head *rcu)) { unsigned long flags; struct rcu_data *rdp; head->func = func; head->next = NULL; local_irq_save(flags); rdp = &__get_cpu_var(rcu_data); *rdp->nxttail = head; rdp->nxttail = &head->next; if (unlikely(++rdp->qlen > qhimark)) { rdp->blimit = INT_MAX; force_quiescent_state(rdp, &rcu_ctrlblk); } local_irq_restore(flags); }
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
void call_rcu(struct rcu_head *head, void (*func)(struct rcu_head *rcu))
{
unsigned long flags;
struct rcu_data *rdp;
head->func = func;
head->next = NULL;
local_irq_save(flags);
rdp = &__get_cpu_var(rcu_data);
*rdp->nxttail = head;
rdp->nxttail = &head->next;
if (unlikely(++rdp->qlen > qhimark)) {
rdp->blimit = INT_MAX;
force_quiescent_state(rdp, &rcu_ctrlblk);
}
local_irq_restore(flags);
}
该函数也很简略,便是将参数传入的回调函数fun赋值给一个struct rcu_head变量,再将这个struct rcu_head加在了per_cpu变量rcu_data的nxttail 链表上。
rcu_data界说如下,是个每cpu变量:
DEFINE_PER_CPU(struct rcu_data, rcu_data) = { 0L };
接着咱们看下call_rcu注册的函数,咱们也能够看到,在synchronize_rcu()中,传入call_rcu的函数为wakeme_after_rcu(),其完结如下:
C++
static void wakeme_after_rcu(struct rcu_head *head) { struct rcu_synchronize *rcu; rcu = container_of(head, struct rcu_synchronize, head); complete(&rcu->completion); }
1
2
3
4
5
6
7
static void wakeme_after_rcu(struct rcu_head *head)
{
struct rcu_synchronize *rcu;
rcu = container_of(head, struct rcu_synchronize, head);
complete(&rcu->completion);
}
咱们能够看到,该函数将条件变量置真,然后唤醒了在条件变量上等候的进程。
由此,咱们能够得知,每一个CPU都有一个rcu_data.每个调用call_rcu()/synchronize_rcu()进程的进程都会将一个rcu_head都会挂到rcu_data的nxttail链表上(这个rcu_head其实就相当于这个进程在RCU机制中的表现),然后挂起。当读者都完结读操作后(经过一个grace period后)就会触发这个rcu_head上的回调函数来唤醒写者。整个进程如下图所示:
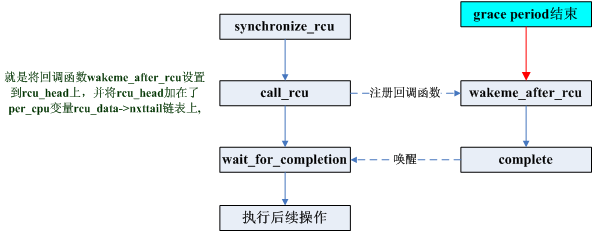
看到这儿,也就到了问题的要害,内核是怎样判别当时读者都现已完结读操作了呢(经过了一个grace period)?又是由谁来触发这个回调函数wakeme_after_rcu呢?下一末节再来剖析。
从RCU的初始化说起
那终究怎样去判别当时的读者现已操作完了呢?咱们在之前看到,不是读者在调用rcu_read_lock()的时分要制止抢占么?因而,咱们只需求判别一切的CPU都进过了一次上下文切换,就阐明一切读者现已退出了。要彻底弄清楚这个问题,咱们得从RCU的初始化说起。
RCU的初始化开端于start_kernel()–>rcu_init()。而其首要是对每个cpu调用了rcu_online_cpu函数。
lrcu_online_cpu
C++
static void __cpuinit rcu_online_cpu(int cpu) { struct rcu_data *rdp = &per_cpu(rcu_data, cpu); struct rcu_data *bh_rdp = &per_cpu(rcu_bh_data, cpu); rcu_init_percpu_data(cpu, &rcu_ctrlblk, rdp); rcu_init_percpu_data(cpu, &rcu_bh_ctrlblk, bh_rdp); open_softirq(RCU_SOFTIRQ, rcu_process_callbacks, NULL); }
1
2
3
4
5
6
7
8
9
static void __cpuinit rcu_online_cpu(int cpu)
{
struct rcu_data *rdp = &per_cpu(rcu_data, cpu);
struct rcu_data *bh_rdp = &per_cpu(rcu_bh_data, cpu);
rcu_init_percpu_data(cpu, &rcu_ctrlblk, rdp);
rcu_init_percpu_data(cpu, &rcu_bh_ctrlblk, bh_rdp);
open_softirq(RCU_SOFTIRQ, rcu_process_callbacks, NULL);
}
这个函数首要完结两个操作:初始化两个per cpu变量;注册RCU_SOFTIRQ软中止处理函数rcu_process_callbacks。咱们从这儿又看到了另一个percpu变量:rcu_bh_data.有关bh的部份之后再来剖析.在这儿略过这些部分。下面看下rcu_init_percpu_data()的完结。
lrcu_init_percpu_data
C++
static void rcu_init_percpu_data(int cpu, struct rcu_ctrlblk *rcp, struct rcu_data *rdp) { memset(rdp, 0, sizeof(*rdp)); rdp->curtail = &rdp->curlist; rdp->nxttail = &rdp->nxtlist; rdp->donetail = &rdp->donelist; rdp->quiescbatch = rcp->completed; rdp->qs_pending = 0; rdp->cpu = cpu; rdp->blimit = blimit; }
1
2
3
4
5
6
7
8
9
10
11
static void rcu_init_percpu_data(int cpu, struct rcu_ctrlblk *rcp, struct rcu_data *rdp)
{
memset(rdp, 0, sizeof(*rdp));
rdp->curtail = &rdp->curlist;
rdp->nxttail = &rdp->nxtlist;
rdp->donetail = &rdp->donelist;
rdp->quiescbatch = rcp->completed;
rdp->qs_pending = 0;
rdp->cpu = cpu;
rdp->blimit = blimit;
}
调用这个函数的第二个参数是一个大局变量rcu_ctlblk。在持续向下剖析之前咱们先看下这些函数用到的一些重要数据结构。
重要数据结构
阐明:下列数据结构只列出了首要成员。
C++
