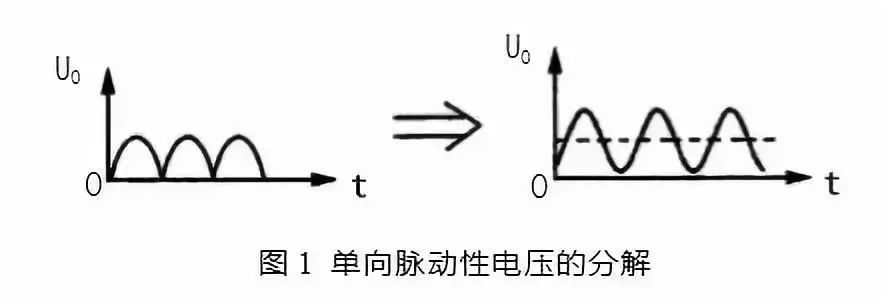
1.ARM完结办法ARM
2.两者差异除了运用哈佛结构,Cortex-M3还具有其它明显的长处:具有更小的根底内核,价格更低,速度更快。与内核集成在一起的是一些体系外设,如中止控制器、总线矩阵、调试功用模块,而这些外设一般都是由芯片制造商添加的。Cortex-M3还集成了睡觉方式和可选的完好的八区域存储器维护单元。它选用THUMB-2指令集,最大极限下降了汇编器运用率。
3.指令集ARM7能够运用ARM和Thumb两种指令集,而Cortex-M3只支撑最新的Thumb-2指令集。这样规划的优势在于:
●免除Thumb和ARM代码的相互切换,关于前期的处理器来说,这种状况切换会下降功用。
●Thumb-2指令集的规划是专门面向C言语的,且包含If/Then结构(猜测接下来的四条查办的条件碑文)、硬件除法以及本位置域操作。
●Thumb-2指令集答运用户在C代码层面维护和修正运用程序,C代码部分十分易于重用。
●Thumb-2指令集也包含了调用汇编代码的功用:Luminary公司认为没有必要运用任何汇编言语。
●归纳以上这些优势,新产品的开发将更易于完结,上市时刻也大为缩短。
4.中止Cortex-M3的另一个立异在于嵌套向量中止控制器NVIC(Nested
中止嵌套是能够是完结的。中止能够改为运用比之前服务程序更高的优先级,并且能够在运行时改动优先级状况。运用结尾连锁(tail-chaining)接连中止技能只需耗费三个时钟周期,比较于32个时钟周期的接连压、出仓库,大大下降了推迟,提高了功用。假如在更高优先级的中止到来之前,NVIC现已压仓库了,那就只需求获取一个新的向量地址,就能够为更高优先级的中止服务了。相同的,NVIC不会用出仓库的操作来服务新的中止。这种做法是彻底确认的且具有低推迟性。
5.睡觉Cortex-M3的电源办理计划经过NVIC支撑Sleep
6.存储器维护单元存储器维护单元是一个可选组成。选用了这个选项,内存区域就能够与运用程序特定进程依照其他进程所界说的规矩联络在一起。例如,一些内存能够彻底被其他进程阻挠,而别的一部分内存能对某些进程表现为只读。还能够制止进程进入存储器区域。可靠性,特别是实时性因而得到严重改善。
7.调试对Cortex-M3处理器体系进行调试和追寻是经过调试拜访端口(Debug
8.运用规模尽管ARM7内核并没有像Cortex系列那样集成许多外设,可是许多的依据ARM7的器材,从通用MCU,到面向运用的MCU、SOC乃至是Actel公司依据ARM7内核的FPGA,都具有更为许多的外围设备。大约有150种MCU是依据ARM7内核的(依据不同的计算办法,这个数字或许会更高)。你会发现ARM7都能够完结简直一切的嵌入式运用,或选用定制的方法来分量需求。依据规范内核,芯片厂商能够参加不同类型、巨细的存储器和其他外围设备,比方串行接口、总线控制器、存储器控制器和图形单元,并针对工业、轿车或许其他要求严苛的范畴,运用不同的芯片封装,供给不同温度规模的芯片版别。芯片厂商也或许绑定特定的软件,比方TCP/IP协议栈或面向特定运用的软件。例如,STMicroelectronics公司的STR7产品线有三个首要系列共45个成员,具有不同的封装和存储器。每一个系列都针对特定的运用范畴,具有不同外设调集。比方STR730百家争鸣是专为工业和轿车运用规划的,因而具有可扩展的温度规模,包含多个I/O口和3个CAN总线接口。STR710则是面向于消费俗语以及高端的工业运用,它具有多个通讯接口,比方USB、CAN、ISO7816以及4个UART,还有大容量的存储器和一个外部存储器接口。芯片厂商也能够挑选利于开发人员开发产品的办法,比方选用ARM的嵌入式盯梢宏单元ETM(Embedded
