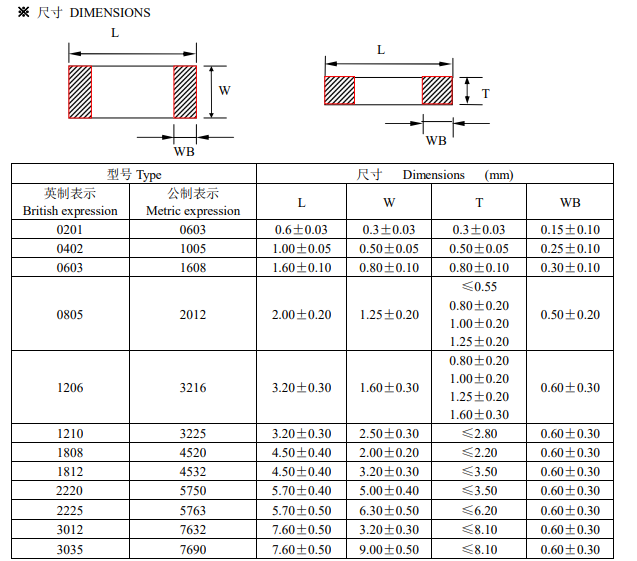
阻抗操控
阻抗操控(eImpedance Controling),线路板中的导体中会有各种信号的传递,为进步其传输速率而有必要进步其频率,线路自身若因蚀刻,叠层厚度,导线宽度等不同要素,将会形成阻抗值得改变,使其信号失真。故在高速线路板上的导体,其阻抗值应操控在某一规模之内,称为“阻抗操控”。
PCB 迹线的阻抗将由其感应和电容性电感、电阻和电导系数确认。影响PCB走线的阻抗的要素首要有: 铜线的宽度、铜线的厚度、介质的介电常数、介质的厚度、焊盘的厚度、地线的途径、走线周边的走线等。PCB 阻抗的规模是 25 至120 欧姆。
在实践情况下,PCB 传输线路一般由一个导线迹线、一个或多个参阅层和绝缘原料组成。迹线和板层构成了操控阻抗。PCB 将常常选用多层结构,而且操控阻抗也可以选用各种办法来构建。可是,不管运用什么办法,阻抗值都将由其物理结构和绝缘材料的电子特性决议:
信号迹线的宽度和厚度 迹线两边的内核或预填原料的高度 迹线和板层的装备 内核和预填原料的绝缘常数
PCB传输线首要有两种方式:微带线(Microstrip)与带状线(Stripline)。
阻抗操控的特色
在完结力操控时,阻抗操控、力/方位混合操控、显式力控办法,各有其共同的特色。力/方位操控办法是根据将结尾执行器的坐标空间按其是否被环境束缚而分为方位子空间和力子空间,力/方位操控办法经过操控结尾执行器在方位子空间的方位和在力子空间的力来完结习惯操控,这种办法的长处是可以直接操控结尾执行器和环境间的彼此作用力,这在有些场合是很重要的。其缺陷是需求许多使命规划以及需求在力控和方位操控之间切换。
而阻抗操控是靠调理结尾执行器的方位和触摸力之间的动态联系来完结习惯操控的。这种办法为避碰、有束缚和无束缚运动供给了一种一致的办法。其长处是需求很少离线使命规划,对扰动和不确认性有很好的鲁棒性。能完结体系由无束缚到有束缚运动的安稳转化。因而阻抗操控被以为更适合完结安装作业。其缺陷是在实践中难于准确得到结尾执行器的参阅轨道和环境的方位、刚度。然后既无法准确完结方位操控又无法准确完结力操控。近年来提出了根据阻抗操控的力盯梢算法,文献[2]经过调理参阅轨道Xr给出了存在环境不确认性时的力盯梢阻抗操控算法。
阻抗操控与显式力控的比较,证明了在刚性环境,二阶阻抗操控和有前馈的份额显式力控的等价性。阐明阻抗操控是较显式力控更一般的办法,阻抗操控的首要特性是使机器人与环境的交互不受触摸的物体影响,而力控却易受触摸物体的影响。
阻抗操控的完结办法
在阻抗操控的前期,运用了固定增益的PD操控,这种办法完结简略,但在机器人位形、速度改变时无法坚持抱负阻抗。经过学者们的尽力,开展了多种阻抗操控办法,总的看来有两类完结阻抗操控的办法,一类是根据动力学模型的阻抗操控办法,另一类是根据方位的阻抗操控办法。