struct rcu_ctrlblk { long cur; long completed; cpumask_t cpumask; };
1
2
3
4
5
struct rcu_ctrlblk {
long cur;
long completed;
cpumask_t cpumask;
};
structrcu_ctrlblk的首要效果便是界说上节说到的大局变量rcu_ctlblk,这个变量在体系中是仅有的。其他阐明一下,为了记载便利,内核将从发动开端的每个grace period对应一个数字表明。
这儿的cpumask是为了标识当时体系中的一切cpu,以便符号哪些cpu产生过上下文切换(阅历过一个quiescent state)。而cur,completed,则用来同步。咱们能够这样了解,cur和completed是体系等级的记载信息,也即体系实时阅历的grace编号,一般状况下,新开一个graceperiod等候周期的话,cur会加1,当graceperiod结束后,会将completed置为cur,所以通常状况下,都是completed追着cur跑。
那么咱们或许会猜想,是不是假设complete= curr -1 的时分,就表明体系中graceperiod还没有结束?当completed= curr的时分,就表明体系中不存在graceperiod等候周期了?咱们权且这么了解,实践上有少许不同,但规划思维都是相同的。
C++
struct rcu_data { long quiescbatch; int passed_quiesc; long batch; struct rcu_head *nxtlist; struct rcu_head **nxttail; struct rcu_head *curlist; struct rcu_head **curtail; struct rcu_head *donelist; struct rcu_head **donetail; };
1
2
3
4
5
6
7
8
9
10
11
struct rcu_data {
long quiescbatch;
int passed_quiesc;
long batch;
struct rcu_head *nxtlist;
struct rcu_head **nxttail;
struct rcu_head *curlist;
struct rcu_head **curtail;
struct rcu_head *donelist;
struct rcu_head **donetail;
};
上面的结构,要到达的效果是,盯梢单个CPU上的RCU业务。
(1)passed_quiesc:这是一个flag标志,表明当时cpu是否现已产生过抢占了(阅历过一个quiescent state),0表明为未发送过切换,1表明产生过切换;
阐明:咱们一向着重产生过一次cpu抢占便是阅历过一个quiescent state,其实这是不严厉的说法。为什么呢?由于自体系发动,各种进程频频调度,必定每个cpu都会产生过抢占。所以咱们这儿说的“产生过抢占”是指从某个特其他时刻点开端产生过抢占。那么这个特其他时刻点是什么时分呢?便是咱们调用synchronize_rcu将rcu_head挂在每cpu变量上并挂起进程时,咱们后边剖析就会证明这一点。
(2) batch:表明一个graceperiodid,表明本次被堵塞的写者,需求在哪个graceperiod之后被激活;
(3) quiescbatch:表明一个graceperiodid,用来比较当时cpu是否处于等候进程切换完结。
下面咱们介绍剩余的三组指针,但首要留意这三组链表上的元素都是structrcu_head类型。这三个链表的效果还要结合整个RCU写者从堵塞到唤醒的进程来看。
rcu写者的全体流程,假定体系中呈现rcu写者堵塞,那么流程如下:
(1) 调用synchronize_rcu,将代表写者的rcu_head添加到CPU[n]每cpu变量rcu_data的nxtlist,这个链表代表有需求提交给rcu处理的回调(但还没有提交);
(2) CPU[n]每次时钟中止时检测自己的nxtlist是否为null,若不为空,因而则唤醒rcu软中止;
(3) RCU的软中止处理函数rcu_process_callbacks会挨个查看本CPU的三个链表。
下面剖析RCU的中心处理函数,也便是软中止处理函数rcu_process_callbacks。
RCU软中止
在“RCU API完结剖析”一节咱们知道调用synchronize_rcu,将代表写者的rcu_head添加到了CPU[n]每cpu变量rcu_data的nxtlist。
而另一方面,在每次时钟中止中,都会调用update_process_times函数。
lupdate_process_times
C++
void update_process_times(int user_tick) { //…… if (rcu_pending(cpu)) rcu_check_callbacks(cpu, user_tick); //……}
1
2
3
4
5
6
7
void update_process_times(int user_tick)
{
//……
if (rcu_pending(cpu))
rcu_check_callbacks(cpu, user_tick);
//……
}
在每一次时钟中止,都会查看rcu_pending(cpu)是否为真,假设是,就会为其调用rcu_check_callbacks()。
lrcu_pending
rcu_pending()的代码如下:
C++
int rcu_pending(int cpu) { return __rcu_pending(&rcu_ctrlblk, &per_cpu(rcu_data, cpu)) || __rcu_pending(&rcu_bh_ctrlblk, &per_cpu(rcu_bh_data, cpu)); }
1
2
3
4
5
int rcu_pending(int cpu)
{
return __rcu_pending(&rcu_ctrlblk, &per_cpu(rcu_data, cpu)) ||
__rcu_pending(&rcu_bh_ctrlblk, &per_cpu(rcu_bh_data, cpu));
}
同上面相同,疏忽bh的部份,咱们看__rcu_pending。
l__rcu_pending
C++
static int __rcu_pending(struct rcu_ctrlblk *rcp, struct rcu_data *rdp) { /* This cpu has pending rcu entries and the grace period * for them has completed. */ if (rdp->curlist && !rcu_batch_before(rcp->completed, rdp->batch)) return 1; /* This cpu has no pending entries, but there are new entries */ if (!rdp->curlist && rdp->nxtlist) return 1; /* This cpu has finished callbacks to invoke */ if (rdp->donelist) return 1; /* The rcu core waits for a quiescent state from the cpu */ if (rdp->quiescbatch != rcp->cur || rdp->qs_pending) return 1; /* nothing to do */ return 0; }
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
static int __rcu_pending(struct rcu_ctrlblk *rcp, struct rcu_data *rdp)
{
/* This cpu has pending rcu entries and the grace period
* for them has completed.