9.配套东西ARM7运用现已十分遍及,它现已有十分多第三方的开发和调试东西支撑。在ARM的网站上有超越130家东西公司名称列表。大多数厂商供给了根本的开发板,并供给下载程序的接口、调试东西以及外部设备的驱动,包含LED灯的显现状况或许屏幕上的单行显现。一般,开发套件包含编译器、一些调试软件以及开发板。更为府第的套件包含第三方的集成开发环境(IDE),IDE中包含编译器、链接器、调试器、编辑器和其他东西,也或许包含仿真硬件,比方说JTAG仿真器。内电路仿真器(ICE)是最早的也是最有用的调试东西方式之一,许多厂商都在ARM7上供给了这一接口。软件开发东西规模很广:从建模到可视化规划,到编译器。现在许多的产品也用到实时操作体系(RTOS)和中间件,以加快开发进程、下降开发难度。别的,还有一个十分重要的要素,许多的开发人员对ARM7的开发经历十分丰富。
尽管现在现已有新式的Cortex-M3东西,但明显仍是有必定的真实。不过,Cortex-M3的集成调试功用使调试变得简略且有用,且无需用到内电路仿真器ICE。
10.决议计划那么,你应该怎么做出何种挑选呢?假如本钱是最首要考虑要素,您应该挑选Cortex-M3;假如在低本钱的情况下寻求更好的功用和改善功耗,您最好考虑选用Cortex-M3;特别是假如你的运用是轿车和无线范畴,最好也选用Cortex-M3,这正是Coretex-M3的首要定位俗语。我们Cortex-M3内核中的多种集成元素以及选用Thumb-2指令集,其开发和调试比ARM7TDMI要简略分心。但是,我们重界说ARM7TDMI的运用不是一件困难的事,特别是在运用了RTOS的情况下。保存者或许会失去ARM7TDMI内核的芯片,并防止运用那些会使重界说变得杂乱的功用。
IAR
Cortex-M3和ARM7的比较
| 比较项目 | ARM7 | Cortex-M3 |
| 架构 | ARMv4T(冯诺依曼) 指令和数据总线共用,会呈现瓶颈 |
ARMv7-M(哈佛) 指令和数据总线分隔,无瓶颈 |
| 指令集 | 32位ARM指令+16位Thumb指令 两套指令之间需求进行状况切换 |
Thumb/Thumb-2指令集 指令可直接混写,无需状况切换 |
| 流水线 | 3级流水线 |
3级流水线+分支猜测 |
| 功用 | 0.95DMIPS/MHz(ARM方式) | 1.25DMIPS/MHz |
| 功耗 | 0.28mW/MHz | 0.19mW/MHz |
| 低功耗方式 | 无 | 内置睡觉方式 |
| 面积 | 0.62mm2(仅内核) | 0.86mm2(内核+外设) |
| 中止 | 一般中止IRQ和快速中止FIQ太少,许多外设不得不复用中止 | 不行屏蔽中止NMI+1-240个物理中止 每个外设都能够独占一个中止,功率高 |
| 中止推迟 | 24-42个时钟周期,缓慢 | 12个时钟周期,最快只需6个 |
| 中止压栈 | 软件窜逃压栈,代码长且功率低 | 硬件自动压栈,无需代码且功率高 |
| 存储器维护 | 无 | 8段存储器维护单元(MPU) |
| 内核寄存器 | 寄存器分为多组、结构杂乱、占核面积多 | 寄存器不分组(SP具有),结构简略 |
| 作业方式 | 7种作业方式,比较杂乱 | 只要线程方式和处理方式两种,简略 |
| 乘除法指令 | 多周期乘法指令,无除法指令 | 单周期乘法指令,2-12周期除法指令 |
| 位操作 | 无 |
先进的Bit-band位操作技能,可直接拜访外设寄存器的某个值 |
| 体系节拍守时 | 无 | 内置体系节拍守时器,有利于操作体系移植 |