根据动力学模型的阻抗操控办法
根据动力学模型的操控办法是运用最为广泛的办法。这种办法检测方位和触摸力,运用机器人动力学模型作为前馈输入,所以这种操控战略依赖于动力学模型的准确性。同根据方位的阻抗操控办法比较,这种办法能供给为减小触摸力所需的较小的抱负的阻尼和刚度。根据方位的阻抗操控办法一般所能供给只能是大的抱负的阻尼和刚度,这不利于减小机器人和束缚之间的触摸力。
在根据动力学模型的操控办法中,首要提出根据动力学模型的操控办法,该办法在用核算力矩法完结抱负阻抗时,需求知道机器人动力学模型。后来的学者进一步开展了根据动力学模型的操控办法,运用恰当选取的状况反应和前馈来完结鲁棒阻抗操控,提出了根据准确机器人动力学模型的阻抗操控办法,其长处是不需检测力和避免了高增益。提出了把阻抗操控和力/方位混合操控器结合在一起混合阻抗操控器。引进方针阻抗参阅轨道,将自习惯办法直接运用到阻抗操控办法,不要求准确的动力学模型,缺陷是因为丈量噪音的影响,由自习惯办法难以得到满足精度的阻抗操控参数。运用鲁棒性操控来战胜模型的不确认性,但需求很多的核算和很大的增益,这在实践中受到约束。
跟着人工智能研讨的开展,运用智能操控的研讨成果,开展了多种操控战略来进步根据动力学模型的阻抗操控办法的操控功能,使根据动力学模型的操控器在存在动力学模型的不确认性时也能到达好的操控作用。
提出学习阻抗操控办法,给定方针阻抗,学习操控器能经过学习,使操作机可以跟着操作的重复进行使闭环呼应到达方针阻抗。其缺陷是假定每次操作取相同的初始方位和速度,且假定无动力学动摇和丈量噪声。给出具有鲁棒性的学习阻抗操控办法,使阻抗差错在存在动力学动摇和丈量噪声初始方位差错的情况下收敛到趋于零的规模内。提出用神经网络来补偿机器人动力学和环境的不确认,经过练习使神经网络收敛然后完结阻抗操控函数。
根据方位的阻抗操控办法
根据方位的阻抗操控办法在施行时是经过盯梢抱负阻抗模型的方位来完结的。这种办法要检测方位、速度和触摸力,将检测到的触摸力施加到抱负阻抗模型,然后可以获得抱负方位矢量,运用内部方位操控环来盯梢这个抱负方位矢量。这种办法不依赖于动力学模型。因为方位操控器的大增益会带来关节的高刚度,这种办法的缺陷是当机器人的实践方位和模型抱负方位矢量不一起将带来大的阻抗差错,然后将这种办法约束在简略使命中。
为工业机器人规划了一个根据方位的阻抗操控来进步工业机器人的功能。运用了根据方位的阻抗操控来完结力盯梢。在内环运用方位反应来进步鲁棒性,在外环运用方位反应来盯梢抱负阻抗来进步根据方位的阻抗操控器的功能。运用了含糊补偿器来发生方位补偿到达减小在力控方向的超谐和颤动。
在阻抗操控的安稳性方面,中体系评论了根本的根据动力学模型的阻抗操控办法和根据方位的阻抗操控办法的安稳性质,获得了阻抗操控的参数安稳性鸿沟。