*/
if (rdp->curlist && !rcu_batch_before(rcp->completed, rdp->batch))
return 1;
/* This cpu has no pending entries, but there are new entries */
if (!rdp->curlist && rdp->nxtlist)
return 1;
/* This cpu has finished callbacks to invoke */
if (rdp->donelist)
return 1;
/* The rcu core waits for a quiescent state from the cpu */
if (rdp->quiescbatch != rcp->cur || rdp->qs_pending)
return 1;
/* nothing to do */
return 0;
}
能够上面有四种状况会回来1,别离对应:
A.该CPU上有等候处理的回调函数,且现现已过了一个batch(grace period).rdp->datch表明rdp在等候的batch序号;
B.上一个等候现已处理完了,又有了新注册的回调函数;
C.等候现已完结,但尚末调用该次等候的回调函数;
D.在等候quiescent state.
假设rcu_pending回来1,就会进入到rcu_check_callbacks(),rcu_check_callbacks()中首要作业便是调用raise_softirq(RCU_SOFTIRQ),触发RCU软中止。而RCU软中止的处理函数为rcu_process_callbacks,其间别离针对每cpu变量rcu_bh_data和rcu_data调用__rcu_process_callbacks。咱们首要剖析针对rcu_data的调用。
l__rcu_process_callbacks
1) 先看nxtlist里有没有待处理的回调(rcu_head),假设有的话,阐明有写者待处理,那么还要分两种状况:
1.1)假设体系是第一次呈现写者堵塞,也即之前的写者都现已处理结束,那么此刻curlist链表必定为空(curlist专门寄存已被rcu检测到的写者恳求),所以就把nxtlist里的一切成员都移动到curlist指向,并把当时CPU需求等候的graceperiodid:rdp->batch设置为当时体系处理的graceperiod的下一个grace周期,即rcp->cur+ 1。由于这算是一个新的graceperiod,即start_rcu_batch,所以还接着需求添加体系的graceperiod计数,即rcp->cur++,一同,将大局的cpusmask设置为全f,代表新的graceperiod开端,需求检测一切的cpu是否都经过了一次进程切换。代码如下:
C++
void __rcu_process_callbacks(struct rcu_ctrlblk *rcp, struct rcu_data *rdp) { if (rdp->nxtlist && !rdp->curlist) { move_local_cpu_nxtlist_to_curlist(); rdp->batch = rcp->cur + 1; if (!rcp->next_pending) { rcp->next_pending = 1; rcp->cur++; cpus_andnot(rcp->cpumask, cpu_online_map, nohz_cpu_mask); } } }
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
void __rcu_process_callbacks(struct rcu_ctrlblk *rcp,
struct rcu_data *rdp)
{
if (rdp->nxtlist && !rdp->curlist) {
move_local_cpu_nxtlist_to_curlist();
rdp->batch = rcp->cur + 1;
if (!rcp->next_pending) {
rcp->next_pending = 1;
rcp->cur++;
cpus_andnot(rcp->cpumask, cpu_online_map, nohz_cpu_mask);
}
}
}
接着跳转至1.2。
1.2) 假设体系之前现已有写者在被rcu监控着,但还没来得及经过一个graceperiod,这个时分curlist不为空,nxtlist也不为空,写者会被参加nxtlist中。由于curlist不为空,阐明上个rcu周期的写者还没有处理完,所以不会将本次堵塞的写者参加curlist,一向到前次的curlist里的rcu_head被处理完(都移动到了donelist),才会将后来的写者归入RCU考虑(移动到curlist)(假设这个期间又来了多个写者,则多个写者的rcu_head同享下一个graceperiod,也便是下一个graceperiod结束后这多个写者都会被唤醒)。进入下一步。
2) rcu_process_callbacks调用每CPU函数rcu_check_quiescent_state开端监控,检测一切的CPU是否会阅历一个进程切换。这个函数是怎样得知需求开端监控的? 答案在于quiescbatch与大局的rcp->cur比较。 初始化时rdp->quiescbatch =rcp->completed = rcp->cur。 由于1.1有新graceperiod敞开,所以rcp->cur现已加1了,所以rdp->quiescbatch和rcp->curr不等,从而将此cpu的rdp->passed_quiesc设为0,表明这个周期开端,我要等候这个cpu阅历一个进程切换,等候该CPU将passed_quiesc置为1。即与前面讲到的passed_quiesc标志置0的机遇符合。最终将rdp->quiescbatch置为 rcp->cur,以避免下次再进入软中止里将passed_quiesc重复置0。
C++
void rcu_check_quiescent_state(struct rcu_ctrlblk *rcp, struct rcu_data *rdp) { if (rdp->quiescbatch != rcp->cur) { /* start new grace period: */ rdp->qs_pending = 1; rdp->passed_quiesc = 0; rdp->quiescbatch = rcp->cur; return; } }
1
2
3
4
5
6
7
8
9
10
11
void rcu_check_quiescent_state(struct rcu_ctrlblk *rcp,
struct rcu_data *rdp)
{
if (rdp->quiescbatch != rcp->cur) {
/* start new grace period: */
rdp->qs_pending = 1;
rdp->passed_quiesc = 0;
rdp->quiescbatch = rcp->cur;
return;
}
}
3) 本次软中止结束,下次软中止到来,再次进入rcu_check_quiescent_state进行检测,假设本CPU的rdp->passed_quiesc现已置1,则需求cpu_quiet将本CPU标志位从大局的rcp->cpumask中铲除,假设cpumask为0了,则阐明自前次RCU写者被挂起以来,一切CPU都现已历了一次进程切换,所以本次rcu等候周期结束,将rcp->completed置为rcp->cur,重置cpumask为全f,并测验从头敞开一个新的grace period。咱们能够看到RCU用了如此多的同步标志,却少用spinlock锁,是多么奇妙的规划,不过这也进步了了解的难度。
C++
void rcu_check_quiescent_state(struct rcu_ctrlblk *rcp, struct rcu_data *rdp) { if (rdp->quiescbatch != rcp->cur) { /* start new grace period: */ rdp->qs_pending = 1; rdp->passed_quiesc = 0; rdp->quiescbatch = rcp->cur; return; } if (!rdp->passed_quiesc) return; /*this cpu has passed a quies state*/ if (likely(rdp->quiescbatch == rcp->cur)) { cpu_clear(cpu, rcp->cpumask); if (cpus_empty(rcp->cpumask)) rcp->completed = rcp->cur; } }
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
void rcu_check_quiescent_state(struct rcu_ctrlblk *rcp,
struct rcu_data *rdp)
{
if (rdp->quiescbatch != rcp->cur) {
/* start new grace period: */
rdp->qs_pending = 1;
rdp->passed_quiesc = 0;
rdp->quiescbatch = rcp->cur;
return;
}
if (!rdp->passed_quiesc)
return;
/*this cpu has passed a quies state*/
if (likely(rdp->quiescbatch == rcp->cur)) {
cpu_clear(cpu, rcp->cpumask);
if (cpus_empty(rcp->cpumask))
rcp->completed = rcp->cur;
}
}
4)下次再进入rcu软中止__rcu_process_callbacks,发现rdp->batch现已比rcp->completed小了(由于上一进程中,后者增大了),则将rdp->curlist上的回调移动到rdp->donelist里,接着还会再次进入rcu_check_quiescent_state,可是由于当时CPU的rdp->qs_pending现已为1了,所以不再往下铲除cpu掩码。__rcu_process_callbacks
代码变成了:
C++
void __rcu_process_callbacks(struct rcu_ctrlblk *rcp, struct rcu_data *rdp) { if (rdp->curlist && !rcu_batch_before(rcp->completed, rdp->batch)) { *rdp->donetail = rdp->curlist; rdp->donetail = rdp->curtail; rdp->curlist = NULL; rdp->curtail = &rdp->curlist; } if (rdp->nxtlist && !rdp->curlist) { move_local_cpu_nxtlist_to_curlist(); rdp->batch = rcp->cur + 1; if (!rcp->next_pending) { rcp->next_pending = 1; rcp->cur++; cpus_andnot(rcp->cpumask, cpu_online_map, nohz_cpu_mask); } } if (rdp->donelist) rcu_do_batch(rdp); }
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
void __rcu_process_callbacks(struct rcu_ctrlblk *rcp,
struct rcu_data *rdp)
{
if (rdp->curlist && !rcu_batch_before(rcp->completed, rdp->batch)) {
*rdp->donetail = rdp->curlist;
rdp->donetail = rdp->curtail;
rdp->curlist = NULL;
rdp->curtail = &rdp->curlist;
}
if (rdp->nxtlist && !rdp->curlist) {
move_local_cpu_nxtlist_to_curlist();
rdp->batch = rcp->cur + 1;
if (!rcp->next_pending) {
rcp->next_pending = 1;
rcp->cur++;
cpus_andnot(rcp->cpumask, cpu_online_map, nohz_cpu_mask);
}
}
if (rdp->donelist)
rcu_do_batch(rdp);
}
5)经过千山万水总算来到rcu_do_batch(假设rdp->donelist有的话)在此函数里,履行RCU写者挂载的回调,即wakeme_after_rcu。
lrcu_do_batch
C++
static void rcu_do_batch(struct rcu_data *rdp) { struct rcu_head *next, *list; int count = 0; list = rdp->donelist; while (list) { next = list->next; prefetch(next); list->func(list); list = next; if (++count >= rdp->blimit) break; } rdp->donelist = list; local_irq_disable(); rdp->qlen -= count; local_irq_enable(); if (rdp->blimit == INT_MAX && rdp->qlen) blimit = blimit; if (!rdp->donelist) rdp->donetail = &rdp->donelist; else raise_rcu_softirq(); }
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
static void rcu_do_batch(struct rcu_data *rdp)
{
struct rcu_head *next, *list;
int count = 0;
list = rdp->donelist;
while (list) {
next = list->next;
prefetch(next);
list->func(list);
list = next;
if (++count >= rdp->blimit)
break;
}
rdp->donelist = list;
local_irq_disable();
rdp->qlen -= count;
local_irq_enable();
if (rdp->blimit == INT_MAX && rdp->qlen)
blimit = blimit;
if (!rdp->donelist)
rdp->donetail = &rdp->donelist;
else
raise_rcu_softirq();
}
它遍历处理挂在链表上的回调函数.在这儿,留意每次调用的回调函数有最大值约束.这样做首要是避免一次调用过多的回调函数而产生不必要体系负载.假设donelist中还有没处理完的数据,翻开RCU软中止,在下次软中止到来的时分接着处理.
留意:
仅当体系检测到一个grace period的一切CPU都阅历了进程切换后,才会给体系一个信息要求发动新batch,在此期间的一切写者恳求,都暂存在本地CPU的nxtlist链表里。
进程切换
在每一次进程切换的时分,都会调用rcu_qsctr_inc().如下代码片段如示:
C++
asmlinkage void __sched schedule(void) { //……rcu_qsctr_inc(cpu); //…… }
1
2
3
4
5
6
asmlinkage void __sched schedule(void)
{
//……
rcu_qsctr_inc(cpu);
//……
}
rcu_qsctr_inc()代码如下:
C++
static inline void rcu_qsctr_inc(int cpu) { struct rcu_data *rdp = &per_cpu(rcu_data, cpu); rdp->passed_quiesc = 1; }
1
2
3
4
5
static inline void rcu_qsctr_inc(int cpu)
{
struct rcu_data *rdp = &per_cpu(rcu_data, cpu);
rdp->passed_quiesc = 1;
}
该函数将对应CPU上的rcu_data的passed_quiesc成员设为了1。或许你现已发现了,这个进程就标识该CPU经过了一次quiescent state,和之前在软中止的初始化为0相照应。
几种RCU状况剖析
1.假设CPU 1上有进程调用rcu_read_lock进入临界区,之后退出来,产生了进程切换,新进程又经过rcu_read_lock进入临界区.由于RCU软中止中只判别一次上下文切换,因而,在调用回调函数的时分,依然有进程处于RCU的读临界区,这样会不会有问题呢?
这样是不会有问题的.仍是上面的比如:
C++
spin_lock(&foo_mutex); old_fp = gbl_foo; *new_fp = *old_fp; new_fp->a = new_a; rcu_assign_pointer(gbl_foo, new_fp); spin_unlock(&foo_mutex); synchronize_rcu(); kfree(old_fp);
1
2
3
4
5
6
7
8
spin_lock(&foo_mutex);
old_fp = gbl_foo;
*new_fp = *old_fp;
new_fp->a = new_a;
rcu_assign_pointer(gbl_foo, new_fp);
spin_unlock(&foo_mutex);
synchronize_rcu();
kfree(old_fp);
运用synchronize_rcu ()只是为了等候持有old_fd(也便是调用rcu_assign_pointer ()更新之前的gbl_foo)的进程退出.而不需求等候一切的读者悉数退出.这是由于,在rcu_assign_pointer ()之后的读取取得的保护指针,现已是更新好的新值了.
2. 假设一个CPU接连调用synchronize_rcu()或许call_rcu()它们会有什么影响呢?
假设当时有恳求在等候,就会新请提交的回调函数挂到taillist上,一向到前一个等候完结,再将taillist的数据移到curlist,并敞开一个新的等候,因而,也便是说,在前一个等候期间提交的恳求,都会放到一同处理.也便是说,他们会一起等候一切CPU切换完结.
举例阐明如下:
带bh的RCU API
在上面的代码剖析的时分,常常看到带有bh的RCU代码.现在来看一下这些带bh的RCU是什么样的。
C++
#define rcu_read_lock_bh() __rcu_read_lock_bh() #define rcu_read_unlock_bh() __rcu_read_unlock_bh() #define __rcu_read_lock_bh() do { local_bh_disable(); __acquire(RCU_BH); rcu_read_acquire(); }while (0) #define __rcu_read_unlock_bh() do { rcu_read_release(); __release(RCU_BH); local_bh_enable(); } while (0)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
#define rcu_read_lock_bh() __rcu_read_lock_bh()
#define rcu_read_unlock_bh() __rcu_read_unlock_bh()
#define __rcu_read_lock_bh()
do {
local_bh_disable();
__acquire(RCU_BH);
rcu_read_acquire();
}while (0)
#define __rcu_read_unlock_bh()
do {
rcu_read_release();
__release(RCU_BH);
local_bh_enable();
} while (0)
依据上面的剖析:bh RCU跟一般的RCU比较不同的是,一般RCU是制止内核抢占,而bh RCU是制止下半部.
其实,带bh的RCU一般在软中止运用,不过核算quiescent state并不是产生一次上下文切换。而是产生一次softirq.咱们在后边的剖析中可得到印证.
lcall_rcu_bh()
C++
void call_rcu_bh(struct rcu_head *head, void (*func)(struct rcu_head *rcu)) { unsigned long flags; struct rcu_data *rdp; head->func = func; head->next = NULL; local_irq_save(flags); rdp = &__get_cpu_var(rcu_bh_data); *rdp->nxttail = head; rdp->nxttail = &head->next; if (unlikely(++rdp->qlen > qhimark)) { rdp->blimit = INT_MAX; force_quiescent_state(rdp, &rcu_bh_ctrlblk); } local_irq_restore(flags); }
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
void call_rcu_bh(struct rcu_head *head, void (*func)(struct rcu_head *rcu))
{
unsigned long flags;
struct rcu_data *rdp;
head->func = func;
head->next = NULL;
local_irq_save(flags);
rdp = &__get_cpu_var(rcu_bh_data);
*rdp->nxttail = head;
rdp->nxttail = &head->next;
if (unlikely(++rdp->qlen > qhimark)) {
rdp->blimit = INT_MAX;
force_quiescent_state(rdp, &rcu_bh_ctrlblk);
}
local_irq_restore(flags);
}
它跟call_rcu()不相同的是,rcu是取per_cpu变量rcu__data和大局变量rcu_ctrlblk.而bh RCU是取rcu_bh_data,rcu_bh_ctrlblk.他们的类型都是相同的,这样做只是为了区别BH和一般RCU的等候.
关于rcu_bh_qsctr_inc
C++
static inline void rcu_bh_qsctr_inc(int cpu) { struct rcu_data *rdp = &per_cpu(rcu_bh_data, cpu); rdp->passed_quiesc = 1; }
1
2
3
4
5
static inline void rcu_bh_qsctr_inc(int cpu)
{
struct rcu_data *rdp = &per_cpu(rcu_bh_data, cpu);
rdp->passed_quiesc = 1;
}
它跟rcu_qsctr_inc()机同,也是更改对应成员.所不同的是,调用rcu_bh_qsctr_inc()的当地产生了改变.
C++
asmlinkage void __do_softirq(void) { //…… do { if (pending & 1) { h->action(h); rcu_bh_qsctr_inc(cpu); } h++; pending >>= 1; } while (pending); //…… }
1
2
3
4
5
6
7
8
9
10
11
12
13
asmlinkage void __do_softirq(void)
{
//……
do {
if (pending & 1) {
h->action(h);
rcu_bh_qsctr_inc(cpu);
}
h++;
pending >>= 1;
} while (pending);
//……
}
也便是说,在产生软中止的时分,才会以为是经过了一次quiescent state.
RCU链表操作
为了操作链表,在include/linux/rculist.h有一套专门的RCU API。如:list_entry_rcu、list_add_rcu、list_del_rcu、list_for_each_entry_rcu等。即对一切kernel 的list的操作都有一个对应的RCU操作。那么这些操作和原始的list操作有哪些不同呢?咱们先比照几个看下。
llist_entry_rcu
C++
#define list_entry_rcu(ptr, type, member) \container_of(rcu_dereference(ptr), type, member)#define list_entry(ptr, type, member) \container_of(ptr, type, member)
1
2
3
4
#define list_entry_rcu(ptr, type, member) \
container_of(rcu_dereference(ptr), type, member)
#define list_entry(ptr, type, member) \
container_of(ptr, type, member)
l__list_for_each_rcu
C++
#define __list_for_each_rcu(pos, head) \for (pos = rcu_dereference((head)->next); \pos != (head); \pos = rcu_dereference(pos->next))#define __list_for_each(pos, head) \for (pos = (head)->next; pos != (head); pos = pos->next)
1
2
3
4
5
6
#define __list_for_each_rcu(pos, head) \
for (pos = rcu_dereference((head)->next); \
pos != (head); \
pos = rcu_dereference(pos->next))
#define __list_for_each(pos, head) \
for (pos = (head)->next; pos != (head); pos = pos->next)
从__list_for_each_rcu和list_entry_rcu的完结能够看出,其将指针的获取替换为运用rcu_dereference。
llist_replace_rcu
C++
static inline void list_replace_rcu(struct list_head *old,struct list_head *new){new->next = old->next;new->prev = old->prev;rcu_assign_pointer(new->prev->next, new);new->next->prev = new;old->prev = LIST_POISON2;}static inline void list_replace(struct list_head *old,struct list_head *new){new->next = old->next;new->next->prev = new;new->prev = old->prev;new->prev->next = new;}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
static inline void list_replace_rcu(struct list_head *old,
struct list_head *new)
{
new->next = old->next;
new->prev = old->prev;
rcu_assign_pointer(new->prev->next, new);
new->next->prev = new;
old->prev = LIST_POISON2;
}
static inline void list_replace(struct list_head *old,
struct list_head *new)
{
new->next = old->next;
new->next->prev = new;
new->prev = old->prev;
new->prev->next = new;
}
从list_replace_rcu的完结能够看出,RCU API的完结将指针的赋值替换为rcu_assign_pointer。
llist_del_rcu
C++
static inline void list_del_rcu(struct list_head *entry){__list_del(entry->prev, entry->next);entry->prev = LIST_POISON2;}static inline void list_del(struct list_head *entry){__list_del(entry->prev, entry->next);entry->next = LIST_POISON1;entry->prev = LIST_POISON2;}
1
2
3
4
5
6
7
8
9
10
11
static inline void list_del_rcu(struct list_head *entry)
{
__list_del(entry->prev, entry->next);
entry->prev = LIST_POISON2;
}
static inline void list_del(struct list_head *entry)
{
__list_del(entry->prev, entry->next);
entry->next = LIST_POISON1;
entry->prev = LIST_POISON2;
}
从list_del_rcu的完结,能够看出RCU API的完结没有将删去项的next指针置为无效。这样完结是为了避免删去节点时,读者还在遍历该节点。
RCU链表API运用
下面看下RCU list API的几个运用示例。
只要添加和删去的链表操作
在这种运用状况下,绝大部分是对链表的遍历,即读操作,而很少呈现的写操作只要添加或删去链表项,并没有对链表项的修正操作,这种状况运用RCU十分简略,从rwlock转化成RCU十分天然。路由表的保护便是这种状况的典型运用,对路由表的操作,绝大部分是路由表查询,而对路由表的写操作也只是是添加或删去,因而运用RCU替换本来的rwlock水到渠成。体系调用审计也是这样的状况。
这是一段运用rwlock的体系调用审计部分的读端代码:
C++
static enum audit_state audit_filter_task(struct task_struct *tsk) { struct audit_entry *e; enum audit_state state; read_lock(&auditsc_lock); /* Note: audit_netlink_sem held by caller. */ list_for_each_entry(e, &audit_tsklist, list) { if (audit_filter_rules(tsk, &e->rule, NULL, &state)) { read_unlock(&auditsc_lock); return state; } } read_unlock(&auditsc_lock); return AUDIT_BUILD_CONTEXT; }
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
static enum audit_state audit_filter_task(struct task_struct *tsk)
{
struct audit_entry *e;
enum audit_state state;
read_lock(&auditsc_lock);
/* Note: audit_netlink_sem held by caller. */
list_for_each_entry(e, &audit_tsklist, list) {
if (audit_filter_rules(tsk, &e->rule, NULL, &state)) {
read_unlock(&auditsc_lock);
return state;
}
}
read_unlock(&auditsc_lock);
return AUDIT_BUILD_CONTEXT;
}
运用RCU后将变成:
C++
static enum audit_state audit_filter_task(struct task_struct *tsk) { struct audit_entry *e; enum audit_state state; rcu_read_lock(); /* Note: audit_netlink_sem held by caller. */ list_for_each_entry_rcu(e, &audit_tsklist, list) { if (audit_filter_rules(tsk, &e->rule, NULL, &state)) { rcu_read_unlock(); return state; } } rcu_read_unlock(); return AUDIT_BUILD_CONTEXT; }
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
static enum audit_state audit_filter_task(struct task_struct *tsk)
{
struct audit_entry *e;
enum audit_state state;
rcu_read_lock();
/* Note: audit_netlink_sem held by caller. */
list_for_each_entry_rcu(e, &audit_tsklist, list) {
if (audit_filter_rules(tsk, &e->rule, NULL, &state)) {
rcu_read_unlock();
return state;
}
}
rcu_read_unlock();
return AUDIT_BUILD_CONTEXT;
}
这种转化十分直接,运用rcu_read_lock和rcu_read_unlock别离替换read_lock和read_unlock,链表遍历函数运用_rcu版别替换就能够了。
运用rwlock的写端代码:
C++
static inline int audit_del_rule(struct audit_rule *rule, struct list_head *list) { struct audit_entry *e; write_lock(&auditsc_lock); list_for_each_entry(e, list, list) { if (!audit_compare_rule(rule, &e->rule)) { list_del(&e->list); write_unlock(&auditsc_lock); return 0; } } write_unlock(&auditsc_lock); return -EFAULT; /* No matching rule */ } static inline int audit_add_rule(struct audit_entry *entry, struct list_head *list) { write_lock(&auditsc_lock); if (entry->rule.flags & AUDIT_PREPEND) { entry->rule.flags &= ~AUDIT_PREPEND; list_add(&entry->list, list); } else { list_add_tail(&entry->list, list); } write_unlock(&auditsc_lock); return 0; }
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
static inline int audit_del_rule(struct audit_rule *rule,
struct list_head *list)
{
struct audit_entry *e;
write_lock(&auditsc_lock);
list_for_each_entry(e, list, list) {
if (!audit_compare_rule(rule, &e->rule)) {
list_del(&e->list);
write_unlock(&auditsc_lock);
return 0;
}
}
write_unlock(&auditsc_lock);
return -EFAULT; /* No matching rule */
}
static inline int audit_add_rule(struct audit_entry *entry,
struct list_head *list)
{
write_lock(&auditsc_lock);
if (entry->rule.flags & AUDIT_PREPEND) {
entry->rule.flags &= ~AUDIT_PREPEND;
list_add(&entry->list, list);
} else {
list_add_tail(&entry->list, list);
}
write_unlock(&auditsc_lock);
return 0;
}
运用RCU后写端代码变成为:
C++
static inline int audit_del_rule(struct audit_rule *rule, struct list_head *list) { struct audit_entry *e; /* Do not use the _rcu iterator here, since this is the only * deletion routine. */ list_for_each_entry(e, list, list) { if (!audit_compare_rule(rule, &e->rule)) { list_del_rcu(&e->list); call_rcu(&e->rcu, audit_free_rule, e); return 0; } } return -EFAULT; /* No matching rule */ } static inline int audit_add_rule(struct audit_entry *entry, struct list_head *list) { if (entry->rule.flags & AUDIT_PREPEND) { entry->rule.flags &= ~AUDIT_PREPEND; list_add_rcu(&entry->list, list); } else { list_add_tail_rcu(&entry->list, list); } return 0; }
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
static inline int audit_del_rule(struct audit_rule *rule,
struct list_head *list)
{
struct audit_entry *e;
/* Do not use the _rcu iterator here, since this is the only
* deletion routine. */
list_for_each_entry(e, list, list) {
if (!audit_compare_rule(rule, &e->rule)) {
list_del_rcu(&e->list);
call_rcu(&e->rcu, audit_free_rule, e);
return 0;
}
}
return -EFAULT; /* No matching rule */
}
static inline int audit_add_rule(struct audit_entry *entry,
struct list_head *list)
{
if (entry->rule.flags & AUDIT_PREPEND) {
entry->rule.flags &= ~AUDIT_PREPEND;
list_add_rcu(&entry->list, list);
} else {
list_add_tail_rcu(&entry->list, list);
}
return 0;
}
关于链表删去操作,list_del替换为list_del_rcu和call_rcu,这是由于被删去的链表项或许还在被其他读者引证,所以不能当即删去,有必要比及一切读者阅历一个quiescent state才能够删去。其他,list_for_each_entry并没有被替换为list_for_each_entry_rcu,这是由于,只要一个写者在做链表删去操作,因而没有必要运用_rcu版别。
通常状况下,write_lock和write_unlock应当别离替换成spin_lock和spin_unlock,可是关于只是对链表进行添加和删去操作并且只要一个写者的写端,在运用了_rcu版其他链表操作API后,rwlock能够彻底消除,不需求spinlock来同步读者的拜访。关于上面的比如,由于现已有audit_netlink_sem被调用者坚持,所以spinlock就没有必要了。
这种状况答应修正成果拖延必定时刻才可见,并且写者对链表只是做添加和删去操作,所以转化成运用RCU十分简略。
写端需求对链表条目进行修正操作
假设写者需求对链表条目进行修正,那么就需求首要仿制要修正的条目,然后修正条意图仿制,等修正结束后,再运用条目仿制替代要修正的条目,要修正条目将被在阅历一个grace period后安全删去。
关于体系调用审计代码,并没有这种状况。这儿假定有修正的状况,那么运用rwlock的修正代码应当如下:
C++
static inline int audit_upd_rule(struct audit_rule *rule, struct list_head *list, __u32 newaction, __u32 newfield_count) { struct audit_entry *e; struct audit_newentry *ne; write_lock(&auditsc_lock); /* Note: audit_netlink_sem held by caller. */ list_for_each_entry(e, list, list) { if (!audit_compare_rule(rule, &e->rule)) { e->rule.action = newaction; e->rule.file_count = newfield_count; write_unlock(&auditsc_lock); return 0; } } write_unlock(&auditsc_lock); return -EFAULT; /* No matching rule */ }
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
static inline int audit_upd_rule(struct audit_rule *rule,
struct list_head *list,
__u32 newaction,
__u32 newfield_count)
{
struct audit_entry *e;
struct audit_newentry *ne;
write_lock(&auditsc_lock);
/* Note: audit_netlink_sem held by caller. */
list_for_each_entry(e, list, list) {
if (!audit_compare_rule(rule, &e->rule)) {
e->rule.action = newaction;
e->rule.file_count = newfield_count;
write_unlock(&auditsc_lock);
return 0;
}
}
write_unlock(&auditsc_lock);
return -EFAULT; /* No matching rule */
}
假设运用RCU,修正代码应当为;
C++
static inline int audit_upd_rule(struct audit_rule *rule, struct list_head *list, __u32 newaction, __u32 newfield_count) { struct audit_entry *e; struct audit_newentry *ne; list_for_each_entry(e, list, list) { if (!audit_compare_rule(rule, &e->rule)) { ne = kmalloc(sizeof(*entry), GFP_ATOMIC); if (ne == NULL) return -ENOMEM; audit_copy_rule(&ne->rule, &e->rule); ne->rule.action = newaction; ne->rule.file_count = newfield_count; list_replace_rcu(e, ne); call_rcu(&e->rcu, audit_free_rule, e); return 0; } } return -EFAULT; /* No matching rule */ }
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
static inline int audit_upd_rule(struct audit_rule *rule,
struct list_head *list,
__u32 newaction,
__u32 newfield_count)
{
struct audit_entry *e;
struct audit_newentry *ne;
list_for_each_entry(e, list, list) {
if (!audit_compare_rule(rule, &e->rule)) {
ne = kmalloc(sizeof(*entry), GFP_ATOMIC);
if (ne == NULL)
return -ENOMEM;
audit_copy_rule(&ne->rule, &e->rule);
ne->rule.action = newaction;
ne->rule.file_count = newfield_count;
list_replace_rcu(e, ne);
call_rcu(&e->rcu, audit_free_rule, e);
return 0;
}
}
return -EFAULT; /* No matching rule */
}
修正操作当即可见
前面两种状况,读者能够忍受修正能够在一段时刻后看到,也就说读者在修正后某一时刻段内,依然看到的是本来的数据。在许多状况下,读者不能忍受看到旧的数据,这种状况下,需求运用一些新办法,如System V IPC,它在每一个链表条目中添加了一个deleted字段,符号该字段是否删去,假设删去了,就设置为真,不然设置为假,当代码在遍历链表时,核对每一个条意图deleted字段,假设为真,就以为它是不存在的。
仍是以体系调用审计代码为例,假设它不能忍受旧数据,那么,读端代码应该修正为:
C++
static enum audit_state audit_filter_task(struct task_struct *tsk) { struct audit_entry *e; enum audit_state state; rcu_read_lock(); list_for_each_entry_rcu(e, &audit_tsklist, list) { if (audit_filter_rules(tsk, &e->rule, NULL, &state)) { spin_lock(&e->lock); if (e->deleted) { spin_unlock(&e->lock); rcu_read_unlock(); return AUDIT_BUILD_CONTEXT; } rcu_read_unlock(); return state; } } rcu_read_unlock(); return AUDIT_BUILD_CONTEXT; }
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
static enum audit_state audit_filter_task(struct task_struct *tsk)
{
struct audit_entry *e;
enum audit_state state;
rcu_read_lock();
list_for_each_entry_rcu(e, &audit_tsklist, list) {
if (audit_filter_rules(tsk, &e->rule, NULL, &state)) {
spin_lock(&e->lock);
if (e->deleted) {
spin_unlock(&e->lock);
rcu_read_unlock();
return AUDIT_BUILD_CONTEXT;
}
rcu_read_unlock();
return state;
}
}
rcu_read_unlock();
return AUDIT_BUILD_CONTEXT;
}
留意,关于这种状况,每一个链表条目都需求一个spinlock保护,由于删去操作将修正条意图deleted标志。此外,该函数假设查找到条目,回来时应当坚持该条意图锁。
写端的删去操作将变成:
C++
static inline int audit_del_rule(struct audit_rule *rule, struct list_head *list) { struct audit_entry *e; /* Do not use the _rcu iterator here, since this is the only * deletion routine. */ list_for_each_entry(e, list, list) { if (!audit_compare_rule(rule, &e->rule)) { spin_lock(&e->lock); list_del_rcu(&e->list); e->deleted = 1; spin_unlock(&e->lock); call_rcu(&e->rcu, audit_free_rule, e); return 0; } } return -EFAULT; /* No matching rule */ }
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
static inline int audit_del_rule(struct audit_rule *rule,
struct list_head *list)
{
struct audit_entry *e;
/* Do not use the _rcu iterator here, since this is the only
* deletion routine. */
list_for_each_entry(e, list, list) {
if (!audit_compare_rule(rule, &e->rule)) {
spin_lock(&e->lock);
list_del_rcu(&e->list);
e->deleted = 1;
spin_unlock(&e->lock);
call_rcu(&e->rcu, audit_free_rule, e);
return 0;
}
}
return -EFAULT; /* No matching rule */
}
删去条目时,需求符号该条目为已删去。这样读者就能够经过该标志当即得知条目是否现已删去。
小结
RCU是2.6内核引进的新的锁机制,在绝大部分为读而只要很少部分为写的状况下,它是十分高效的,因而在路由表保护、体系调用审计、SELinux的AVC、dcache和IPC等代码部分中,运用它来替代rwlock来取得更高的功能。可是,它也有缺点,拖延的删去或开释将占用一些内存,尤其是对嵌入式体系,这或许是十分贵重的内存开支。此外,写者的开支比较大,尤其是关于那些无法忍受旧数据的状况以及不只一个写者的状况,写者需求spinlock或其他的锁机制来与其他写者同步。